The Dupuy Air Campaign Model
by Col. Joseph A. Bulger, Jr., USAF, Ret.
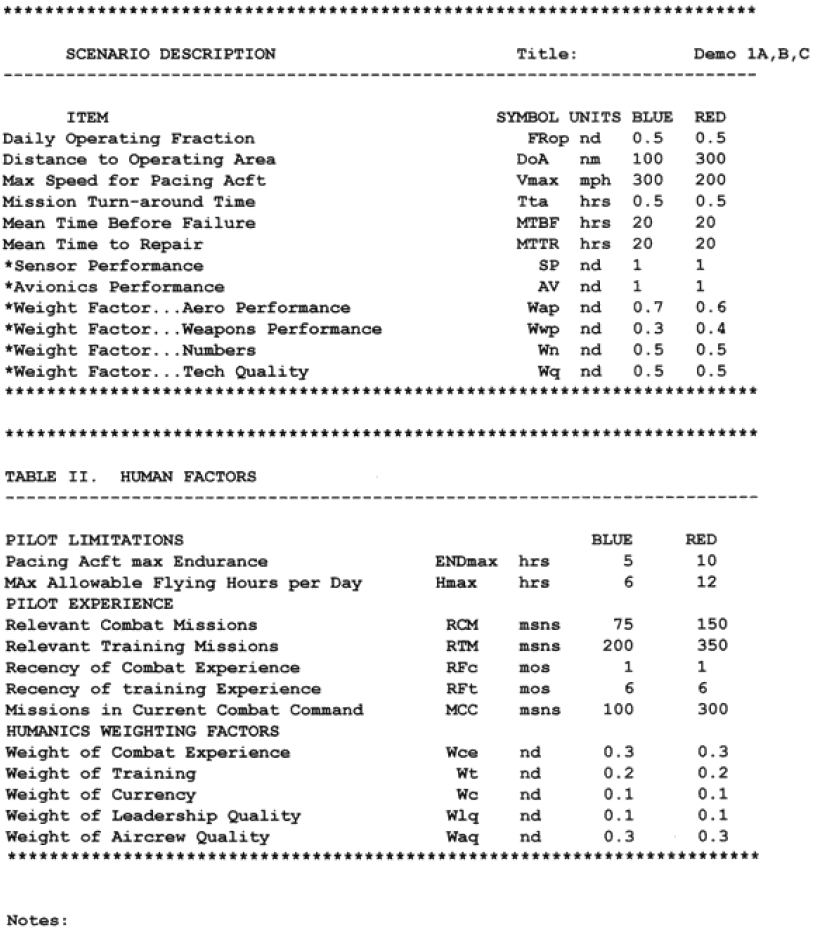
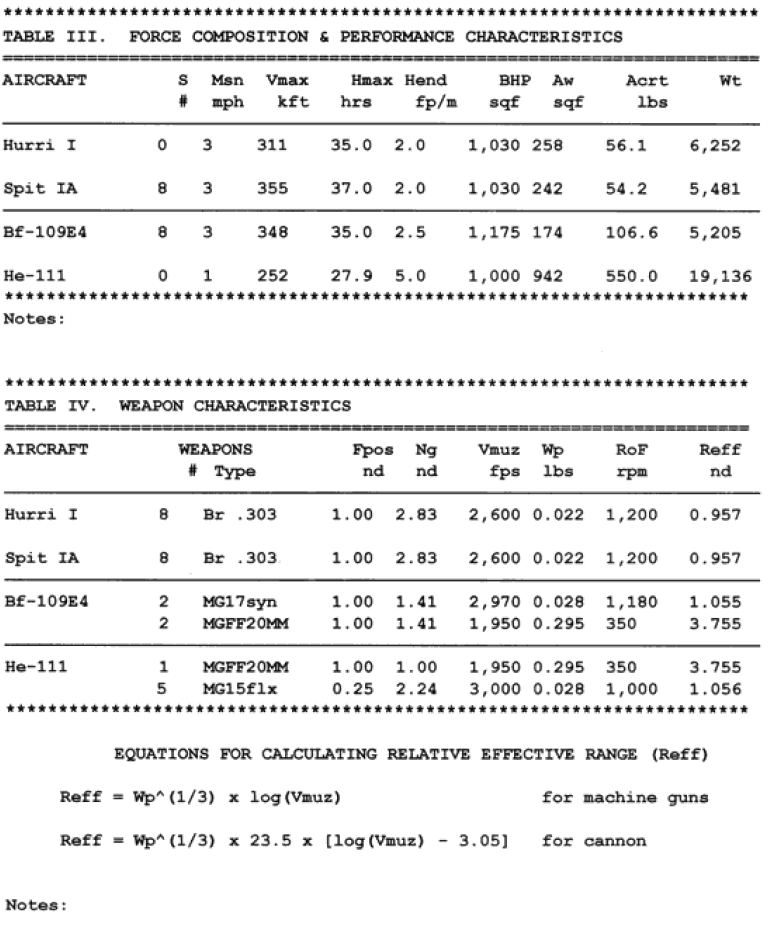
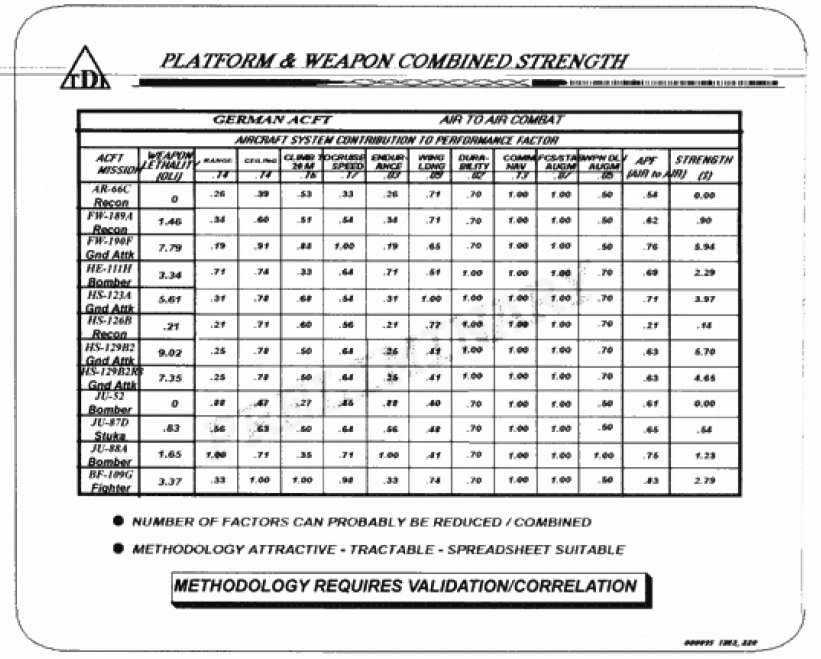
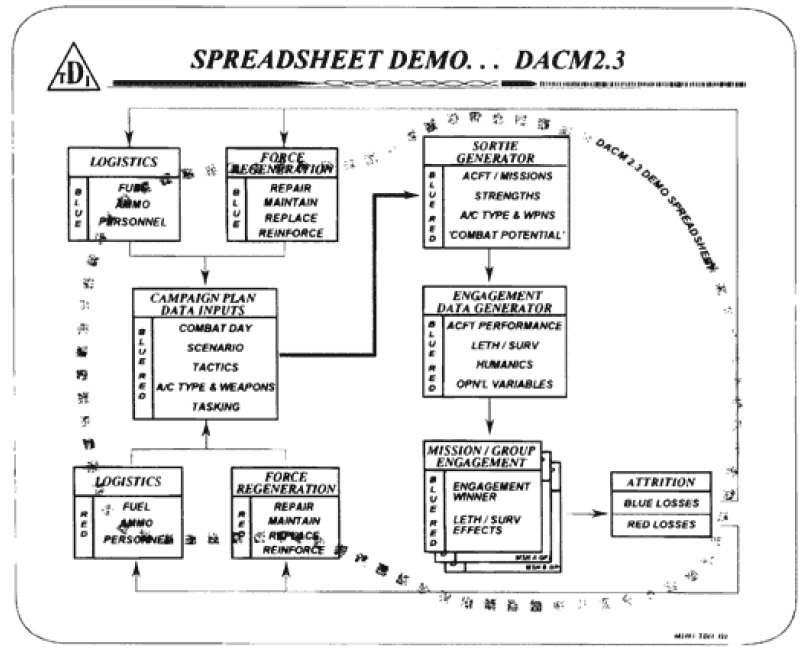
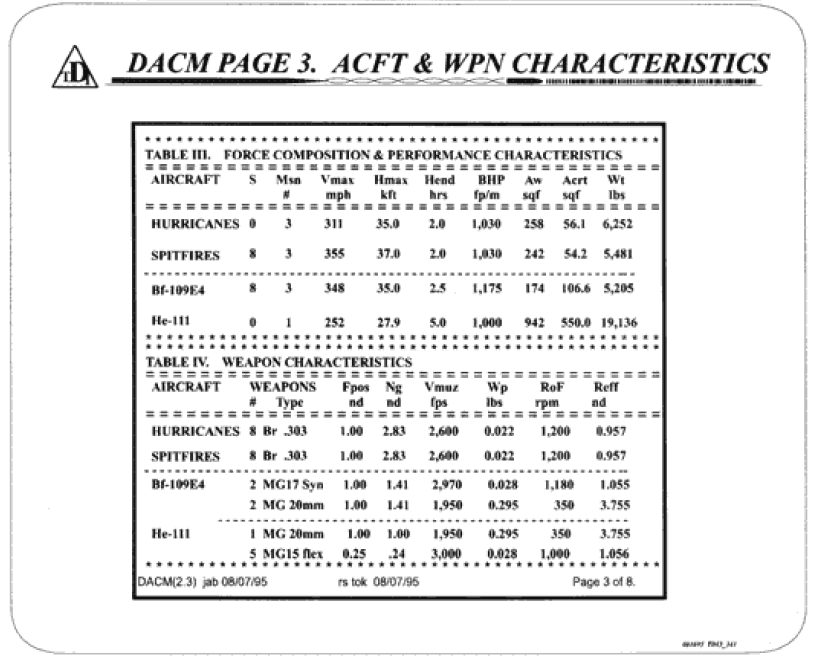
The Dupuy Institute, as part of the DACM [Dupuy Air Campaign Model], created a draft model in a spreadsheet format to show how such a model would calculate attrition. Below are the actual printouts of the “interim methodology demonstration,” which shows the types of inputs, outputs, and equations used for the DACM. The spreadsheet was created by Col. Bulger, while many of the formulae were the work of Robert Shaw.
