Changes to Russian tactics typify the manner in which Russia now employs its ground force. Borrowing from the pages of military theorist Carl von Clausewitz, who stated, “It is still more important to remember that almost the only advantage of the attack rests on its initial surprise,” Russia’s contemporary operations embody the characteristic of surprise. Russian operations in Georgia and Ukraine demonstrate a rapid, decentralized attack seeking to temporally dislocate the enemy, triggering the opposing forces’ defeat.
Tactical surprise enabled by electronic, cyber, information and unconventional warfare capabilities, combined with mobile and powerful combined arms brigade tactical groups, and massive and lethal long-range fires provide Russian Army ground forces with formidable combat power.
Trevor Dupuy considered the combat value of surprise to be important enough to cite it as one of his “timeless verities of combat.”
Surprise substantially enhances combat power. Achieving surprise in combat has always been important. It is perhaps more important today than ever. Quantitative analysis of historical combat shows that surprise has increased the combat power of military forces in those engagements in which it was achieved. Surprise has proven to be the greatest of all combat multipliers. It may be the most important of the Principles of War; it is at least as important as Mass and Maneuver.
In his combat models, Dupuy categorized tactical surprise as complete, substantial, and minor; defining the level achieved was a matter of analyst judgement. The combat effects of surprise in battle would last for three days, declining by one-third each day.
He developed two methods for applying the effects of surprise in calculating combat power, each yielding the same general overall influence. In his original Quantified Judgement Model (QJM) detailed inNumbers, Predictions and War: The Use of History to Evaluate and Predict the Outcome of Armed Conflict (1977), factors for surprise were applied to calculations for vulnerability and mobility, which in turn were applied to the calculation of overall combat power. The net value of surprise on combat power ranged from a factor of about 2.24 for complete surprise to 1.10 for minor surprise.
For a simplified version of his combat power calculation detailed in Attrition: Forecasting Battle Casualties and Equipment Losses in Modern War (1990), Dupuy applied a surprise combat multiplier value directly to the calculation of combat power. These figures also ranged between 2.20 for complete surprise and 1.10 for minor surprise.
Dupuy established these values for surprise based on his judgement of the difference between the calculated outcome of combat engagements in his data and theoretical outcomes based on his models. He never validated them back to his data himself. However, TDI President Chris Lawrence recently did conduct substantial tests on TDI’s expanded combat databases in the context of analyzing the combat value of situational awareness. The results are described in detail in his forthcoming book, War By Numbers: Understanding Conventional Combat.
[This article was originally posted on 11 October 2016]
In 2004, military analyst and academic Stephen Biddle published Military Power: Explaining Victory and Defeat in Modern Battle, a book that addressed the fundamental question of what causes victory and defeat in battle. Biddle took to task the study of the conduct of war, which he asserted was based on “a weak foundation” of empirical knowledge. He surveyed the existing literature on the topic and determined that the plethora of theories of military success or failure fell into one of three analytical categories: numerical preponderance, technological superiority, or force employment.
Numerical preponderance theories explain victory or defeat in terms of material advantage, with the winners possessing greater numbers of troops, populations, economic production, or financial expenditures. Many of these involve gross comparisons of numbers, but some of the more sophisticated analyses involve calculations of force density, force-to-space ratios, or measurements of quality-adjusted “combat power.” Notions of threshold “rules of thumb,” such as the 3-1 rule, arise from this. These sorts of measurements form the basis for many theories of power in the study of international relations.
The next most influential means of assessment, according to Biddle, involve views on the primacy of technology. One school, systemic technology theory, looks at how technological advances shift balances within the international system. The best example of this is how the introduction of machine guns in the late 19th century shifted the advantage in combat to the defender, and the development of the tank in the early 20th century shifted it back to the attacker. Such measures are influential in international relations and political science scholarship.
The other school of technological determinacy is dyadic technology theory, which looks at relative advantages between states regardless of posture. This usually involves detailed comparisons of specific weapons systems, tanks, aircraft, infantry weapons, ships, missiles, etc., with the edge going to the more sophisticated and capable technology. The use of Lanchester theory in operations research and combat modeling is rooted in this thinking.
Biddle identified the third category of assessment as subjective assessments of force employment based on non-material factors including tactics, doctrine, skill, experience, morale or leadership. Analyses on these lines are the stock-in-trade of military staff work, military historians, and strategic studies scholars. However, international relations theorists largely ignore force employment and operations research combat modelers tend to treat it as a constant or omit it because they believe its effects cannot be measured.
The common weakness of all of these approaches, Biddle argued, is that “there are differing views, each intuitively plausible but none of which can be considered empirically proven.” For example, no one has yet been able to find empirical support substantiating the validity of the 3-1 rule or Lanchester theory. Biddle notes that the track record for predictions based on force employment analyses has also been “poor.” (To be fair, the problem of testing theory to see if applies to the real world is not limited to assessments of military power, it afflicts security and strategic studies generally.)
So, is Biddle correct? Are there only three ways to assess military outcomes? Are they valid? Can we do better?
Response to Niklas Zetterling’s Article by Christopher A. Lawrence
Mr. Zetterling is currently a professor at the Swedish War College and previously worked at the Swedish National Defense Research Establishment. As I have been having an ongoing dialogue with Prof. Zetterling on the Battle of Kursk, I have had the opportunity to witness his approach to researching historical data and the depth of research. I would recommend that all of our readers take a look at his recent article in the Journal of Slavic Military Studies entitled “Loss Rates on the Eastern Front during World War II.” Mr. Zetterling does his German research directly from the Captured German Military Records by purchasing the rolls of microfilm from the US National Archives. He is using the same German data sources that we are. Let me attempt to address his comments section by section:
The Database on Italy 1943-44:
Unfortunately, the Italian combat data was one of the early HERO research projects, with the results first published in 1971. I do not know who worked on it nor the specifics of how it was done. There are references to the Captured German Records, but significantly, they only reference division files for these battles. While I have not had the time to review Prof. Zetterling‘s review of the original research. I do know that some of our researchers have complained about parts of the Italian data. From what I’ve seen, it looks like the original HERO researchers didn’t look into the Corps and Army files, and assumed what the attached Corps artillery strengths were. Sloppy research is embarrassing, although it does occur, especially when working under severe financial constraints (for example, our Battalion-level Operations Database). If the research is sloppy or hurried, or done from secondary sources, then hopefully the errors are random, and will effectively counterbalance each other, and not change the results of the analysis. If the errors are all in one direction, then this will produce a biased result.
I have no basis to believe that Prof. Zetterling’s criticism is wrong, and do have many reasons to believe that it is correct. Until l can take the time to go through the Corps and Army files, I intend to operate under the assumption that Prof. Zetterling’s corrections are good. At some point I will need to go back through the Italian Campaign data and correct it and update the Land Warfare Database. I did compare Prof. Zetterling‘s list of battles with what was declared to be the forces involved in the battle (according to the Combat Data Subscription Service) and they show the following attached artillery:
It is clear that the battles were based on the assumption that here was Corps-level German artillery. A strength comparison between the two sides is displayed in the chart on the next page.
The Result Formula:
CEV is calculated from three factors. Therefore a consistent 20% error in casualties will result in something less than a 20% error in CEV. The mission effectiveness factor is indeed very “fuzzy,” and these is simply no systematic method or guidance in its application. Sometimes, it is not based upon the assigned mission of the unit, but its perceived mission based upon the analyst’s interpretation. But, while l have the same problems with the mission accomplishment scores as Mr. Zetterling, I do not have a good replacement. Considering the nature of warfare, I would hate to create CEVs without it. Of course, Trevor Dupuy was experimenting with creating CEVs just from casualty effectiveness, and by averaging his two CEV scores (CEVt and CEVI) he heavily weighted the CEV calculation for the TNDM towards measuring primarily casualty effectiveness (see the article in issue 5 of the Newsletter, “Numerical Adjustment of CEV Results: Averages and Means“). At this point, I would like to produce a new, single formula for CEV to replace the current two and its averaging methodology. I am open to suggestions for this.
Supply Situation:
The different ammunition usage rate of the German and US Armies is one of the reasons why adding a logistics module is high on my list of model corrections. This was discussed in Issue 2 of the Newsletter, “Developing a Logistics Model for the TNDM.” As Mr. Zetterling points out, “It is unlikely that an increase in artillery ammunition expenditure will result in a proportional increase in combat power. Rather it is more likely that there is some kind of diminished return with increased expenditure.” This parallels what l expressed in point 12 of that article: “It is suspected that this increase [in OLIs] will not be linear.”
The CEV does include “logistics.” So in effect, if one had a good logistics module, the difference in logistics would be accounted for, and the Germans (after logistics is taken into account) may indeed have a higher CEV.
General Problems with Non-Divisional Units Tooth-to-Tail Ratio
Point taken. The engagements used to test the TNDM have been gathered over a period of over 25 years, by different researchers and controlled by different management. What is counted when and where does change from one group of engagements to the next. While l do think this has not had a significant result on the model outcomes, it is “sloppy” and needs to be addressed.
The Effects of Defensive Posture
This is a very good point. If the budget was available, my first step in “redesigning” the TNDM would be to try to measure the effects of terrain on combat through the use of a large LWDB-type database and regression analysis. I have always felt that with enough engagements, one could produce reliable values for these figures based upon something other than judgement. Prof. Zetterling’s proposed methodology is also a good approach, easier to do, and more likely to get a conclusive result. I intend to add this to my list of model improvements.
Conclusions
There is one other problem with the Italian data that Prof. Zetterling did not address. This was that the Germans and the Allies had different reporting systems for casualties. Quite simply, the Germans did not report as casualties those people who were lightly wounded and treated and returned to duty from the divisional aid station. The United States and England did. This shows up when one compares the wounded to killed ratios of the various armies, with the Germans usually having in the range of 3 to 4 wounded for every one killed, while the allies tend to have 4 to 5 wounded for every one killed. Basically, when comparing the two reports, the Germans “undercount” their casualties by around 17 to 20%. Therefore, one probably needs to use a multiplier of 20 to 25% to match the two casualty systems. This was not taken into account in any the work HERO did.
Because Trevor Dupuy used three factors for measuring his CEV, this error certainly resulted in a slightly higher CEV for the Germans than should have been the case, but not a 20% increase. As Prof. Zetterling points out, the correction of the count of artillery pieces should result in a higher CEV than Col. Dupuy calculated. Finally, if Col. Dupuy overrated the value of defensive terrain, then this may result in the German CEV being slightly lower.