Air Model Historical Data Study by Col. Joseph A. Bulger, Jr., USAF, Ret
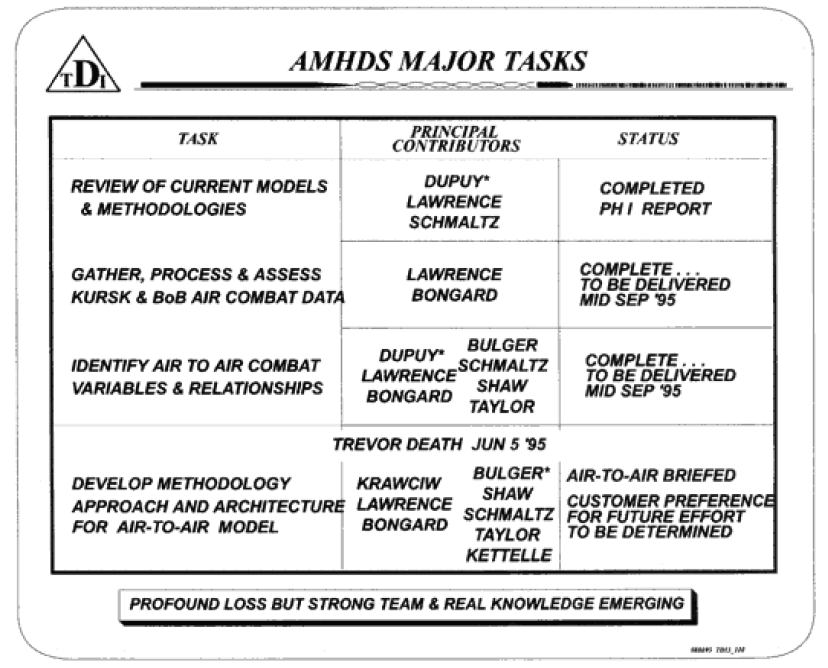
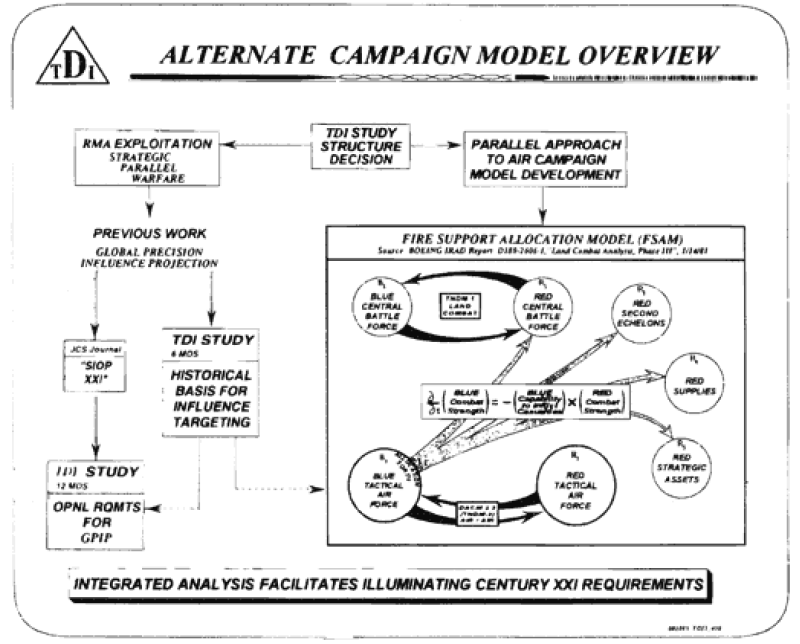
The Air Model Historical Study (AMHS) was designed to lead to the development of an air campaign model for use by the Air Command and Staff College (ACSC). This model, never completed, became known as the Dupuy Air Campaign Model (DACM). It was a team effort led by Trevor N. Dupuy and included the active participation of Lt. Col. Joseph Bulger, Gen. Nicholas Krawciw, Chris Lawrence, Dave Bongard, Robert Schmaltz, Robert Shaw, Dr. James Taylor, John Kettelle, Dr. George Daoust and Louis Zocchi, among others. After Dupuy’s death, I took over as the project manager.
At the first meeting of the team Dupuy assembled for the study, it became clear that this effort would be a serious challenge. In his own style, Dupuy was careful to provide essential guidance while, at the same time, cultivating a broad investigative approach to the unique demands of modeling for air combat. It would have been no surprise if the initial guidance established a focus on the analytical approach, level of aggregation, and overall philosophy of the QJM [Quantified Judgement Model] and TNDM [Tactical Numerical Deterministic Model]. It was clear that Trevor had no intention of steering the study into an air combat modeling methodology based directly on QJM/TNDM. To the contrary, he insisted on a rigorous derivation of the factors that would permit the final choice of model methodology.
At the time of Dupuy’s death in June 1995, the Air Model Historical Data Study had reached a point where a major decision was needed. The early months of the study had been devoted to developing a consensus among the TDI team members with respect to the factors that needed to be included in the model. The discussions tended to highlight three areas of particular interest—factors that had been included in models currently in use, the limitations of these models, and the need for new factors (and relationships) peculiar to the properties and dynamics of the air campaign. Team members formulated a family of relationships and factors, but the model architecture itself was not investigated beyond the surface considerations.
Despite substantial contributions from team members, including analytical demonstrations of selected factors and air combat relationships, no consensus had been achieved. On the contrary, there was a growing sense of need to abandon traditional modeling approaches in favor of a new application of the “Dupuy Method” based on a solid body of air combat data from WWII.
The Dupuy approach to modeling land combat relied heavily on the ratio of force strengths (largely determined by firepower as modified by other factors). After almost a year of investigations by the AMHDS team, it was beginning to appear that air combat differed in a fundamental way from ground combat. The essence of the difference is that in air combat, the outcome of the maneuver battle for platform position must be determined before the firepower relationships may be brought to bear on the battle outcome.
At the time of Dupuy’s death, it was apparent that if the study contract was to yield a meaningful product, an immediate choice of analysis thrust was required. Shortly prior to Dupuy’s death, I and other members of the TDI team recommended that we adopt the overall approach, level of aggregation, and analytical complexity that had characterized Dupuy’s models of land combat. We also agreed on the time-sequenced predominance of the maneuver phase of air combat. When I was asked to take the analytical lead for the contact in Dupuy’s absence, I was reasonably confident that there was overall agreement.
In view of the time available to prepare a deliverable product, it was decided to prepare a model using the air combat data we had been evaluating up to that point—June 1995. Fortunately, Robert Shaw had developed a set of preliminary analysis relationships that could be used in an initial assessment of the maneuver/firepower relationship. In view of the analytical, logistic, contractual, and time factors discussed, we decided to complete the contract effort based on the following analytical thrust:
The contract deliverable would be based on the maneuver/firepower analysis approach as currently formulated in Robert Shaw’s performance equations;
A spreadsheet formulation of outcomes for selected (Battle of Britain) engagements would be presented to the customer in August 1995;
To the extent practical, a working model would be provided to the customer with suggestions for further development.
During the following six weeks, the demonstration model was constructed. The model (programmed for a Lotus 1-2-3 style spreadsheet formulation) was developed, mechanized, and demonstrated to ACSC in August 1995. The final report was delivered in September of 1995.
The working model demonstrated to ACSC in August 1995 suggests the following observations:
A substantial contribution to the understanding of air combat modeling has been achieved.
While relationships developed in the Dupuy Air Combat Model (DACM) are not fully mature, they are analytically significant.
The approach embodied in DACM derives its authenticity from the famous “Dupuy Method” thus ensuring its strong correlations with actual combat data.
Although demonstrated only for air combat in the Battle of Britain, the methodology is fully capable of incorporating modem technology contributions to sensor, command and control, and firepower performance.
The knowledge base, fundamental performance relationships, and methodology contributions embodied in DACM are worthy of further exploration. They await only the expression of interest and a relatively modest investment to extend the analysis methodology into modem air combat and the engagements anticipated for the 21st Century.
One final observation seems appropriate. The DACM demonstration provided to ACSC in August 1995 should not be dismissed as a perhaps interesting, but largely simplistic approach to air combat modeling. It is a significant contribution to the understanding of air combat relationships that will prevail in the 21st Century. The Dupuy Institute is convinced that further development of DACM makes eminent good sense. An exploitation of the maneuver and firepower relationships already demonstrated in DACM will provide a valid basis for modeling air combat with modern technology sensors, control mechanisms, and weapons. It is appropriate to include the Dupuy name in the title of this latest in a series of distinguished combat models. Trevor would be pleased.
“If we maintain our faith in God, love of freedom, and superior global airpower, the future [of the US] looks good.” — U.S. Air Force General Curtis E. LeMay (Commander, U.S. Strategic Command, 1948-1957)
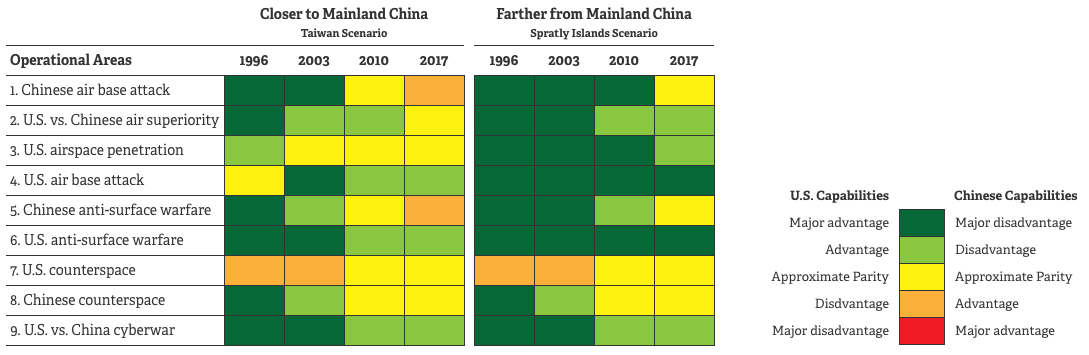
Curtis LeMay was involved in the formation of RAND Corporation after World War II. RAND created several models to measure the dynamics of the US-China military balance over time. Since 1996, this has been computed for two scenarios, differing by range from mainland China: one over Taiwan and the other over the Spratly Islands. The results of the model results for selected years can be seen in the graphic below.
The capabilities listed in the RAND study are interesting, notable in that the air superiority category, rough parity exists as of 2017. Also, the ability to attack air bases has given an advantage to the Chinese forces.
Investigating the methodology used does not yield any precise quantitative modeling examples, as would be expected in a rigorous academic effort, although there is some mention of statistics, simulation and historical examples.
The analysis presented here necessarily simplifies a great number of conflict characteristics. The emphasis throughout is on developing and assessing metrics in each area that provide a sense of the level of difficulty faced by each side in achieving its objectives. Apart from practical limitations, selectivity is driven largely by the desire to make the work transparent and replicable. Moreover, given the complexities and uncertainties in modern warfare, one could make the case that it is better to capture a handful of important dynamics than to present the illusion of comprehensiveness and precision. All that said, the analysis is grounded in recognized conclusions from a variety of historical sources on modern warfare, from the air war over Korea and Vietnam to the naval conflict in the Falklands and SAM hunting in Kosovo and Iraq. [Emphasis added].
We coded most of the scorecards (nine out of ten) using a five-color stoplight scheme to denote major or minor U.S. advantage, a competitive situation, or major or minor Chinese advantage. Advantage, in this case, means that one side is able to achieve its primary objectives in an operationally relevant time frame while the other side would have trouble in doing so. [Footnote] For example, even if the U.S. military could clear the skies of Chinese escort fighters with minimal friendly losses, the air superiority scorecard could be coded as “Chinese advantage” if the United States cannot prevail while the invasion hangs in the balance. If U.S. forces cannot move on to focus on destroying attacking strike and bomber aircraft, they cannot contribute to the larger mission of protecting Taiwan.
All of the dynamic modeling methodology (which involved a mix of statistical analysis, Monte Carlo simulation, and modified Lanchester equations) is publicly available and widely used by specialists at U.S. and foreign civilian and military universities.” [Emphasis added].
As TDI has contended before, the problem with using Lanchester’s equations is that, despite numerous efforts, no one has been able to demonstrate that they accurately represent real-world combat. So, even with statistics and simulation, how good are the results if they have relied on factors or force ratios with no relation to actual combat?
What about new capabilities?
As previously posted, the Kratos Mako Unmanned Combat Aerial Vehicle (UCAV), marketed as the “unmanned wingman,” has recently been cleared for export by the U.S. State Department. This vehicle is specifically oriented towards air-to-air combat, is stated to have unparalleled maneuverability, as it need not abide by limits imposed by human physiology. The Mako “offers fighter-like performance and is designed to function as a wingman to manned aircraft, as a force multiplier in contested airspace, or to be deployed independently or in groups of UASs. It is capable of carrying both weapons and sensor systems.” In addition, the Mako has the capability to be launched independently of a runway, as illustrated below. The price for these vehicles is three million each, dropping to two million each for an order of at least 100 units. Assuming a cost of $95 million for an F-35A, we can imagine a hypothetical combat scenario pitting two F-35As up against 100 of these Mako UCAVs in a drone swarm; a great example of the famous phrase, quantity has a quality all its own.
A battery of Kratos Aerial Target drone ready for take off. One of the advantages of the low-cost Kratos drones are their ability to get into the air quickly. [Kratos Defense]
How to evaluate the effects of these possible UCAV drone swarms?
In building up towards the analysis of all of these capabilities in the full theater, campaign level conflict, some supplemental wargaming may be useful. One game that takes a good shot at modeling these dynamics is Asian Fleet. This is a part of the venerable Fleet Series, published by Victory Games, designed by Joseph Balkoski to model modern (that is Cold War) naval combat. This game system has been extended in recent years, originally by Command Magazine Japan, and then later by Technical Term Gaming Company.
Screenshot of Asian Fleet module by Bryan Taylor [vassalengine.org]
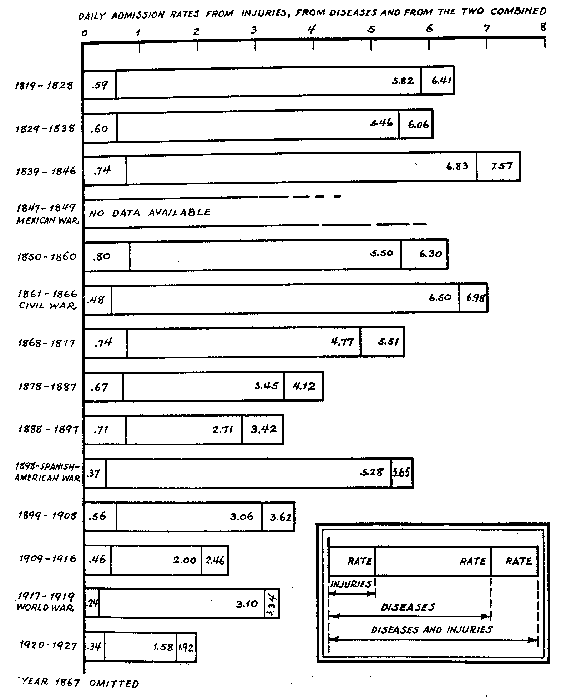
In 1931, Lieutenant Colonel (later Brigadier General) Love, then a Medical Corps physician in the U.S. Army Medical Field Services School, published a study of American casualty data in the recent Great War, titled “War Casualties.”[1] This study was likely the source for tables used for casualty estimation by the U.S. Army through 1944.[2]
Love’s research was likely the basis for rate tables for calculating casualties that first appeared in the 1932 edition of the War Department’s Staff Officer’s Field Manual.[3]
Battle Casualties, including Killed, in Percent of Unit Strength, Staff Officer’s Field Manual (1932).