As you may have noted in my list of improvements (Issue 2, “Planned Improvements to the TNDM”), I did list “revalidating” to the QJM Database. [NOTE: a summary of the QJM/TNDM validation efforts can be found here.] As part of that revalidation process, we would need to review the data used in the validation data base first, account for the casualty differences in the reporting systems, and determine if the model indeed overrates the effect of terrain on defense.
Perhaps one of the most debated results of the TNDM (and its predecessors) is the conclusion that the German ground forces on average enjoyed a measurable qualitative superiority over its US and British opponents. This was largely the result of calculations on situations in Italy in 1943-44, even though further engagements have been added since the results were first presented. The calculated German superiority over the Red Army, despite the much smaller number of engagements, has not aroused as much opposition. Similarly, the calculated Israeli effectiveness superiority over its enemies seems to have surprised few.
However, there are objections to the calculations on the engagements in Italy 1943. These concern primarily the database, but there are also some questions to be raised against the way some of the calculations have been made, which may possibly have consequences for the TNDM.
Here it is suggested that the German CEV [combat effectiveness value] superiority was higher than originally calculated. There are a number of flaws in the original calculations, each of which will be discussed separately below. With the exception of one issue, all of them, if corrected, tend to give a higher German CEV.
The Database on Italy 1943-44
According to the database the German divisions had considerable fire support from GHQ artillery units. This is the only possible conclusion from the fact that several pieces of the types 15cm gun, 17cm gun, 21cm gun, and 15cm and 21cm Nebelwerfer are included in the data for individual engagements. These types of guns were almost exclusively confined to GHQ units. An example from the database are the three engagements Port of Salerno, Amphitheater, and Sele-Calore Corridor. These take place simultaneously (9-11 September 1943) with the German 16th Pz Div on the Axis side in all of them (no other division is included in the battles). Judging from the manpower figures, it seems to have been assumed that the division participated with one quarter of its strength in each of the two former battles and half its strength in the latter. According to the database, the number of guns were:
15cm gun
28
17cm gun
12
21cm gun
12
15cm NbW
27
21cm NbW
21
This would indicate that the 16th Pz Div was supported by the equivalent of more than five non-divisional artillery battalions. For the German army this is a suspiciously high number, usually there were rather something like one GHQ artillery battalion for each division, or even less. Research in the German Military Archives confirmed that the number of GHQ artillery units was far less than indicated in the HERO database. Among the useful documents found were a map showing the dispositions of 10th Army artillery units. This showed clearly that there was only one non-divisional artillery unit south of Rome at the time of the Salerno landings, the III/71 Nebelwerfer Battalion. Also the 557th Artillery Battalion (17cm gun) was present, it was included in the artillery regiment (33rd Artillery Regiment) of 15th Panzergrenadier Division during the second half of 1943. Thus the number of German artillery pieces in these engagements is exaggerated to an extent that cannot be considered insignificant. Since OLI values for artillery usually constitute a significant share of the total OLI of a force in the TNDM, errors in artillery strength cannot be dismissed easily.
While the example above is but one, further archival research has shown that the same kind of error occurs in all the engagements in September and October 1943. It has not been possible to check the engagements later during 1943, but a pattern can be recognized. The ratio between the numbers of various types of GHQ artillery pieces does not change much from battle to battle. It seems that when the database was developed, the researchers worked with the assumption that the German corps and army organizations had organic artillery, and this assumption may have been used as a “rule of thumb.” This is wrong, however; only artillery staffs, command and control units were included in the corps and army organizations, not firing units. Consequently we have a systematic error, which cannot be corrected without changing the contents of the database. It is worth emphasizing that we are discussing an exaggeration of German artillery strength of about 100%, which certainly is significant. Comparing the available archival records with the database also reveals errors in numbers of tanks and antitank guns, but these are much smaller than the errors in artillery strength. Again these errors do always inflate the German strength in those engagements l have been able to check against archival records. These errors tend to inflate German numerical strength, which of course affects CEV calculations. But there are further objections to the CEV calculations.
The Result Formula
The “result formula” weighs together three factors: casualties inflicted, distance advanced, and mission accomplishment. It seems that the first two do not raise many objections, even though the relative weight of them may always be subject to argumentation.
The third factor, mission accomplishment, is more dubious however. At first glance it may seem to be natural to include such a factor. Alter all, a combat unit is supposed to accomplish the missions given to it. However, whether a unit accomplishes its mission or not depends both on its own qualities as well as the realism of the mission assigned. Thus the mission accomplishment factor may reflect the qualities of the combat unit as well as the higher HQs and the general strategic situation. As an example, the Rapido crossing by the U.S. 36th Infantry Division can serve. The division did not accomplish its mission, but whether the mission was realistic, given the circumstances, is dubious. Similarly many German units did probably, in many situations, receive unrealistic missions, particularly during the last two years of the war (when most of the engagements in the database were fought). A more extreme example of situations in which unrealistic missions were given is the battle in Belorussia, June-July 1944, where German units were regularly given impossible missions. Possibly it is a general trend that the side which is fighting at a strategic disadvantage is more prone to give its combat units unrealistic missions.
On the other hand it is quite clear that the mission assigned may well affect both the casualty rates and advance rates. If, for example, the defender has a withdrawal mission, advance may become higher than if the mission was to defend resolutely. This must however not necessarily be handled by including a missions factor in a result formula.
I have made some tentative runs with the TNDM, testing with various CEV values to see which value produced an outcome in terms of casualties and ground gained as near as possible to the historical result. The results of these runs are very preliminary, but the tendency is that higher German CEVs produce more historical outcomes, particularly concerning combat.
Supply Situation
According to scattered information available in published literature, the U.S. artillery fired more shells per day per gun than did German artillery. In Normandy, US 155mm M1 howitzers fired 28.4 rounds per day during July, while August showed slightly lower consumption, 18 rounds per day. For the 105mm M2 howitzer the corresponding figures were 40.8 and 27.4. This can be compared to a German OKH study which, based on the experiences in Russia 1941-43, suggested that consumption of 105mm howitzer ammunition was about 13-22 rounds per gun per day, depending on the strength of the opposition encountered. For the 150mm howitzer the figures were 12-15.
While these figures should not be taken too seriously, as they are not from primary sources and they do also reflect the conditions in different theaters, they do at least indicate that it cannot be taken for granted that ammunition expenditure is proportional to the number of gun barrels. In fact there also exist further indications that Allied ammunition expenditure was greater than the German. Several German reports from Normandy indicate that they were astonished by the Allied ammunition expenditure.
It is unlikely that an increase in artillery ammunition expenditure will result in a proportional increase combat power. Rather it is more likely that there is some kind of diminished return with increased expenditure.
General Problems with Non-Divisional Units
A division usually (but not necessarily) includes various support services, such as maintenance, supply, and medical services. Non-divisional combat units have to a greater extent to rely on corps and army for such support. This makes it complicated to include such units, since when entering, for example, the manpower strength and truck strength in the TNDM, it is difficult to assess their contribution to the overall numbers.
Furthermore, the amount of such forces is not equal on the German and Allied sides. In general the Allied divisional slice was far greater than the German. In Normandy the US forces on 25 July 1944 had 812,000 men on the Continent, while the number of divisions was 18 (including the 5th Armored, which was in the process of landing on the 25th). This gives a divisional slice of 45,000 men. By comparison the German 7th Army mustered 16 divisions and 231,000 men on 1 June 1944, giving a slice of 14,437 men per division. The main explanation for the difference is the non-divisional combat units and the logistical organization to support them. In general, non-divisional combat units are composed of powerful, but supply-consuming, types like armor, artillery, antitank and antiaircraft. Thus their contribution to combat power and strain on the logistical apparatus is considerable. However I do not believe that the supporting units’ manpower and vehicles have been included in TNDM calculations.
There are however further problems with non-divisional units. While the whereabouts of tank and tank destroyer units can usually be established with sufficient certainty, artillery can be much harder to pin down to a specific division engagement. This is of course a greater problem when the geographical extent of a battle is small.
Tooth-to-Tail Ratio
Above was discussed the lack of support units in non-divisional combat units. One effect of this is to create a force with more OLI per man. This is the result of the unit‘s “tail” belonging to some other part of the military organization.
In the TNDM there is a mobility formula, which tends to favor units with many weapons and vehicles compared to the number of men. This became apparent when I was performing a great number of TNDM runs on engagements between Swedish brigades and Soviet regiments. The Soviet regiments usually contained rather few men, but still had many AFVs, artillery tubes, AT weapons, etc. The Mobility Formula in TNDM favors such units. However, I do not think this reflects any phenomenon in the real world. The Soviet penchant for lean combat units, with supply, maintenance, and other services provided by higher echelons, is not a more effective solution in general, but perhaps better suited to the particular constraints they were experiencing when forming units, training men, etc. In effect these services were existing in the Soviet army too, but formally not with the combat units.
This problem is to some extent reminiscent to how density is calculated (a problem discussed by Chris Lawrence in a recent issue of the Newsletter). It is comparatively easy to define the frontal limit of the deployment area of force, and it is relatively easy to define the lateral limits too. It is, however, much more difficult to say where the rear limit of a force is located.
When entering forces in the TNDM a rear limit is, perhaps unintentionally, drawn. But if the combat unit includes support units, the rear limit is pushed farther back compared to a force whose combat units are well separated from support units.
To what extent this affects the CEV calculations is unclear. Using the original database values, the German forces are perhaps given too high combat strength when the great number of GHQ artillery units is included. On the other hand, if the GHQ artillery units are not included, the opposite may be true.
The Effects of Defensive Posture
The posture factors are difficult to analyze, since they alone do not portray the advantages of defensive position. Such effects are also included in terrain factors.
It seems that the numerical values for these factors were assigned on the basis of professional judgement. However, when the QJM was developed, it seems that the developers did not assume the German CEV superiority. Rather, the German CEV superiority seems to have been discovered later. It is possible that the professional judgement was about as wrong on the issue of posture effects as they were on CEV. Since the British and American forces were predominantly on the offensive, while the Germans mainly defended themselves, a German CEV superiority may, at least partly, be hidden in two high effects for defensive posture.
When using corrected input data on the 20 situations in Italy September-October 1943, there is a tendency that the German CEV is higher when they attack. Such a tendency is also discernible in the engagements presented in Hitler’s Last Gamble. Appendix H, even though the number of engagements in the latter case is very small.
As it stands now this is not really more than a hypothesis, since it will take an analysis of a greater number of engagements to confirm it. However, if such an analysis is done, it must be done using several sets of data. German and Allied attacks must be analyzed separately, and preferably the data would be separated further into sets for each relevant terrain type. Since the effects of the defensive posture are intertwined with terrain factors, it is very much possible that the factors may be correct for certain terrain types, while they are wrong for others. It may also be that the factors can be different for various opponents (due to differences in training, doctrine, etc.). It is also possible that the factors are different if the forces are predominantly composed of armor units or mainly of infantry.