The 1932 Staff Officer’s Field Manual estimation methodology reflected Love’s sophisticated understanding of the factors influencing combat casualty rates. It showed that both the resistance and combat strength (and all of the factors that comprised it) of the enemy, as well as the equipment and state of training and discipline of the friendly troops had to be taken into consideration. The text accompanying the tables pointed out that loss rates in small units could be quite high and variable over time, and that larger formations took fewer casualties as a fraction of overall strength, and that their rates tended to become more constant over time. Casualties were not distributed evenly, but concentrated most heavily among the combat arms, and in the front-line infantry in particular. Attackers usually suffered higher loss rates than defenders. Other factors to be accounted for included the character of the terrain, the relative amount of artillery on each side, and the employment of gas.
The 1941 iteration of the Staff Officer’s Field Manual, now designated Field Manual (FM) 101-10[4], provided two methods for estimating battle casualties. It included the original 1932 Battle Casualties table, but the associated text no longer included the section outlining factors to be considered in calculating loss rates. This passage was moved to a note appended to a new table showing the distribution of casualties among the combat arms.
Rather confusingly, FM 101-10 (1941) presented a second table, Estimated Daily Losses in Campaign of Personnel, Dead and Evacuated, Per 1,000 of Actual Strength. It included rates for front line regiments and divisions, corps and army units, reserves, and attached cavalry. The rates were broken down by posture and tactical mission.
Estimated Daily Losses in Campaign of Personnel, Dead and Evacuated, Per 1,000 of Actual Strength, FM 101-10 (1941)
The source for this table is unknown, nor the method by which it was derived. No explanatory text accompanied it, but a footnote stated that “this table is intended primarily for use in school work and in field exercises.” The rates in it were weighted toward the upper range of the figures provided in the 1932 Battle Casualties table.
The October 1943 edition of FM 101-10 contained no significant changes from the 1941 version, except for the caveat that the 1932 Battle Casualties table “may or may not prove correct when applied to the present conflict.”
The October 1944 version of FM 101-10 incorporated data obtained from World War II experience.[5] While it also noted that the 1932 Battle Casualties table might not be applicable, the experiences of the U.S. II Corps in North Africa and one division in Italy were found to be in agreement with the table’s division and corps loss rates.
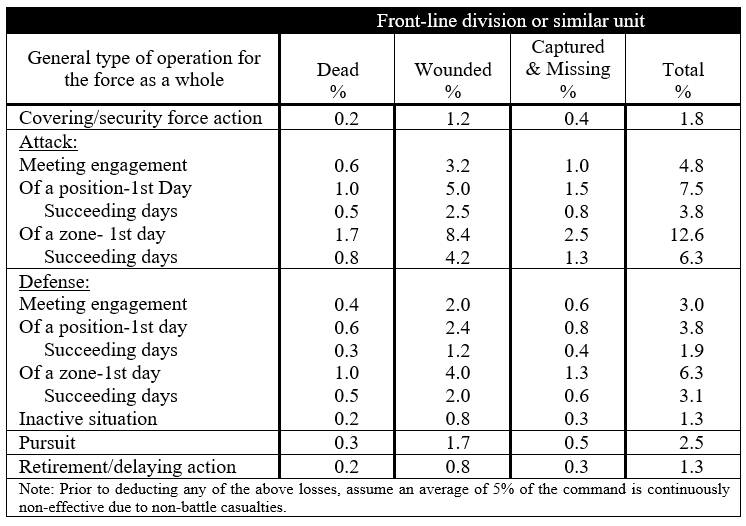
FM 101-10 (1944) included another new table, Estimate of Battle Losses for a Front-Line Division (in % of Actual Strength), meaning that it now provided three distinct methods for estimating battle casualties.
Estimate of Battle Losses for a Front-Line Division (in % of Actual Strength), FM 101-10 (1944)
Like the 1941 Estimated Daily Losses in Campaign table, the sources for this new table were not provided, and the text contained no guidance as to how or when it should be used. The rates it contained fell roughly within the span for daily rates for severe (6-8%) to maximum (12%) combat listed in the 1932 Battle Casualty table, but would produce vastly higher overall rates if applied consistently, much higher than the 1932 table’s 1% daily average.
FM 101-10 (1944) included a table showing the distribution of losses by branch for the theater based on experience to that date, except for combat in the Philippine Islands. The new chart was used in conjunction with the 1944 Estimate of Battle Losses for a Front-Line Division table to determine daily casualty distribution.
Distribution of Battle Losses–Theater of Operations, FM 101-10 (1944)
The final World War II version of FM 101-10 issued in August 1945[6] contained no new casualty rate tables, nor any revisions to the existing figures. It did finally effectively invalidate the 1932 Battle Casualties table by noting that “the following table has been developed from American experience in active operations and, of course, may not be applicable to a particular situation.” (original emphasis)
NOTES
[1] Albert G. Love, War Casualties, The Army Medical Bulletin, No. 24, (Carlisle Barracks, PA: 1931)
[2] This post is adapted from TDI, Casualty Estimation Methodologies Study, Interim Report (May 2005) (Altarum) (pp. 314-317).
[3] U.S. War Department, Staff Officer’s Field Manual, Part Two: Technical and Logistical Data (Government Printing Office, Washington, D.C., 1932)
[4] U.S. War Department, FM 101-10, Staff Officer’s Field Manual: Organization, Technical and Logistical Data (Washington, D.C., June 15, 1941)
[5] U.S. War Department, FM 101-10, Staff Officer’s Field Manual: Organization, Technical and Logistical Data (Washington, D.C., October 12, 1944)
[6] U.S. War Department, FM 101-10 Staff Officer’s Field Manual: Organization, Technical and Logistical Data (Washington, D.C., August 1, 1945)
Stretcher bearers of the East Surrey Regiment, with a Churchill tank of the North Irish Horse in the background, during the attack on Longstop Hill, Tunisia, 23 April 1943. [Imperial War Museum/Wikimedia]
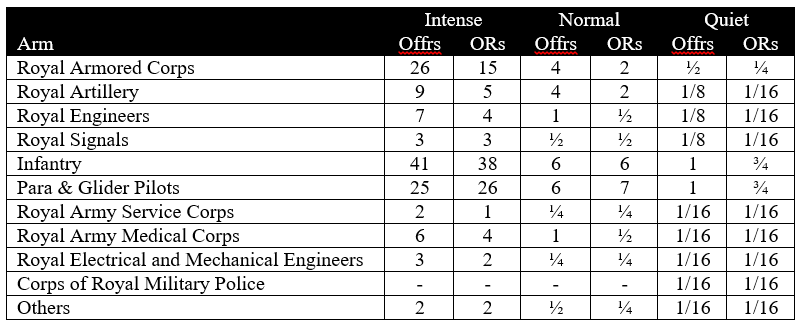
British Army staff officers during World War II and the 1950s used a set of look-up tables which listed expected monthly losses in percentage of strength for various arms under various combat conditions. The origin of the tables is not known, but they were officially updated twice, in 1942 by a committee chaired by Major General Evett, and in 1951-1955 by the Army Operations Research Group (AORG).[2]
The methodology was based on staff predictions of one of three levels of operational activity, “Intense,” “Normal,” and “Quiet.” These could be applied to an entire theater, or to individual divisions. The three levels were defined the same way for both the Evett Committee and AORG rates:
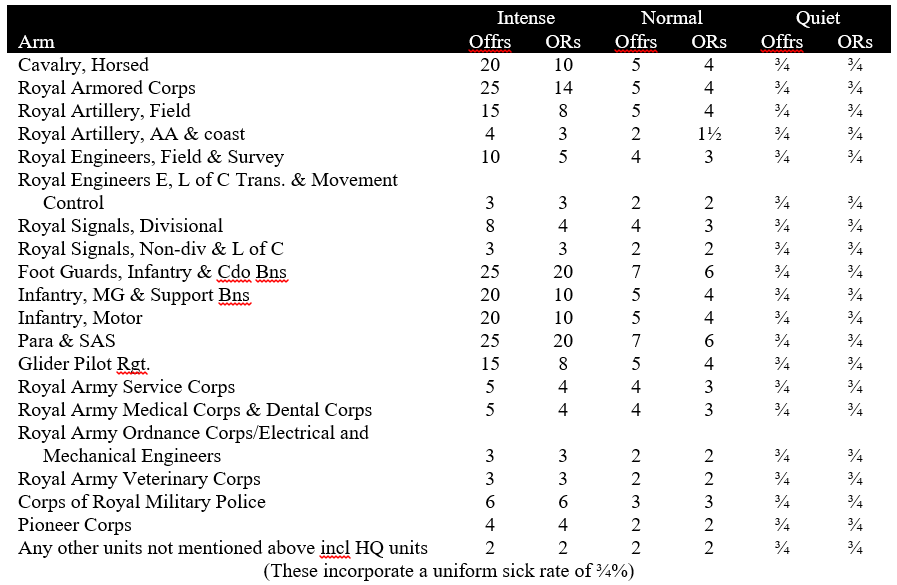
The rates were broken down by arm and rank, and included battle and nonbattle casualties.