One further problem with the effects of defensive position is that it is probably strongly affected by the density of forces. It is likely that the main effect of the density of forces is the inability to use effectively all the forces involved. Thus it may be that this factor will not influence the outcome except when the density is comparatively high. However, what can be regarded as “high” is probably much dependent on terrain, road net quality, and the cross-country mobility of the forces.
Conclusions
While the TNDM has been criticized here, it is also fitting to praise the model. The very fact that it can be criticized in this way is a testimony to its openness. In a sense a model is also a theory, and to use Popperian terminology, the TNDM is also very testable.
It should also be emphasized that the greatest errors are probably those in the database. As previously stated, I can only conclude safely that the data on the engagements in Italy in 1943 are wrong; later engagements have not yet been checked against archival documents. Overall the errors do not represent a dramatic change in the CEV values. Rather, the Germans seem to have (in Italy 1943) a superiority on the order of 1.4-1.5, compared to an original figure of 1.2-1.3.
During September and October 1943, almost all the German divisions in southern Italy were mechanized or parachute divisions. This may have contributed to a higher German CEV. Thus it is not certain that the conclusions arrived at here are valid for German forces in general, even though this factor should not be exaggerated, since many of the German divisions in Italy were either newly raised (e.g., 26th Panzer Division) or rebuilt after the Stalingrad disaster (16th Panzer Division plus 3rd and 29th Panzergrenadier Divisions) or the Tunisian debacle (15th Panzergrenadier Division).
Jeffrey H Michaels, a Senior Lecturer in Defence Studies at the British the Joint Services Command and Staff College, has published a detailed look at how Hackett and several senior NATO and diplomatic colleagues constructed the scenario portrayed in the book. Scenario construction is an important aspect of institutional war gaming. A war game will only be as useful if the assumptions that underpin it are valid. As Michaels points out,
Regrettably, far too many scenarios and models, whether developed by military organizations, political scientists, or fiction writers, tend to focus their attention on the battlefield and the clash of armies, navies, air forces, and especially their weapons systems. By contrast, the broader context of the war – the reasons why hostilities erupted, the political and military objectives, the limits placed on military action, and so on – are given much less serious attention, often because they are viewed by the script-writers as a distraction from the main activity that occurs on the battlefield.
Modelers and war gamers always need to keep in mind the fundamental importance of context in designing their simulations.
It is quite easy to project how one weapon system might fare against another, but taken out of a broader strategic context, such a projection is practically meaningless (apart from its marketing value), or worse, misleading. In this sense, even if less entertaining or exciting, the degree of realism of the political aspects of the scenario, particularly policymakers’ rationality and cost-benefit calculus, and the key decisions that are taken about going to war, the objectives being sought, the limits placed on military action, and the willingness to incur the risks of escalation, should receive more critical attention than the purely battlefield dimensions of the future conflict.
These are crucially important points to consider when deciding how to asses the outcomes of hypothetical scenarios.
Consistent Scoring of Weapons and Aggregation of Forces: The Cornerstone of Dupuy’s Quantitative Analysis of Historical Land Battles by
James G. Taylor, PhD,
Dept. of Operations Research, Naval Postgraduate School
Introduction
Col. Trevor N. Dupuy was an American original, especially as regards the quantitative study of warfare. As with many prophets, he was not entirely appreciated in his own land, particularly its Military Operations Research (OR) community. However, after becoming rather familiar with the details of his mathematical modeling of ground combat based on historical data, I became aware of the basic scientific soundness of his approach. Unfortunately, his documentation of methodology was not always accepted by others, many of whom appeared to confuse lack of mathematical sophistication in his documentation with lack of scientific validity of his basic methodology.
The purpose of this brief paper is to review the salient points of Dupuy’s methodology from a system’s perspective, i.e., to view his methodology as a system, functioning as an organic whole to capture the essence of past combat experience (with an eye towards extrapolation into the future). The advantage of this perspective is that it immediately leads one to the conclusion that if one wants to use some functional relationship derived from Dupuy’s work, then one should use his methodologies for scoring weapons, aggregating forces, and adjusting for operational circumstances; since this consistency is the only guarantee of being able to reproduce historical results and to project them into the future.
Implications (of this system’s perspective on Dupuy’s work) for current DOD models will be discussed. In particular, the Military OR community has developed quantitative methods for imputing values to weapon systems based on their attrition capability against opposing forces and force interactions.[1] One such approach is the so-called antipotential-potential method[2] used in TACWAR[3] to score weapons. However, one should not expect such scores to provide valid casualty estimates when combined with historically derived functional relationships such as the so-called ATLAS casualty-rate curves[4] used in TACWAR, because a different “yard-stick” (i.e. measuring system for estimating the relative combat potential of opposing forces) was used to develop such a curve.
Overview of Dupuy’s Approach
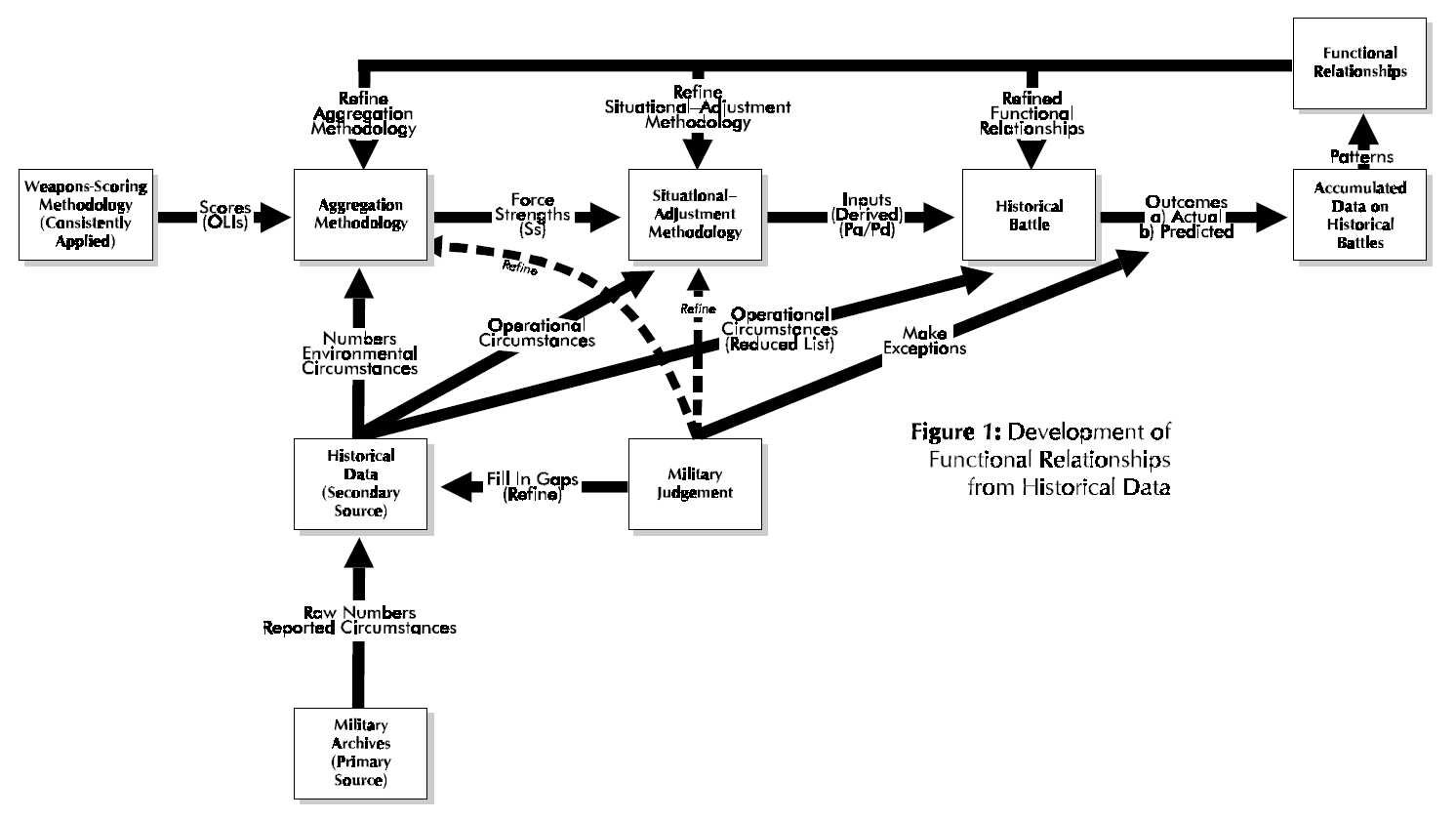
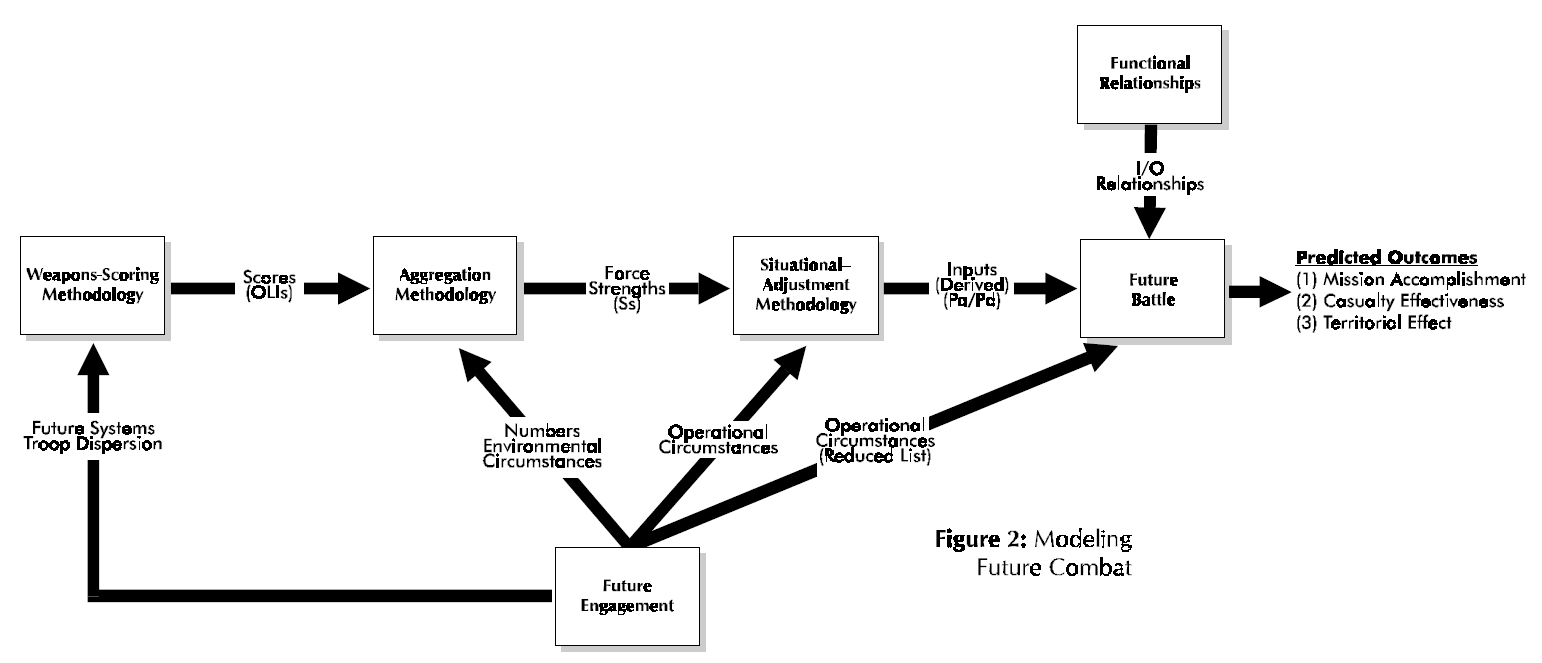
This section briefly outlines the salient features of Dupuy’s approach to the quantitative analysis and modeling of ground combat as embodied in his Tactical Numerical Deterministic Model (TNDM) and its predecessor the Quantified Judgment Model (QJM). The interested reader can find details in Dupuy [1979] (see also Dupuy [1985][5], [1987], [1990]). Here we will view Dupuy’s methodology from a system approach, which seeks to discern its various components and their interactions and to view these components as an organic whole. Essentially Dupuy’s approach involves the development of functional relationships from historical combat data (see Fig. 1) and then using these functional relationships to model future combat (see Fig, 2).
At the heart of Dupuy’s method is the investigation of historical battles and comparing the relationship of inputs (as quantified by relative combat power, denoted as Pa/Pd for that of the attacker relative to that of the defender in Fig. l)(e.g. see Dupuy [1979, pp. 59-64]) to outputs (as quantified by extent of mission accomplishment, casualty effectiveness, and territorial effectiveness; see Fig. 2) (e.g. see Dupuy [1979, pp. 47-50]), The salient point is that within this scheme, the main input[6] (i.e. relative combat power) to a historical battle is a derived quantity. It is computed from formulas that involve three essential aspects: (1) the scoring of weapons (e.g, see Dupuy [1979, Chapter 2 and also Appendix A]), (2) aggregation methodology for a force (e.g. see Dupuy [1979, pp. 43-46 and 202-203]), and (3) situational-adjustment methodology for determining the relative combat power of opposing forces (e.g. see Dupuy [1979, pp. 46-47 and 203-204]). In the force-aggregation step the effects on weapons of Dupuy’s environmental variables and one operational variable (air superiority) are considered[7], while in the situation-adjustment step the effects on forces of his behavioral variables[8] (aggregated into a single factor called the relative combat effectiveness value (CEV)) and also the other operational variables are considered (Dupuy [1987, pp. 86-89])
Figure 1.
Moreover, any functional relationships developed by Dupuy depend (unless shown otherwise) on his computational system for derived quantities, namely OLls, force strengths, and relative combat power. Thus, Dupuy’s results depend in an essential manner on his overall computational system described immediately above. Consequently, any such functional relationship (e.g. casualty-rate curve) directly or indirectly derivative from Dupuy‘s work should still use his computational methodology for determination of independent-variable values.
Fig l also reveals another important aspect of Dupuy’s work, the development of reliable data on historical battles, Military judgment plays an essential role in this development of such historical data for a variety of reasons. Dupuy was essentially the only source of new secondary historical data developed from primary sources (see McQuie [1970] for further details). These primary sources are well known to be both incomplete and inconsistent, so that military judgment must be used to fill in the many gaps and reconcile observed inconsistencies. Moreover, military judgment also generates the working hypotheses for model development (e.g. identification of significant variables).
At the heart of Dupuy’s quantitative investigation of historical battles and subsequent model development is his own weapons-scoring methodology, which slowly evolved out of study efforts by the Historical Evaluation Research Organization (HERO) and its successor organizations (cf. HERO [1967] and compare with Dupuy [1979]). Early HERO [1967, pp. 7-8] work revealed that what one would today call weapons scores developed by other organizations were so poorly documented that HERO had to create its own methodology for developing the relative lethality of weapons, which eventually evolved into Dupuy’s Operational Lethality Indices (OLIs). Dupuy realized that his method was arbitrary (as indeed is its counterpart, called the operational definition, in formal scientific work), but felt that this would be ameliorated if the weapons-scoring methodology be consistently applied to historical battles. Unfortunately, this point is not clearly stated in Dupuy’s formal writings, although it was clearly (and compellingly) made by him in numerous briefings that this author heard over the years.
Figure 2.
In other words, from a system’s perspective, the functional relationships developed by Colonel Dupuy are part of his analysis system that includes this weapons-scoring methodology consistently applied (see Fig. l again). The derived functional relationships do not stand alone (unless further empirical analysis shows them to hold for any weapons-scoring methodology), but function in concert with computational procedures. Another essential part of this system is Dupuy‘s aggregation methodology, which combines numbers, environmental circumstances, and weapons scores to compute the strength (S) of a military force. A key innovation by Colonel Dupuy [1979, pp. 202- 203] was to use a nonlinear (more precisely, a piecewise-linear) model for certain elements of force strength. This innovation precluded the occurrence of military absurdities such as air firepower being fully substitutable for ground firepower, antitank weapons being fully effective when armor targets are lacking, etc‘ The final part of this computational system is Dupuy’s situational-adjustment methodology, which combines the effects of operational circumstances with force strengths to determine relative combat power, e.g. Pa/Pd.
To recapitulate, the determination of an Operational Lethality Index (OLI) for a weapon involves the combination of weapon lethality, quantified in terms of a Theoretical Lethality Index (TLI) (e.g. see Dupuy [1987, p. 84]), and troop dispersion[9] (e.g. see Dupuy [1987, pp. 84- 85]). Weapons scores (i.e. the OLIs) are then combined with numbers (own side and enemy) and combat- environment factors to yield force strength. Six[10] different categories of weapons are aggregated, with nonlinear (i.e. piecewise-linear) models being used for the following three categories of weapons: antitank, air defense, and air firepower (i.e. c1ose—air support). Operational, e.g. mobility, posture, surprise, etc. (Dupuy [1987, p. 87]), and behavioral variables (quantified as a relative combat effectiveness value (CEV)) are then applied to force strength to determine a side’s combat-power potential.
Requirement for Consistent Scoring of Weapons, Force Aggregation, and Situational Adjustment for Operational Circumstances
The salient point to be gleaned from Fig.1 and 2 is that the same (or at least consistent) weapons—scoring, aggregation, and situational—adjustment methodologies be used for both developing functional relationships and then playing them to model future combat. The corresponding computational methods function as a system (organic whole) for determining relative combat power, e.g. Pa/Pd. For the development of functional relationships from historical data, a force ratio (relative combat power of the two opposing sides, e.g. attacker’s combat power divided by that of the defender, Pa/Pd is computed (i.e. it is a derived quantity) as the independent variable, with observed combat outcome being the dependent variable. Thus, as discussed above, this force ratio depends on the methodologies for scoring weapons, aggregating force strengths, and adjusting a force’s combat power for the operational circumstances of the engagement. It is a priori not clear that different scoring, aggregation, and situational-adjustment methodologies will lead to similar derived values. If such different computational procedures were to be used, these derived values should be recomputed and the corresponding functional relationships rederived and replotted.
However, users of the Tactical Numerical Deterministic Model (TNDM) (or for that matter, its predecessor, the Quantified Judgment Model (QJM)) need not worry about this point because it was apparently meticulously observed by Colonel Dupuy in all his work. However, portions of his work have found their way into a surprisingly large number of DOD models (usually not explicitly acknowledged), but the context and range of validity of historical results have been largely ignored by others. The need for recalibration of the historical data and corresponding functional relationships has not been considered in applying Dupuy’s results for some important current DOD models.
Implications for Current DOD Models
A number of important current DOD models (namely, TACWAR and JICM discussed below) make use of some of Dupuy’s historical results without recalibrating functional relationships such as loss rates and rates of advance as a function of some force ratio (e.g. Pa/Pd). As discussed above, it is not clear that such a procedure will capture the essence of past combat experience. Moreover, in calculating losses, Dupuy first determines personnel losses (expressed as a percent loss of personnel strength, i.e., number of combatants on a side) and then calculates equipment losses as a function of this casualty rate (e.g., see Dupuy [1971, pp. 219-223], also [1990, Chapters 5 through 7][11]). These latter functional relationships are apparently not observed in the models discussed below. In fact, only Dupuy (going back to Dupuy [1979][12] takes personnel losses to depend on a force ratio and other pertinent variables, with materiel losses being taken as derivative from this casualty rate.
For example, TACWAR determines personnel losses[13] by computing a force ratio and then consulting an appropriate casualty-rate curve (referred to as empirical data), much in the same fashion as ATLAS did[14]. However, such a force ratio is computed using a linear model with weapon values determined by the so-called antipotential-potential method[15]. Unfortunately, this procedure may not be consistent with how the empirical data (i.e. the casualty-rate curves) was developed. Further research is required to demonstrate that valid casualty estimates are obtained when different weapon scoring, aggregation, and situational-adjustment methodologies are used to develop casualty-rate curves from historical data and to use them to assess losses in aggregated combat models. Furthermore, TACWAR does not use Dupuy’s model for equipment losses (see above), although it does purport, as just noted above, to use “historical data” (e.g., see Kerlin et al. [1975, p. 22]) to compute personnel losses as a function (among other things) of a force ratio (given by a linear relationship), involving close air support values in a way never used by Dupuy. Although their force-ratio determination methodology does have logical and mathematical merit, it is not the way that the historical data was developed.