Rates of Personnel Wastage Including Both Battle and Non-battle Casualties According to the Evett Committee of 1942. (Percent per 30 days).
The Evett Committee rates were criticized during and after the war. After British forces suffered twice the anticipated casualties at Anzio, the British 21st Army Group applied a “double intense rate” which was twice the Evett Committee figure and intended to apply to assaults. When this led to overestimates of casualties in Normandy, the double intense rate was discarded.
From 1951 to 1955, AORG undertook a study of casualty rates in World War II. Its analysis was based on casualty data from the following campaigns:
Northwest Europe, 1944
6-30 June – Beachhead offensive
1 July-1 September – Containment and breakout
1 October-30 December – Semi-static phase
9 February to 6 May – Rhine crossing and final phase
Italy, 1944
January to December – Fighting a relatively equal enemy in difficult country. Warfare often static.
January to February (Anzio) – Beachhead held against severe and well-conducted enemy counter-attacks.
North Africa, 1943
14 March-13 May – final assault
Northwest Europe, 1940
10 May-2 June – Withdrawal of BEF
Burma, 1944-45
From the first four cases, the AORG study calculated two sets of battle casualty rates as percentage of strength per 30 days. “Overall” rates included KIA, WIA, C/MIA. “Apparent rates” included these categories but subtracted troops returning to duty. AORG recommended that “overall” rates be used for the first three months of a campaign.
The Burma campaign data was evaluated differently. The analysts defined a “force wastage” category which included KIA, C/MIA, evacuees from outside the force operating area and base hospitals, and DNBI deaths. “Dead wastage” included KIA, C/MIA, DNBI dead, and those discharged from the Army as a result of injuries.
The AORG study concluded that the Evett Committee underestimated intense loss rates for infantry and armor during periods of very hard fighting and overestimated casualty rates for other arms. It recommended that if only one brigade in a division was engaged, two-thirds of the intense rate should be applied, if two brigades were engaged the intense rate should be applied, and if all brigades were engaged then the intense rate should be doubled. It also recommended that 2% extra casualties per month should be added to all the rates for all activities should the forces encounter heavy enemy air activity.[1]
The AORG study rates were as follows:
Recommended AORG Rates of Personnel Wastage. (Percent per 30 days).
If anyone has further details on the origins and activities of the Evett Committee and AORG, we would be very interested in finding out more on this subject.
NOTES
[1] This post is adapted from The Dupuy Institute, Casualty Estimation Methodologies Study, Interim Report (May 2005) (Altarum) (pp. 51-53).
[2] Rowland Goodman and Hugh Richardson. “Casualty Estimation in Open and Guerrilla Warfare.” (London: Directorate of Science (Land), U.K. Ministry of Defence, June 1995.), Appendix A.
Dr. Peter Perla, noted defense researcher, wargame designer and expert, and author of the seminal The Art of Wargaming: A Guide for Professionals and Hobbyists, gave the keynote address at the 2017 Connections Wargaming Conference last August. The topic of his speech, which served as his valedictory address on the occasion of his retirement from government service, addressed the predictive power of wargaming. In it, Perla recalled a conversation he once had with Trevor Dupuy in the early 1990s:
Like most good stories, this one has a beginning, a middle, and an end. I have sort of jumped in at the middle. So let’s go back to the beginning.
As it happens, that beginning came during one of the very first Connections. It may even have been the first one. This thread is one of those vivid memories we all have of certain events in life. In my case, it is a short conversation I had with Trevor Dupuy.
I remember the setting well. We were in front of the entrance to the O Club at Maxwell. It was kind of dark, but I can’t recall if it was in the morning before the club opened for our next session, or the evening, before a dinner. Trevor and I were chatting and he said something about wargaming being predictive. I still recall what I said.
“Good grief, Trevor, we can’t even predict the outcome of a Super Bowl game much less that of a battle!” He seemed taken by surprise that I felt that way, and he replied, “Well, if that is true, what are we doing? What’s the point?”
I had my usual stock answers. We wargame to develop insights, to identify issues, and to raise questions. We certainly don’t wargame to predict what will happen in a battle or a war. I was pretty dogmatic in those days. Thank goodness I’m not that way any more!
The question of prediction did not go away, however.
For the rest of Perla’s speech, see here. For a wonderful summary of the entire 2017 Connections Wargaming conference, see here.
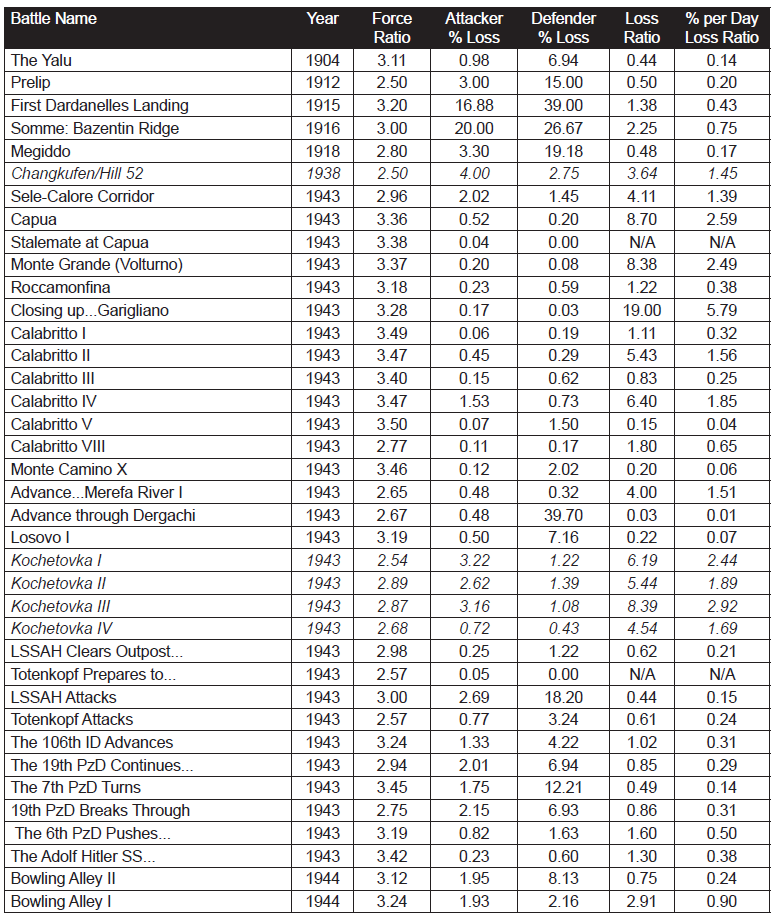
The first was chosen to provide a historical context for the 3:1 rule of thumb. The second was chosen so as to examine how this rule applies to modern combat data.
We decided that this should be tested to the RAND version of the 3:1 rule as documented by RAND in 1992 and used in JICM [Joint Integrated Contingency Model] (with SFS [Situational Force Scoring]) and other models. This rule, as presented by RAND, states: “[T]he famous ‘3:1 rule,’ according to which the attacker and defender suffer equal fractional loss rates at a 3:1 force ratio if the battle is in mixed terrain and the defender enjoys ‘prepared’ defenses…”
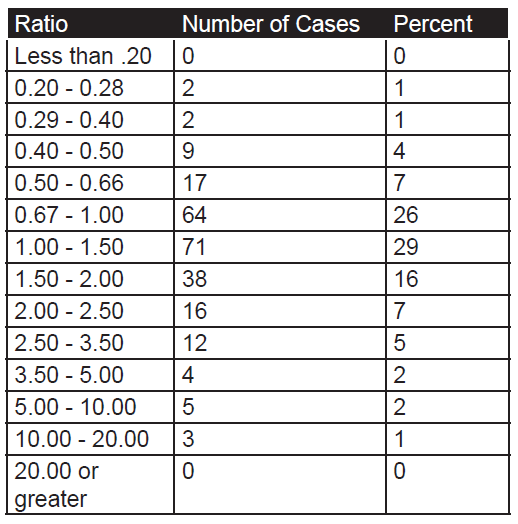
Therefore, we selected out all those engagements from these two databases that ranged from force ratios of 2.5 to 1 to 3.5 to 1 (inclusive). It was then a simple matter to map those to a chart that looked at attackers losses compared to defender losses. In the case of the pre-1904 cases, even with a large database (243 cases), there were only 12 cases of combat in that range, hardly statistically significant. That was because most of the combat was at odds ratios in the range of .50-to-1 to 2.00-to-one.