Moreover, RAND (Allen [1992]) has more recently developed what is called the situational force scoring (SFS) methodology for calculating force ratios in large-scale, aggregated-force combat situations to determine loss and movement rates. Here, SFS refers essentially to a force- aggregation and situation-adjustment methodology, which has many conceptual elements in common with Dupuy‘s methodology (except, most notably, extensive testing against historical data, especially documentation of such efforts). This SFS was originally developed for RSAS[16] and is today used in JICM[17]. It also apparently uses a weapon-scoring system developed at RAND[18]. It purports (no documentation given [citation of unpublished work]) to be consistent with historical data (including the ATLAS casualty-rate curves) (Allen [1992, p.41]), but again no consideration is given to recalibration of historical results for different weapon scoring, force-aggregation, and situational-adjustment methodologies. SFS emphasizes adjusting force strengths according to operational circumstances (the “situation”) of the engagement (including surprise), with many innovative ideas (but in some major ways has little connection with previous work of others[19]). The resulting model contains many more details than historical combat data would support. It also is methodology that differs in many essential ways from that used previously by any investigator. In particular, it is doubtful that it develops force ratios in a manner consistent with Dupuy’s work.
Final Comments
Use of (sophisticated) mathematics for modeling past historical combat (and extrapolating it into the future for planning purposes) is no reason for ignoring Dupuy’s work. One would think that the current Military OR community would try to understand Dupuy’s work before trying to improve and extend it. In particular, Colonel Dupuy’s various computational procedures (including constants) must be considered as an organic whole (i.e. a system) supporting the development of functional relationships. If one ignores this computational system and simply tries to use some isolated aspect, the result may be interesting and even logically sound, but it probably lacks any scientific validity.
REFERENCES
P. Allen, “Situational Force Scoring: Accounting for Combined Arms Effects in Aggregate Combat Models,” N-3423-NA, The RAND Corporation, Santa Monica, CA, 1992.
L. B. Anderson, “A Briefing on Anti-Potential Potential (The Eigen-value Method for Computing Weapon Values), WP-2, Project 23-31, Institute for Defense Analyses, Arlington, VA, March 1974.
B. W. Bennett, et al, “RSAS 4.6 Summary,” N-3534-NA, The RAND Corporation, Santa Monica, CA, 1992.
B. W. Bennett, A. M. Bullock, D. B. Fox, C. M. Jones, J. Schrader, R. Weissler, and B. A. Wilson, “JICM 1.0 Summary,” MR-383-NA, The RAND Corporation, Santa Monica, CA, 1994.
P. K. Davis and J. A. Winnefeld, “The RAND Strategic Assessment Center: An Overview and Interim Conclusions About Utility and Development Options,” R-2945-DNA, The RAND Corporation, Santa Monica, CA, March 1983.
T.N, Dupuy, Numbers. Predictions and War: Using History to Evaluate Combat Factors and Predict the Outcome of Battles, The Bobbs-Merrill Company, Indianapolis/New York, 1979,
T.N. Dupuy, Numbers Predictions and War, Revised Edition, HERO Books, Fairfax, VA 1985.
T.N. Dupuy, Understanding War: History and Theory of Combat, Paragon House Publishers, New York, 1987.
T.N. Dupuy, Attrition: Forecasting Battle Casualties and Equipment Losses in Modem War, HERO Books, Fairfax, VA, 1990.
General Research Corporation (GRC), “A Hierarchy of Combat Analysis Models,” McLean, VA, January 1973.
Historical Evaluation and Research Organization (HERO), “Average Casualty Rates for War Games, Based on Historical Data,” 3 Volumes in 1, Dunn Loring, VA, February 1967.
E. P. Kerlin and R. H. Cole, “ATLAS: A Tactical, Logistical, and Air Simulation: Documentation and User’s Guide,” RAC-TP-338, Research Analysis Corporation, McLean, VA, April 1969 (AD 850 355).
E.P. Kerlin, L.A. Schmidt, A.J. Rolfe, M.J. Hutzler, and D,L. Moody, “The IDA Tactical Warfare Model: A Theater-Level Model of Conventional, Nuclear, and Chemical Warfare, Volume II- Detailed Description” R-21 1, Institute for Defense Analyses, Arlington, VA, October 1975 (AD B009 692L).
R. McQuie, “Military History and Mathematical Analysis,” Military Review 50, No, 5, 8-17 (1970).
S.M. Robinson, “Shadow Prices for Measures of Effectiveness, I: Linear Model,” Operations Research 41, 518-535 (1993).
J.G. Taylor, Lanchester Models of Warfare. Vols, I & II. Operations Research Society of America, Alexandria, VA, 1983. (a)
J.G. Taylor, “A Lanchester-Type Aggregated-Force Model of Conventional Ground Combat,” Naval Research Logistics Quarterly 30, 237-260 (1983). (b)
NOTES
[1] For example, see Taylor [1983a, Section 7.18], which contains a number of examples. The basic references given there may be more accessible through Robinson [I993].
[2] This term was apparently coined by L.B. Anderson [I974] (see also Kerlin et al. [1975, Chapter I, Section D.3]).
[3] The Tactical Warfare (TACWAR) model is a theater-level, joint-warfare, computer-based combat model that is currently used for decision support by the Joint Staff and essentially all CINC staffs. It was originally developed by the Institute for Defense Analyses in the mid-1970s (see Kerlin et al. [1975]), originally referred to as TACNUC, which has been continually upgraded until (and including) the present day.
[4] For example, see Kerlin and Cole [1969], GRC [1973, Fig. 6-6], or Taylor [1983b, Fig. 5] (also Taylor [1983a, Section 7.13]).
[5] The only apparent difference between Dupuy [1979] and Dupuy [1985] is the addition of an appendix (Appendix C “Modified Quantified Judgment Analysis of the Bekaa Valley Battle”) to the end of the latter (pp. 241-251). Hence, the page content is apparently the same for these two books for pp. 1-239.
[6] Technically speaking, one also has the engagement type and possibly several other descriptors (denoted in Fig. 1 as reduced list of operational circumstances) as other inputs to a historical battle.
[7] In Dupuy [1979, e.g. pp. 43-46] only environmental variables are mentioned, although basically the same formulas underlie both Dupuy [1979] and Dupuy [1987]. For simplicity, Fig. 1 and 2 follow this usage and employ the term “environmental circumstances.”
[8] In Dupuy [1979, e.g. pp. 46-47] only operational variables are mentioned, although basically the same formulas underlie both Dupuy [1979] and Dupuy [1987]. For simplicity, Fig. 1 and 2 follow this usage and employ the term “operational circumstances.”
[9] Chris Lawrence has kindly brought to my attention that since the same value for troop dispersion from an historical period (e.g. see Dupuy [1987, p. 84]) is used for both the attacker and also the defender, troop dispersion does not actually affect the determination of relative combat power PM/Pd.
[10] Eight different weapon types are considered, with three being classified as infantry weapons (e.g. see Dupuy [1979, pp, 43-44], [1981 pp. 85-86]).
[11] Chris Lawrence has kindly informed me that Dupuy‘s work on relating equipment losses to personnel losses goes back to the early 1970s and even earlier (e.g. see HERO [1966]). Moreover, Dupuy‘s [1992] book Future Wars gives some additional empirical evidence concerning the dependence of equipment losses on casualty rates.
[12] But actually going back much earlier as pointed out in the previous footnote.
[13] See Kerlin et al. [1975, Chapter I, Section D.l].
[14] See Footnote 4 above.
[15] See Kerlin et al. [1975, Chapter I, Section D.3]; see also Footnotes 1 and 2 above.
[16] The RAND Strategy Assessment System (RSAS) is a multi-theater aggregated combat model developed at RAND in the early l980s (for further details see Davis and Winnefeld [1983] and Bennett et al. [1992]). It evolved into the Joint Integrated Contingency Model (JICM), which is a post-Cold War redesign of the RSAS (starting in FY92).
[17] The Joint Integrated Contingency Model (JICM) is a game-structured computer-based combat model of major regional contingencies and higher-level conflicts, covering strategic mobility, regional conventional and nuclear warfare in multiple theaters, naval warfare, and strategic nuclear warfare (for further details, see Bennett et al. [1994]).
[18] RAND apparently replaced one weapon-scoring system by another (e.g. see Allen [1992, pp. 9, l5, and 87-89]) without making any other changes in their SFS System.
[19] For example, both Dupuy’s early HERO work (e.g. see Dupuy [1967]), reworks of these results by the Research Analysis Corporation (RAC) (e.g. see RAC [1973, Fig. 6-6]), and Dupuy’s later work (e.g. see Dupuy [1979]) considered daily fractional casualties for the attacker and also for the defender as basic casualty-outcome descriptors (see also Taylor [1983b]). However, RAND does not do this, but considers the defender’s loss rate and a casualty exchange ratio as being the basic casualty-production descriptors (Allen [1992, pp. 41-42]). The great value of using the former set of descriptors (i.e. attacker and defender fractional loss rates) is that not only is casualty assessment more straight forward (especially development of functional relationships from historical data) but also qualitative model behavior is readily deduced (see Taylor [1983b] for further details).
Allied force dispositions at the Battle of Anzio, on 1 February 1944. [U.S. Army/Wikipedia]
[The article below is reprinted from History, Numbers And War: A HERO Journal, Vol. 1, No. 1, Spring 1977, pp. 34-52]
The Lanchester Equations and Historical Warfare: An Analysis of Sixty World War II Land Engagements
By Janice B. Fain
Background and Objectives
The method by which combat losses are computed is one of the most critical parts of any combat model. The Lanchester equations, which state that a unit’s combat losses depend on the size of its opponent, are widely used for this purpose.
In addition to their use in complex dynamic simulations of warfare, the Lanchester equations have also sewed as simple mathematical models. In fact, during the last decade or so there has been an explosion of theoretical developments based on them. By now their variations and modifications are numerous, and “Lanchester theory” has become almost a separate branch of applied mathematics. However, compared with the effort devoted to theoretical developments, there has been relatively little empirical testing of the basic thesis that combat losses are related to force sizes.
One of the first empirical studies of the Lanchester equations was Engel’s classic work on the Iwo Jima campaign in which he found a reasonable fit between computed and actual U.S. casualties (Note 1). Later studies were somewhat less supportive (Notes 2 and 3), but an investigation of Korean war battles showed that, when the simulated combat units were constrained to follow the tactics of their historical counterparts, casualties during combat could be predicted to within 1 to 13 percent (Note 4).
Taken together, these various studies suggest that, while the Lanchester equations may be poor descriptors of large battles extending over periods during which the forces were not constantly in combat, they may be adequate for predicting losses while the forces are actually engaged in fighting. The purpose of the work reported here is to investigate 60 carefully selected World War II engagements. Since the durations of these battles were short (typically two to three days), it was expected that the Lanchester equations would show a closer fit than was found in studies of larger battles. In particular, one of the objectives was to repeat, in part, Willard’s work on battles of the historical past (Note 3).
The Data Base
Probably the most nearly complete and accurate collection of combat data is the data on World War II compiled by the Historical Evaluation and Research Organization (HERO). From their data HERO analysts selected, for quantitative analysis, the following 60 engagements from four major Italian campaigns:
Salerno, 9-18 Sep 1943, 9 engagements
Volturno, 12 Oct-8 Dec 1943, 20 engagements
Anzio, 22 Jan-29 Feb 1944, 11 engagements
Rome, 14 May-4 June 1944, 20 engagements
The complete data base is described in a HERO report (Note 5). The work described here is not the first analysis of these data. Statistical analyses of weapon effectiveness and the testing of a combat model (the Quantified Judgment Method, QJM) have been carried out (Note 6). The work discussed here examines these engagements from the viewpoint of the Lanchester equations to consider the question: “Are casualties during combat related to the numbers of men in the opposing forces?”
The variables chosen for this analysis are shown in Table 1. The “winners” of the engagements were specified by HERO on the basis of casualties suffered, distance advanced, and subjective estimates of the percentage of the commander’s objective achieved. Variable 12, the Combat Power Ratio, is based on the Operational Lethality Indices (OLI) of the units (Note 7).
The general characteristics of the engagements are briefly described. Of the 60, there were 19 attacks by British forces, 28 by U.S. forces, and 13 by German forces. The attacker was successful in 34 cases; the defender, in 23; and the outcomes of 3 were ambiguous. With respect to terrain, 19 engagements occurred in flat terrain; 24 in rolling, or intermediate, terrain; and 17 in rugged, or difficult, terrain. Clear weather prevailed in 40 cases; 13 engagements were fought in light or intermittent rain; and 7 in medium or heavy rain. There were 28 spring and summer engagements and 32 fall and winter engagements.
Comparison of World War II Engagements With Historical Battles
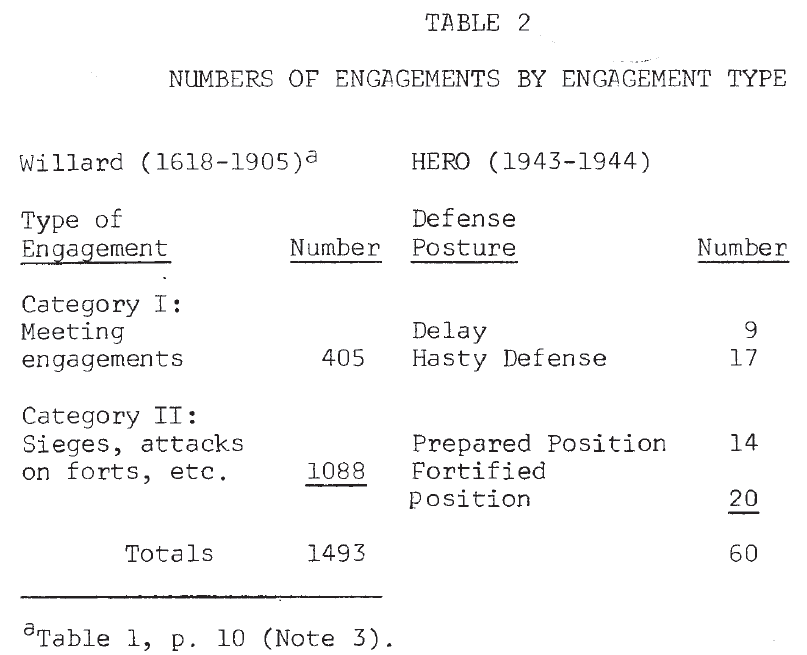
Since one purpose of this work is to repeat, in part, Willard’s analysis, comparison of these World War II engagements with the historical battles (1618-1905) studied by him will be useful. Table 2 shows a comparison of the distribution of battles by type. Willard’s cases were divided into two categories: I. meeting engagements, and II. sieges, attacks on forts, and similar operations. HERO’s World War II engagements were divided into four types based on the posture of the defender: 1. delay, 2. hasty defense, 3. prepared position, and 4. fortified position. If postures 1 and 2 are considered very roughly equivalent to Willard’s category I, then in both data sets the division into the two gross categories is approximately even.
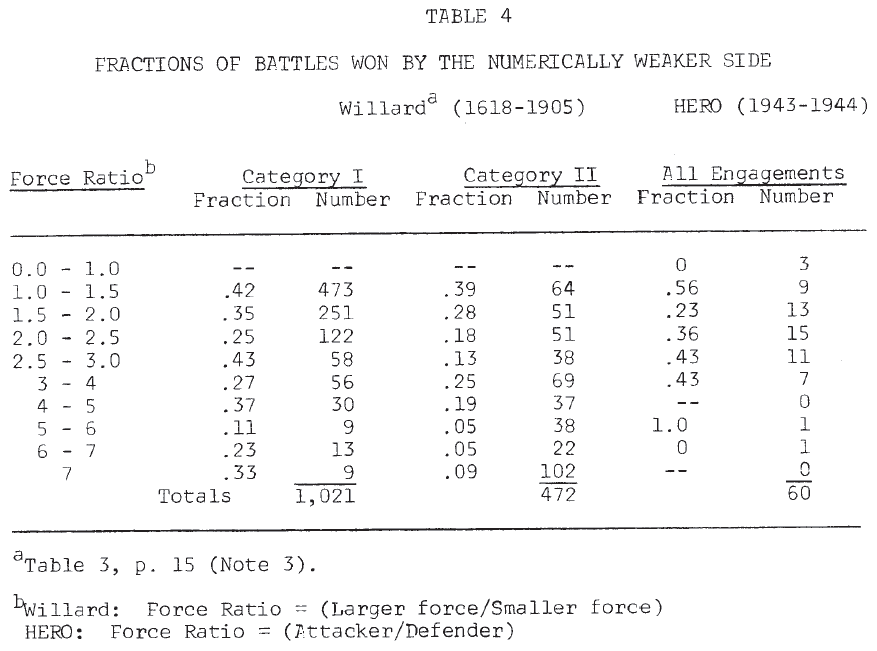
The distribution of engagements across force ratios, given in Table 3, indicated some differences. Willard’s engagements tend to cluster at the lower end of the scale (1-2) and at the higher end (4 and above), while the majority of the World War II engagements were found in mid-range (1.5 – 4) (Note 8). The frequency with which the numerically inferior force achieved victory is shown in Table 4. It is seen that in neither data set are force ratios good predictors of success in battle (Note 9).
Table 3.
Results of the Analysis Willard’s Correlation Analysis
There are two forms of the Lanchester equations. One represents the case in which firing units on both sides know the locations of their opponents and can shift their fire to a new target when a “kill” is achieved. This leads to the “square” law where the loss rate is proportional to the opponent’s size. The second form represents that situation in which only the general location of the opponent is known. This leads to the “linear” law in which the loss rate is proportional to the product of both force sizes.
As Willard points out, large battles are made up of many smaller fights. Some of these obey one law while others obey the other, so that the overall result should be a combination of the two. Starting with a general formulation of Lanchester’s equations, where g is the exponent of the target unit’s size (that is, g is 0 for the square law and 1 for the linear law), he derives the following linear equation:
log (nc/mc) = log E + g log (mo/no) (1)
where nc and mc are the casualties, E is related to the exchange ratio, and mo and no are the initial force sizes. Linear regression produces a value for g. However, instead of lying between 0 and 1, as expected, the) g‘s range from -.27 to -.87, with the majority lying around -.5. (Willard obtains several values for g by dividing his data base in various ways—by force ratio, by casualty ratio, by historical period, and so forth.) A negative g value is unpleasant. As Willard notes:
Military theorists should be disconcerted to find g < 0, for in this range the results seem to imply that if the Lanchester formulation is valid, the casualty-producing power of troops increases as they suffer casualties (Note 3).
From his results, Willard concludes that his analysis does not justify the use of Lanchester equations in large-scale situations (Note 10).
Analysis of the World War II Engagements
Willard’s computations were repeated for the HERO data set. For these engagements, regression produced a value of -.594 for g (Note 11), in striking agreement with Willard’s results. Following his reasoning would lead to the conclusion that either the Lanchester equations do not represent these engagements, or that the casualty producing power of forces increases as their size decreases.
However, since the Lanchester equations are so convenient analytically and their use is so widespread, it appeared worthwhile to reconsider this conclusion. In deriving equation (1), Willard used binomial expansions in which he retained only the leading terms. It seemed possible that the poor results might he due, in part, to this approximation. If the first two terms of these expansions are retained, the following equation results:
log (nc/mc) = log E + log (Mo-mc)/(no-nc) (2)
Repeating this regression on the basis of this equation leads to g = -.413 (Note 12), hardly an improvement over the initial results.
A second attempt was made to salvage this approach. Starting with raw OLI scores (Note 7), HERO analysts have computed “combat potentials” for both sides in these engagements, taking into account the operational factors of posture, vulnerability, and mobility; environmental factors like weather, season, and terrain; and (when the record warrants) psychological factors like troop training, morale, and the quality of leadership. Replacing the factor (mo/no) in Equation (1) by the combat power ratio produces the result) g = .466 (Note 13).
While this is an apparent improvement in the value of g, it is achieved at the expense of somewhat distorting the Lanchester concept. It does preserve the functional form of the equations, but it requires a somewhat strange definition of “killing rates.”