The count of number of engagements by odds in the pre-1904 cases:
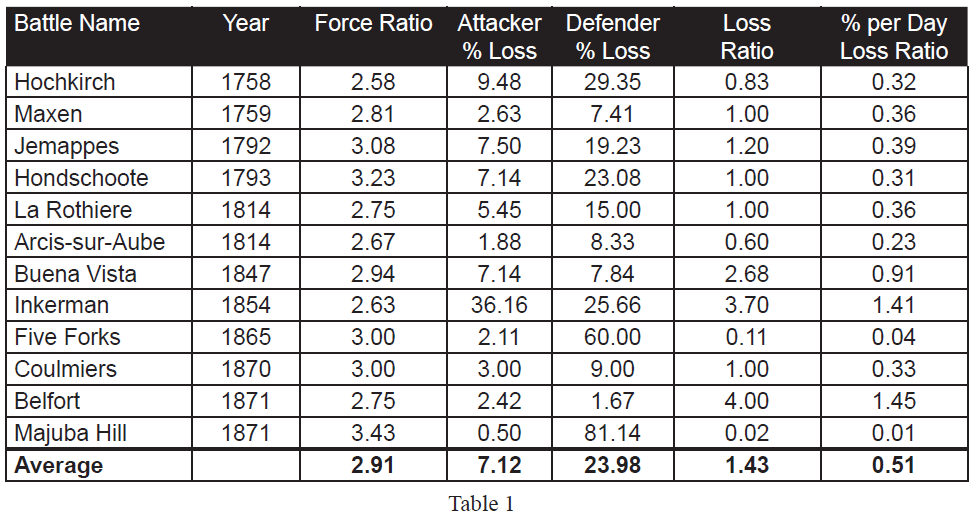
As the database is one of battles, then usually these are only joined at reasonably favorable odds, as shown by the fact that 88 percent of the battles occur between 0.40 and 2.50 to 1 odds. The twelve pre-1904 cases in the range of 2.50 to 3.50 are shown in Table 1.
If the RAND version of the 3:1 rule was valid, one would expect that the “Percent per Day Loss Ratio” (the last column) would hover around 1.00, as this is the ratio of attacker percent loss rate to the defender percent loss rate. As it is, 9 of the 12 data points are noticeably below 1 (below 0.40 or a 1 to 2.50 exchange rate). This leaves only three cases (25%) with an exchange rate that would support such a “rule.”
If we look at the simple ratio of actual losses (vice percent losses), then the numbers comes much closer to parity, but this is not the RAND interpretation of the 3:1 rule. Six of the twelve numbers “hover” around an even exchange ratio, with six other sets of data being widely off that central point. “Hover” for the rest of this discussion means that the exchange ratio ranges from 0.50-to-1 to 2.00-to 1.
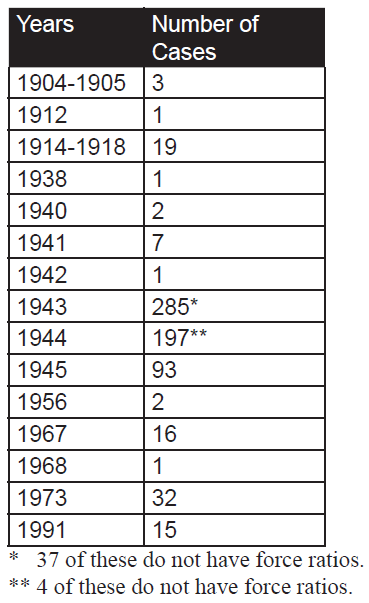
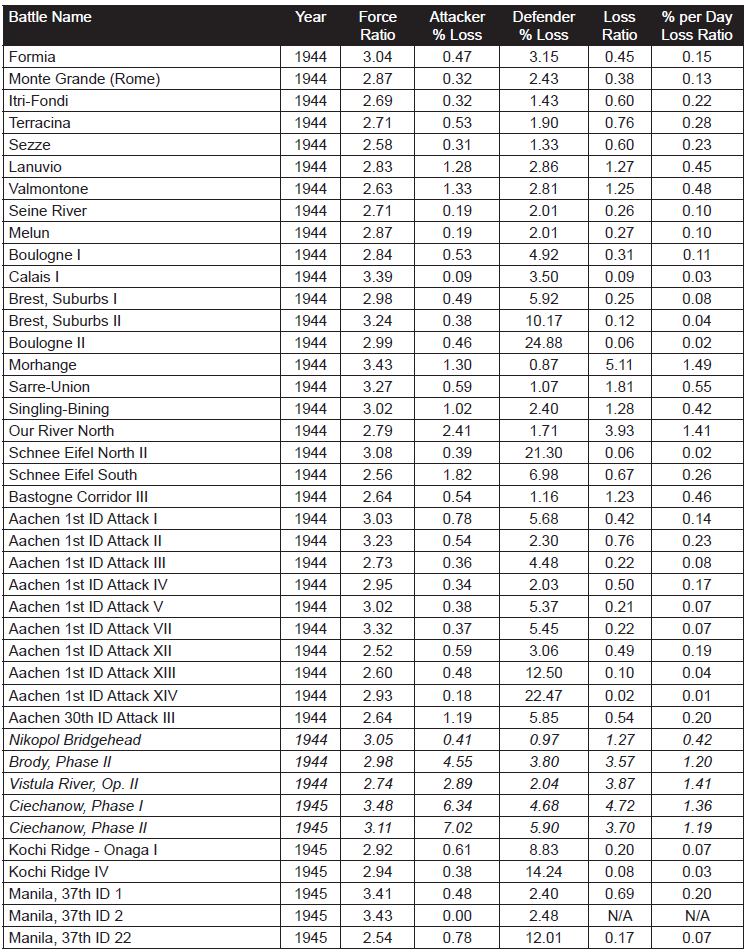
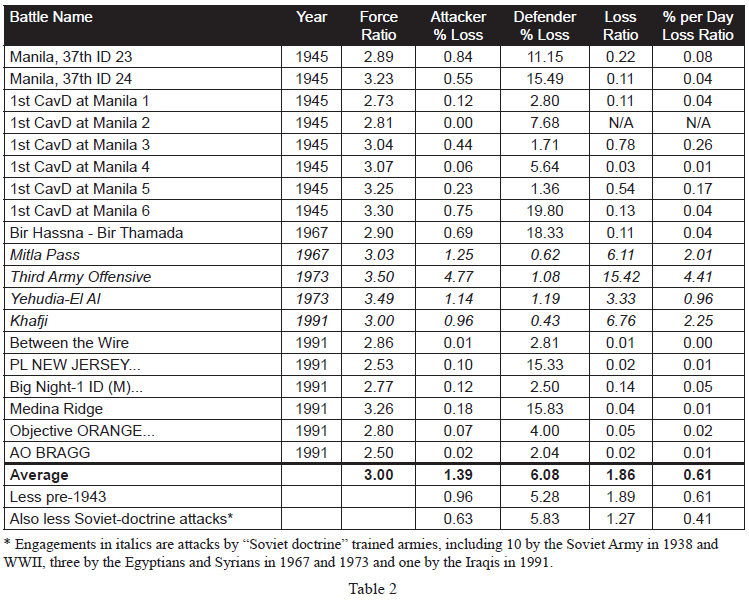
Still, this is early modern linear combat, and is not always representative of modern war. Instead, we will examine 634 cases in the Division-level Database (which consists of 675 cases) where we have worked out the force ratios. While this database covers from 1904 to 1991, most of the cases are from WWII (1939- 1945). Just to compare:
As such, 87% of the cases are from WWII data and 10% of the cases are from post-WWII data. The engagements without force ratios are those that we are still working on as The Dupuy Institute is always expanding the DLEDB as a matter of routine. The specific cases, where the force ratios are between 2.50 and 3.50 to 1 (inclusive) are shown in Table 2:
This is a total of 98 engagements at force ratios of 2.50 to 3.50 to 1. It is 15 percent of the 634 engagements for which we had force ratios. With this fairly significant representation of the overall population, we are still getting no indication that the 3:1 rule, as RAND postulates it applies to casualties, does indeed fit the data at all. Of the 98 engagements, only 19 of them demonstrate a percent per day loss ratio (casualty exchange ratio) between 0.50-to-1 and 2-to-1. This is only 19 percent of the engagements at roughly 3:1 force ratio. There were 72 percent (71 cases) of those engagements at lower figures (below 0.50-to-1) and only 8 percent (cases) are at a higher exchange ratio. The data clearly was not clustered around the area from 0.50-to- 1 to 2-to-1 range, but was well to the left (lower) of it.