Analysis Based on the Differential Lanchester Equations
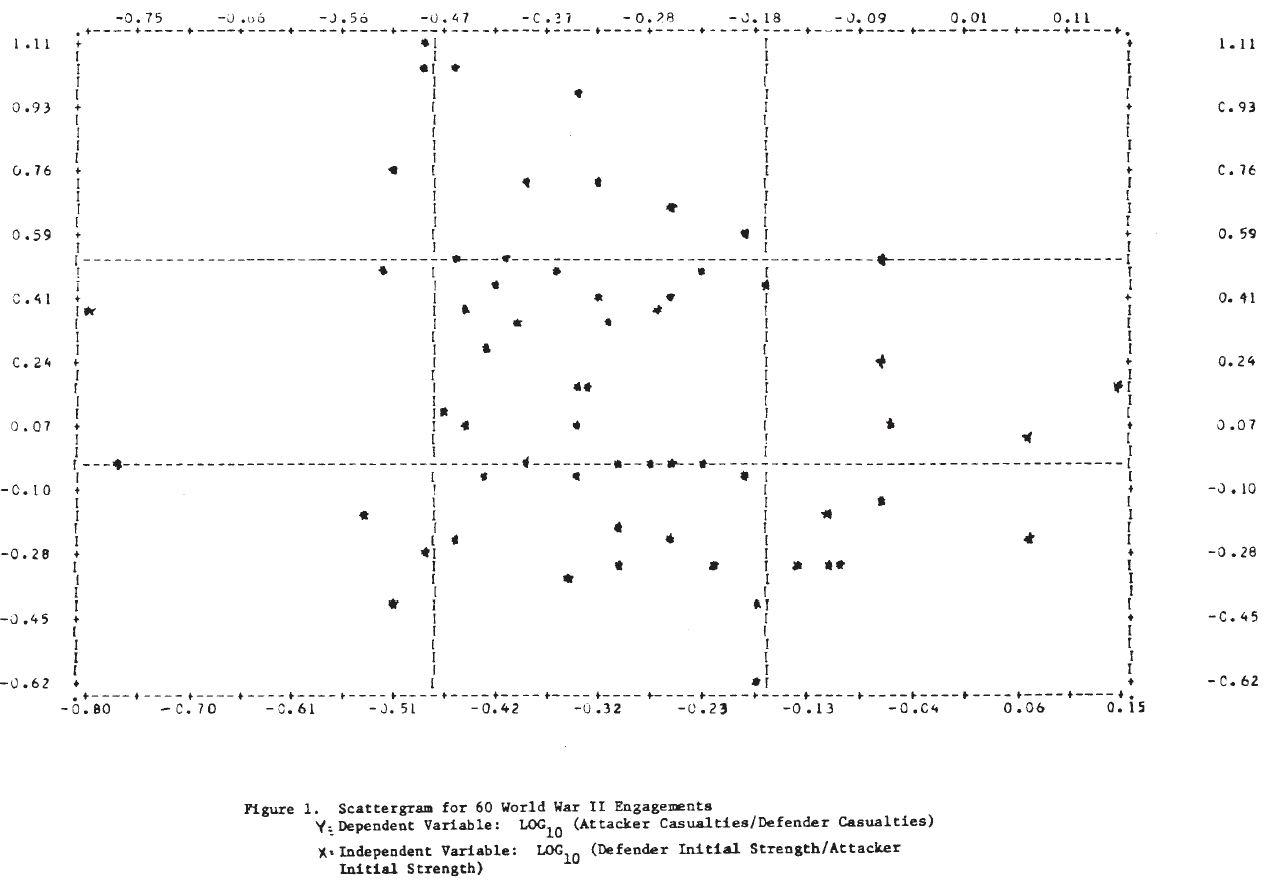
Analysis of the type carried out by Willard appears to produce very poor results for these World War II engagements. Part of the reason for this is apparent from Figure 1, which shows the scatterplot of the dependent variable, log (nc/mc), against the independent variable, log (mo/no). It is clear that no straight line will fit these data very well, and one with a positive slope would not be much worse than the “best” line found by regression. To expect the exponent to account for the wide variation in these data seems unreasonable.
Here, a simpler approach will be taken. Rather than use the data to attempt to discriminate directly between the square and the linear laws, they will be used to estimate linear coefficients under each assumption in turn, starting with the differential formulation rather than the integrated equations used by Willard.
In their simplest differential form, the Lanchester equations may be written;
Square Law; dA/dt = -kdD and dD/dt = kaA (3)
Linear law: dA/dt = -k’dAD and dD/dt = k’aAD (4)
where
A(D) is the size of the attacker (defender)
dA/dt (dD/dt) is the attacker’s (defender’s) loss rate,
ka, k’a (kd, k’d) are the attacker’s (defender’s) killing rates
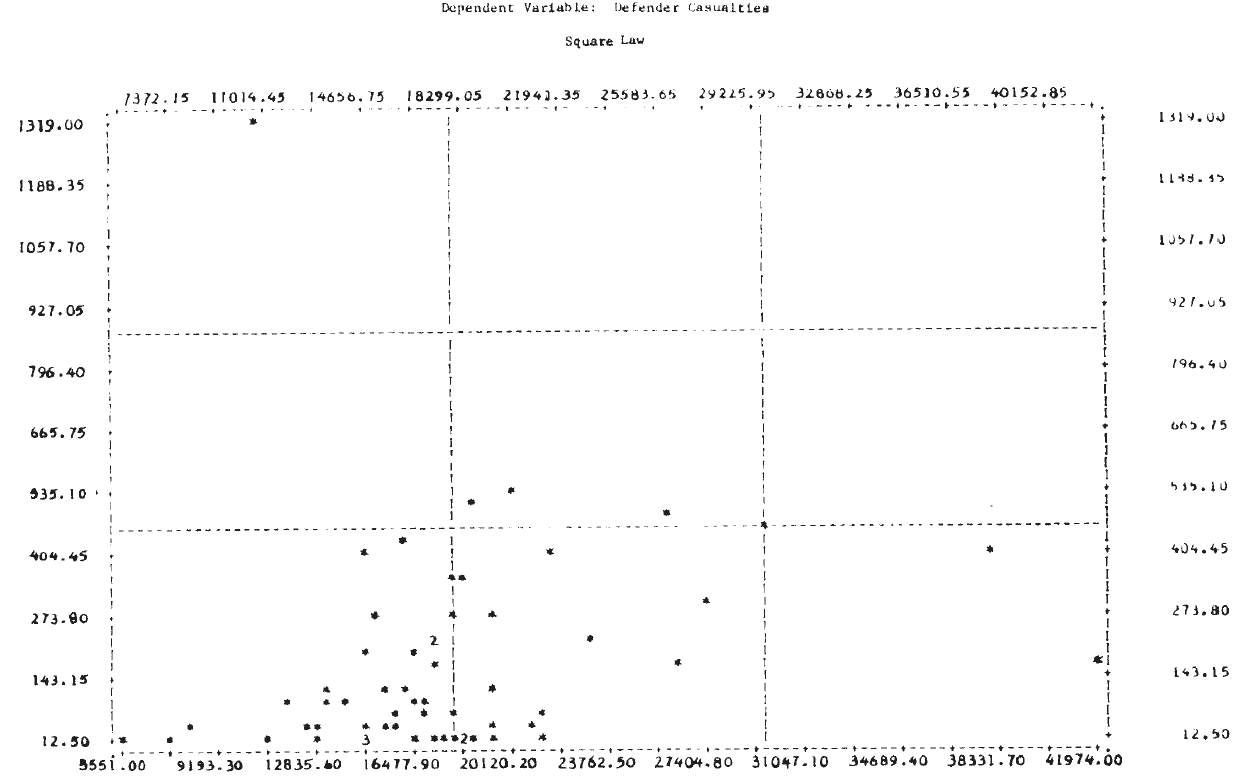
For this analysis, the day is taken as the basic time unit, and the loss rate per day is approximated by the casualties per day. Results of the linear regressions are given in Table 5. No conclusions should be drawn from the fact that the correlation coefficients are higher in the linear law case since this is expected for purely technical reasons (Note 14). A better picture of the relationships is again provided by the scatterplots in Figure 2. It is clear from these plots that, as in the case of the logarithmic forms, a single straight line will not fit the entire set of 60 engagements for either of the dependent variables.
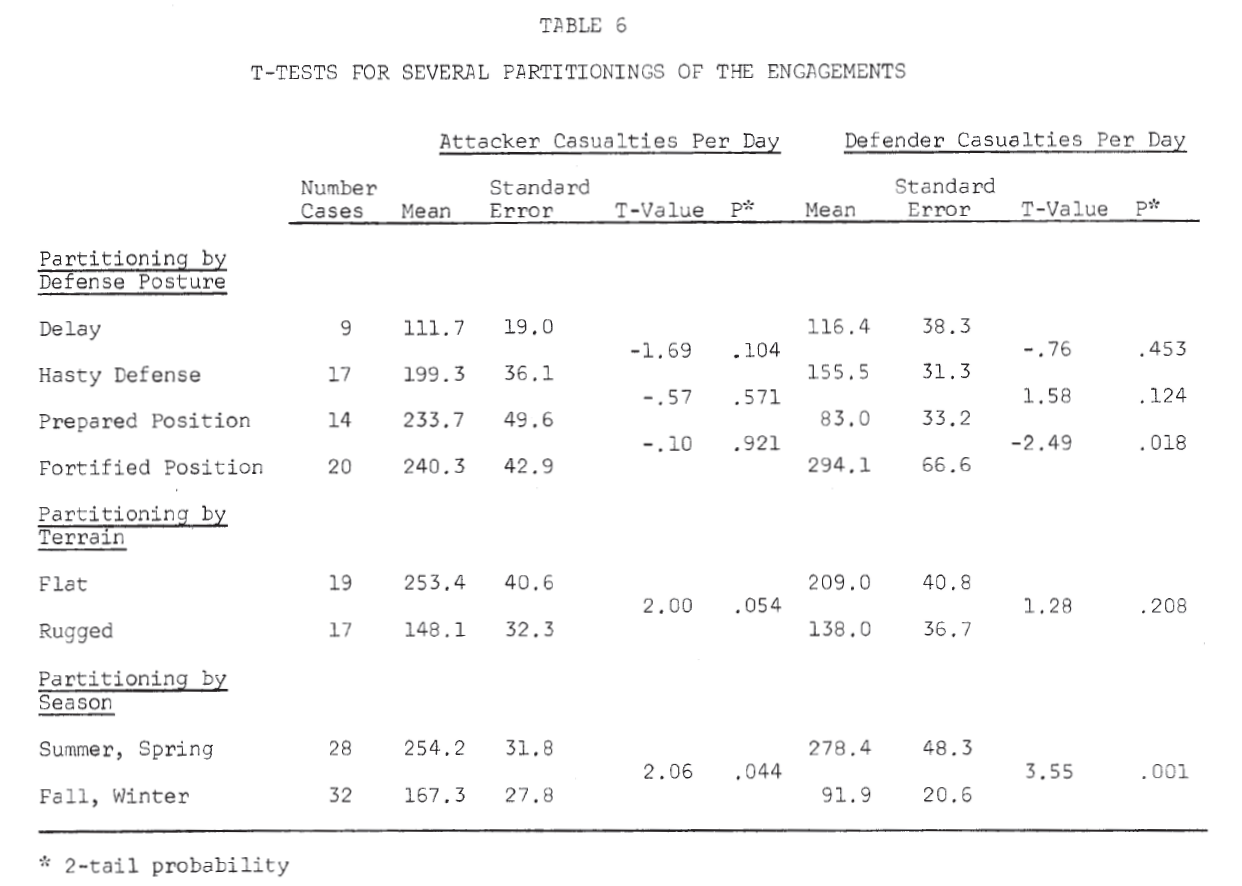
To investigate ways in which the data set might profitably be subdivided for analysis, T-tests of the means of the dependent variable were made for several partitionings of the data set. The results, shown in Table 6, suggest that dividing the engagements by defense posture might prove worthwhile.