Looking just at straight exchange ratios, we do get a better fit, with 31 percent (30 cases) of the figure ranging between 0.50 to 1 and 2 to 1. Still, this figure exchange might not be the norm with 45 percent (44 cases) lower and 24 percent (24 cases) higher. By definition, this fit is 1/3rd the losses for the attacker as postulated in the RAND version of the 3:1 rule. This is effectively an order of magnitude difference, and it clearly does not represent the norm or the center case.
The percent per day loss exchange ratio ranges from 0.00 to 5.71. The data tends to be clustered at the lower values, so the high values are very much outliers. The highest percent exchange ratio is 5.71, the second highest is 4.41, the third highest is 2.92. At the other end of the spectrum, there are four cases where no losses were suffered by one side and seven where the exchange ratio was .01 or less. Ignoring the “N/A” (no losses suffered by one side) and the two high “outliers (5.71 and 4.41), leaves a range of values from 0.00 to 2.92 across 92 cases. With an even distribution across that range, one would expect that 51 percent of them would be in the range of 0.50-to-1 and 2.00-to-1. With only 19 percent of the cases being in that range, one is left to conclude that there is no clear correlation here. In fact, it clearly is the opposite effect, which is that there is a negative relationship. Not only is the RAND construct unsupported, it is clearly and soundly contradicted with this data. Furthermore, the RAND construct is theoretically a worse predictor of casualty rates than if one randomly selected a value for the percentile exchange rates between the range of 0 and 2.92. We do believe this data is appropriate and accurate for such a test.
As there are only 19 cases of 3:1 attacks falling in the even percentile exchange rate range, then we should probably look at these cases for a moment:
One will note, in these 19 cases, that the average attacker casualties are way out of line with the average for the entire data set (3.20 versus 1.39 or 3.20 versus 0.63 with pre-1943 and Soviet-doctrine attackers removed). The reverse is the case for the defenders (3.12 versus 6.08 or 3.12 versus 5.83 with pre-1943 and Soviet-doctrine attackers removed). Of course, of the 19 cases, 2 are pre-1943 cases and 7 are cases of Soviet-doctrine attackers (in fact, 8 of the 14 cases of the Soviet-doctrine attackers are in this selection of 19 cases). This leaves 10 other cases from the Mediterranean and ETO (Northwest Europe 1944). These are clearly the unusual cases, outliers, etc. While the RAND 3:1 rule may be applicable for the Soviet-doctrine offensives (as it applies to 8 of the 14 such cases we have), it does not appear to be applicable to anything else. By the same token, it also does not appear to apply to virtually any cases of post-WWII combat. This all strongly argues that not only is the RAND construct not proven, but it is indeed clearly not correct.
The fact that this construct also appears in Soviet literature, but nowhere else in US literature, indicates that this is indeed where the rule was drawn from. One must consider the original scenarios run for the RSAC [RAND Strategy Assessment Center] wargame were “Fulda Gap” and Korean War scenarios. As such, they were regularly conducting battles with Soviet attackers versus Allied defenders. It would appear that the 3:1 rule that they used more closely reflected the experiences of the Soviet attackers in WWII than anything else. Therefore, it may have been a fine representation for those scenarios as long as there was no US counterattacking or US offensives (and assuming that the Soviet Army of the 1980s performed at the same level as in did in the 1940s).
There was a clear relative performance difference between the Soviet Army and the German Army in World War II (see our Capture Rate Study Phase I & II and Measuring Human Factors in Combat for a detailed analysis of this).[1] It was roughly in the order of a 3-to-1-casualty exchange ratio. Therefore, it is not surprising that Soviet writers would create analytical tables based upon an equal percentage exchange of losses when attacking at 3:1. What is surprising, is that such a table would be used in the US to represent US forces now. This is clearly not a correct application.
Therefore, RAND’s SFS, as currently constructed, is calibrated to, and should only be used to represent, a Soviet-doctrine attack on first world forces where the Soviet-style attacker is clearly not properly trained and where the degree of performance difference is similar to that between the Germans and Soviets in 1942-44. It should not be used for US counterattacks, US attacks, or for any forces of roughly comparable ability (regardless of whether Soviet-style doctrine or not). Furthermore, it should not be used for US attacks against forces of inferior training, motivation and cohesiveness. If it is, then any such tables should be expected to produce incorrect results, with attacker losses being far too high relative to the defender. In effect, the tables unrealistically penalize the attacker.
As JICM with SFS is now being used for a wide variety of scenarios, then it should not be used at all until this fundamental error is corrected, even if that use is only for training. With combat tables keyed to a result that is clearly off by an order of magnitude, then the danger of negative training is high.
Christopher A. Lawrence, War by Numbers: Understanding Conventional Combat (Lincoln, NE: Potomac Books, 2017) 390 pages, $39.95
War by Numbers assesses the nature of conventional warfare through the analysis of historical combat. Christopher A. Lawrence (President and Executive Director of The Dupuy Institute) establishes what we know about conventional combat and why we know it. By demonstrating the impact a variety of factors have on combat he moves such analysis beyond the work of Carl von Clausewitz and into modern data and interpretation.
Using vast data sets, Lawrence examines force ratios, the human factor in case studies from World War II and beyond, the combat value of superior situational awareness, and the effects of dispersion, among other elements. Lawrence challenges existing interpretations of conventional warfare and shows how such combat should be conducted in the future, simultaneously broadening our understanding of what it means to fight wars by the numbers.
The book is available in paperback directly from Potomac Books and in paperback and Kindle from Amazon.
Last autumn, U.S. Army Chief of Staff General Mark Milley asserted that “we are on the cusp of a fundamental change in the character of warfare, and specifically ground warfare. It will be highly lethal, very highly lethal, unlike anything our Army has experienced, at least since World War II.” He made these comments while describing the Army’s evolving Multi-Domain Battle concept for waging future combat against peer or near-peer adversaries.
It is possible that ground combat attrition in the future between peer or near-peer combatants may be comparable to the U.S. experience in World War II (although there were considerable differences between the experiences of the various belligerents). Combat losses could be heavier. It certainly seems likely that they would be higher than those experienced by U.S. forces in recent counterinsurgency operations.
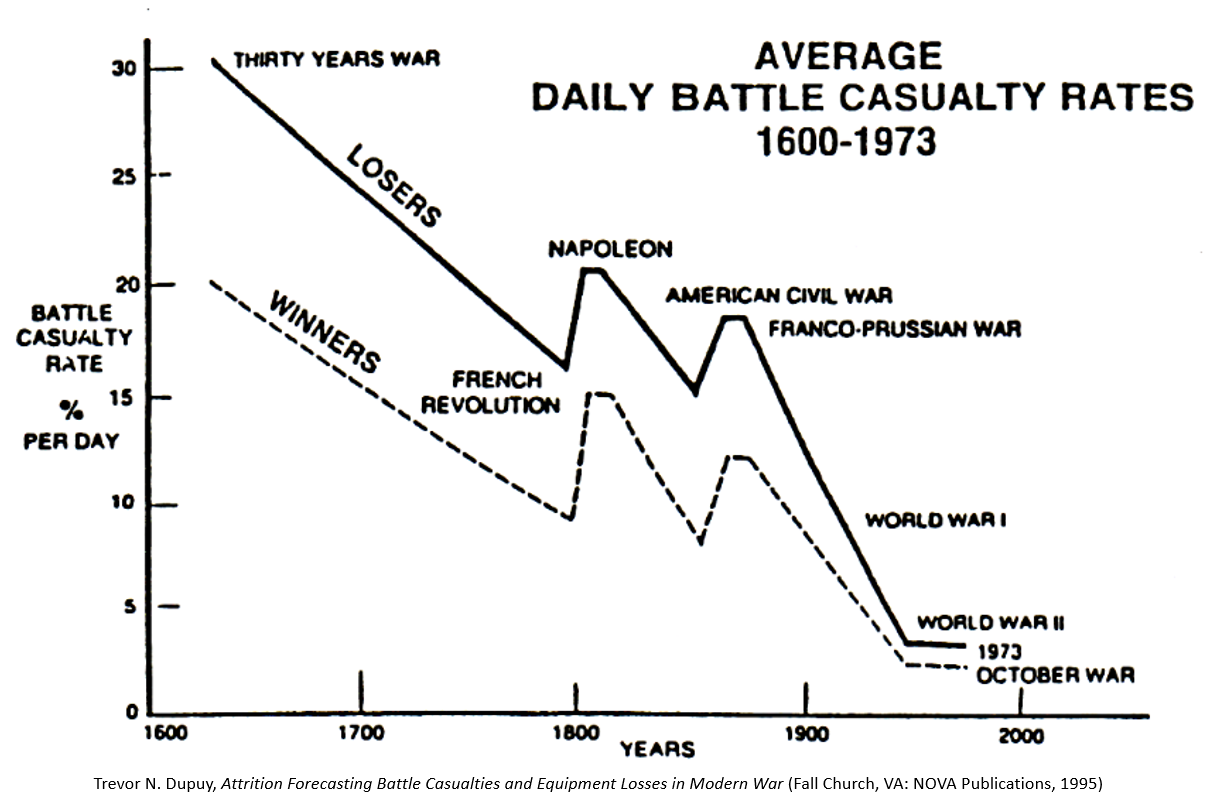
Dupuy documented a clear relationship over time between increasing weapon lethality, greater battlefield dispersion, and declining casualty rates in conventional combat. Even as weapons became more lethal, greater dispersal in frontage and depth among ground forces led daily personnel loss rates in battle to decrease.
The average daily battle casualty rate in combat has been declining since 1600 as a consequence. Since battlefield weapons continue to increase in lethality and troops continue to disperse in response, it seems logical to presume the trend in loss rates continues to decline, although this may not necessarily be the case. There were two instances in the 19th century where daily battle casualty rates increased—during the Napoleonic Wars and the American Civil War—before declining again. Dupuy noted that combat casualty rates in the 1973 Arab-Israeli War remained roughly the same as those in World War II (1939-45), almost thirty years earlier. Further research is needed to determine if average daily personnel loss rates have indeed continued to decrease into the 21st century.
Dupuy also discovered that, as with battle outcomes, casualty rates are influenced by the circumstantial variables of combat. Posture, weather, terrain, season, time of day, surprise, fatigue, level of fortification, and “all out” efforts affect loss rates. (The combat loss rates of armored vehicles, artillery, and other other weapons systems are directly related to personnel loss rates, and are affected by many of the same factors.) Consequently, yet counterintuitively, he could find no direct relationship between numerical force ratios and combat casualty rates. Combat power ratios which take into account the circumstances of combat do affect casualty rates; forces with greater combat power inflict higher rates of casualties than less powerful forces do.
Winning forces suffer lower rates of combat losses than losing forces do, whether attacking or defending. (It should be noted that there is a difference between combat loss rates and numbers of losses. Depending on the circumstances, Dupuy found that the numerical losses of the winning and losing forces may often be similar, even if the winner’s casualty rate is lower.)
Dupuy’s research confirmed the fact that the combat loss rates of smaller forces is higher than that of larger forces. This is in part due to the fact that smaller forces have a larger proportion of their troops exposed to enemy weapons; combat casualties tend to concentrated in the forward-deployed combat and combat support elements. Dupuy also surmised that Prussian military theorist Carl von Clausewitz’s concept of friction plays a role in this. The complexity of interactions between increasing numbers of troops and weapons simply diminishes the lethal effects of weapons systems on real world battlefields.
Somewhat unsurprisingly, higher quality forces (that better manage the ambient effects of friction in combat) inflict casualties at higher rates than those with less effectiveness. This can be seen clearly in the disparities in casualties between German and Soviet forces during World War II, Israeli and Arab combatants in 1973, and U.S. and coalition forces and the Iraqis in 1991 and 2003.
Combat Loss Rates on Future Battlefields
What do Dupuy’s combat attrition verities imply about casualties in future battles? As a baseline, he found that the average daily combat casualty rate in Western Europe during World War II for divisional-level engagements was 1-2% for winning forces and 2-3% for losing ones. For a divisional slice of 15,000 personnel, this meant daily combat losses of 150-450 troops, concentrated in the maneuver battalions (The ratio of wounded to killed in modern combat has been found to be consistently about 4:1. 20% are killed in action; the other 80% include mortally wounded/wounded in action, missing, and captured).
It seems reasonable to conclude that future battlefields will be less densely occupied. Brigades, battalions, and companies will be fighting in spaces formerly filled with armies, corps, and divisions. Fewer troops mean fewer overall casualties, but the daily casualty rates of individual smaller units may well exceed those of WWII divisions. Smaller forces experience significant variation in daily casualties, but Dupuy established average daily rates for them as shown below.
For example, based on Dupuy’s methodology, the average daily loss rate unmodified by combat variables for brigade combat teams would be 1.8% per day, battalions would be 8% per day, and companies 21% per day. For a brigade of 4,500, that would result in 81 battle casualties per day, a battalion of 800 would suffer 64 casualties, and a company of 120 would lose 27 troops. These rates would then be modified by the circumstances of each particular engagement.
Several factors could push daily casualty rates down. Milley envisions that U.S. units engaged in an anti-access/area denial environment will be constantly moving. A low density, highly mobile battlefield with fluid lines would be expected to reduce casualty rates for all sides. High mobility might also limit opportunities for infantry assaults and close quarters combat. The high operational tempo will be exhausting, according to Milley. This could also lower loss rates, as the casualty inflicting capabilities of combat units decline with each successive day in battle.
It is not immediately clear how cyberwarfare and information operations might influence casualty rates. One combat variable they might directly impact would be surprise. Dupuy identified surprise as one of the most potent combat power multipliers. A surprised force suffers a higher casualty rate and surprisers enjoy lower loss rates. Russian combat doctrine emphasizes using cyber and information operations to achieve it and forces with degraded situational awareness are highly susceptible to it. As Zelenopillya demonstrated, surprise attacks with modern weapons can be devastating.
Some factors could push combat loss rates up. Long-range precision weapons could expose greater numbers of troops to enemy fires, which would drive casualties up among combat support and combat service support elements. Casualty rates historically drop during night time hours, although modern night-vision technology and persistent drone reconnaissance might will likely enable continuous night and day battle, which could result in higher losses.
Drawing solid conclusions is difficult but the question of future battlefield attrition is far too important not to be studied with greater urgency. Current policy debates over whether or not the draft should be reinstated and the proper size and distribution of manpower in active and reserve components of the Army hinge on getting this right. The trend away from mass on the battlefield means that there may not be a large margin of error should future combat forces suffer higher combat casualties than expected.
Today’s edition of TDI Friday Read asks the question, how do we know if the theories and concepts we use to understand and explain war and warfare accurately depict reality? There is certainly no shortage of explanatory theories available, starting with Sun Tzu in the 6th century BCE and running to the present. As I have mentioned before, all combat models and simulations are theories about how combat works. Military doctrine is also a functional theory of warfare. But how do we know if any of these theories are actually true?
Well, one simple way to find out if a particular theory is valid is to use it to predict the outcome of the phenomenon it purports to explain. Testing theory through prediction is a fundamental aspect of the philosophy of science. If a theory is accurate, it should be able to produce a reasonable accurate prediction of future behavior.
In his 2016 article, “Can We Predict Politics? Toward What End?” Michael D. Ward, a Professor of Political Science at Duke University, made a case for a robust effort for using prediction as a way of evaluating the thicket of theory populating security and strategic studies. Dropping invalid theories and concepts is important, but there is probably more value in figuring out how and why they are wrong.
Trevor Dupuy and TDI publicly put their theories to the test in the form of combat casualty estimates for the 1991 Gulf Way, the U.S. intervention in Bosnia, and the Iraqi insurgency. How well did they do?
Dupuy himself argued passionately for independent testing of combat models against real-world data, a process known as validation. This is actually seldom done in the U.S. military operations research community.
However, TDI has done validation testing of Dupuy’s Quantified Judgement Model (QJM) and Tactical Numerical Deterministic Model (TNDM). The results are available for all to judge.
I will conclude this post on a dissenting note. Trevor Dupuy spent decades arguing for more rigor in the development of combat models and analysis, with only modest success. In fact, he encountered significant skepticism and resistance to his ideas and proposals. To this day, the U.S. Defense Department seems relatively uninterested in evidence-based research on this subject. Why?
David Wilkinson, Editor-in-Chief of the Oxford Review, wrote a fascinating blog post looking at why practitioners seem to have little actual interest in evidence-based practice.
The problem with evidence based practice is that outside of areas like health care and aviation/technology is that most people in organisations don’t care about having research evidence for almost anything they do. That doesn’t mean they are not interesting in research but they are just not that interested in using the research to change how they do things – period.
His explanation for why this is and what might be done to remedy the situation is quite interesting.