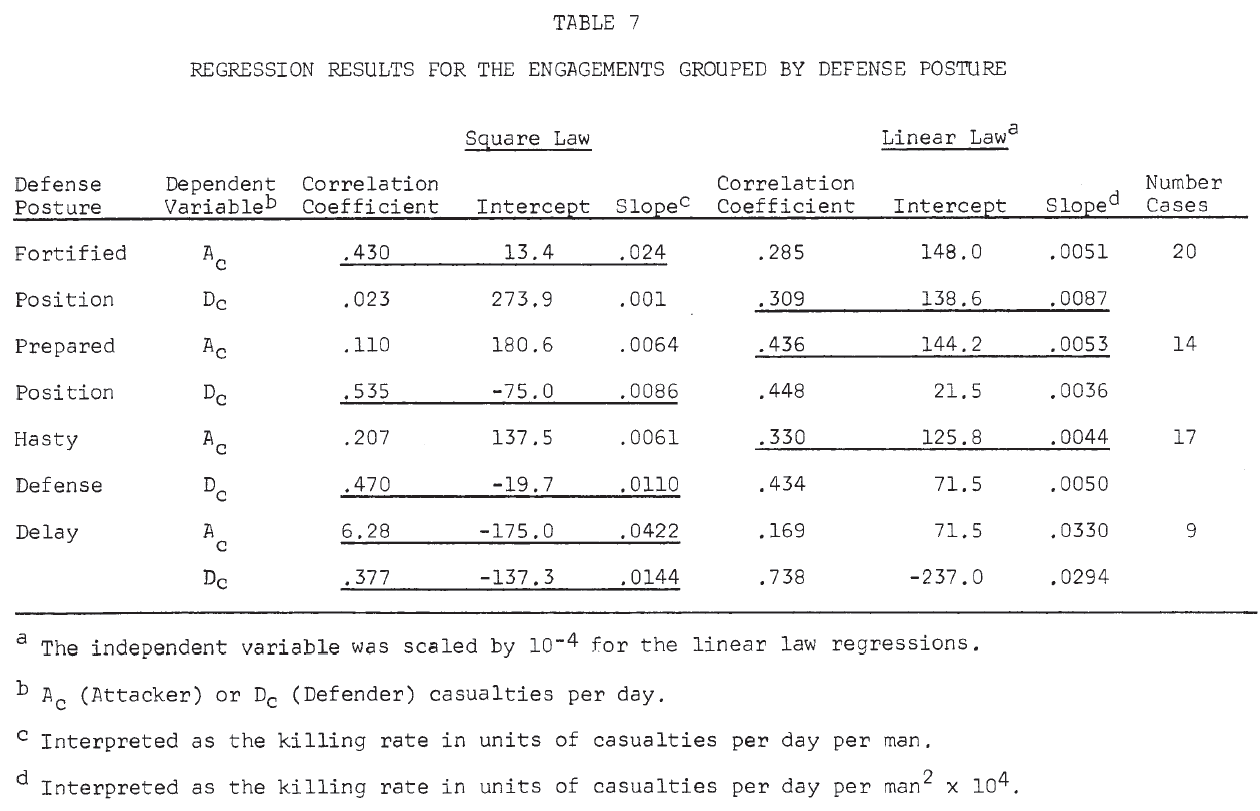
Results of the linear regressions by defense posture are shown in Table 7. For each posture, the equation that seemed to give a better fit to the data is underlined (Note 15). From this table, the following very tentative conclusions might be drawn:
In an attack on a fortified position, the attacker suffers casualties by the square law; the defender suffers casualties by the linear law. That is, the defender is aware of the attacker’s position, while the attacker knows only the general location of the defender. (This is similar to Deitchman’s guerrilla model. Note 16).
This situation is apparently reversed in the cases of attacks on prepared positions and hasty defenses.
Delaying situations seem to be treated better by the square law for both attacker and defender.
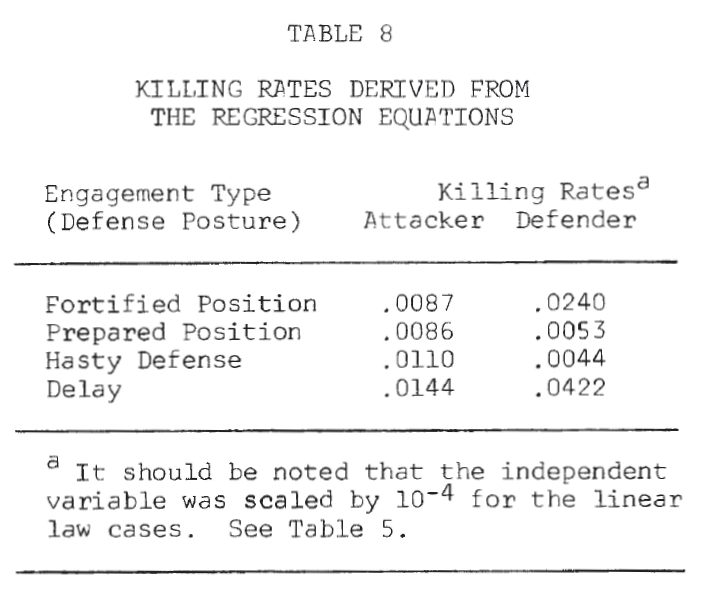
Table 8 summarizes the killing rates by defense posture. The defender has a much higher killing rate than the attacker (almost 3 to 1) in a fortified position. In a prepared position and hasty defense, the attacker appears to have the advantage. However, in a delaying action, the defender’s killing rate is again greater than the attacker’s (Note 17).
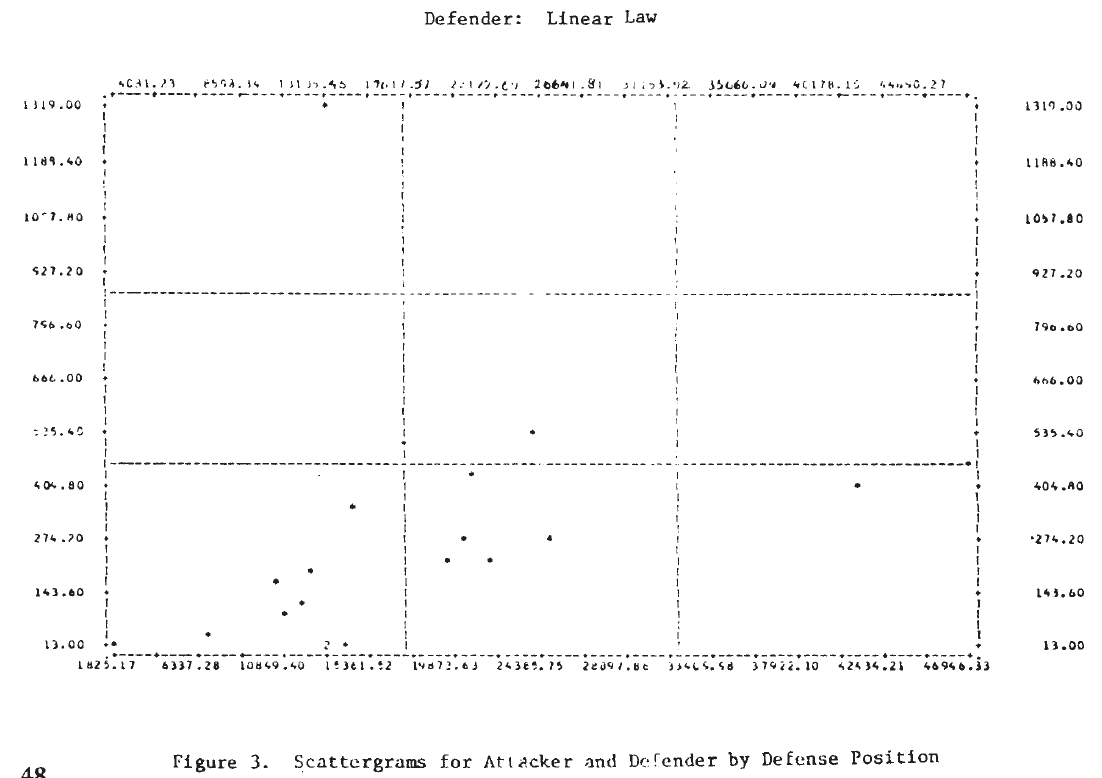
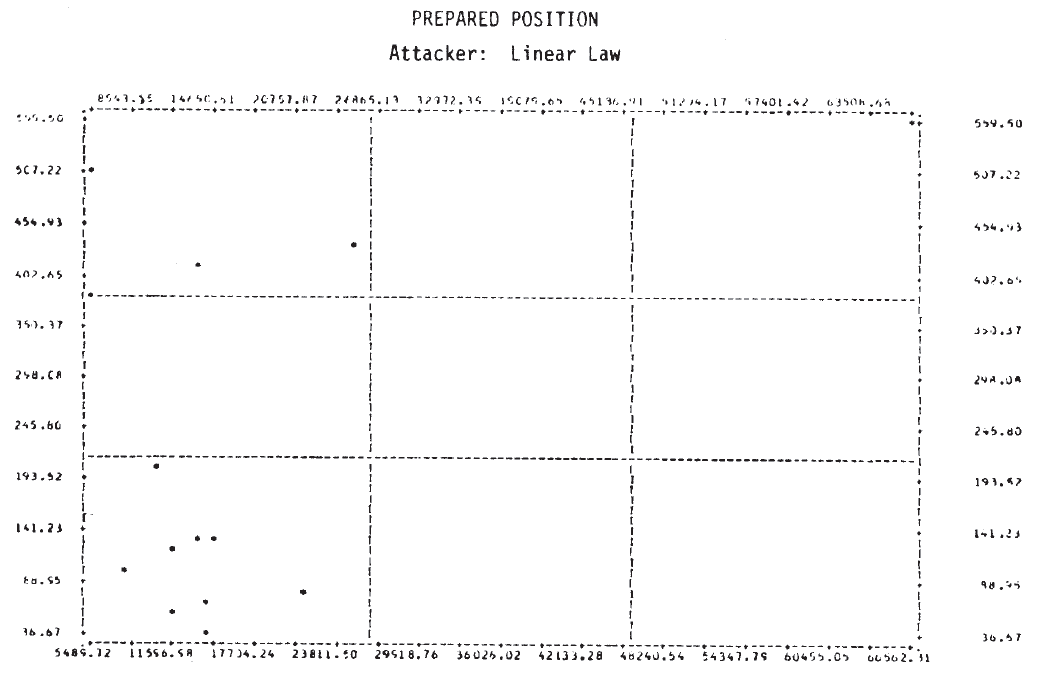
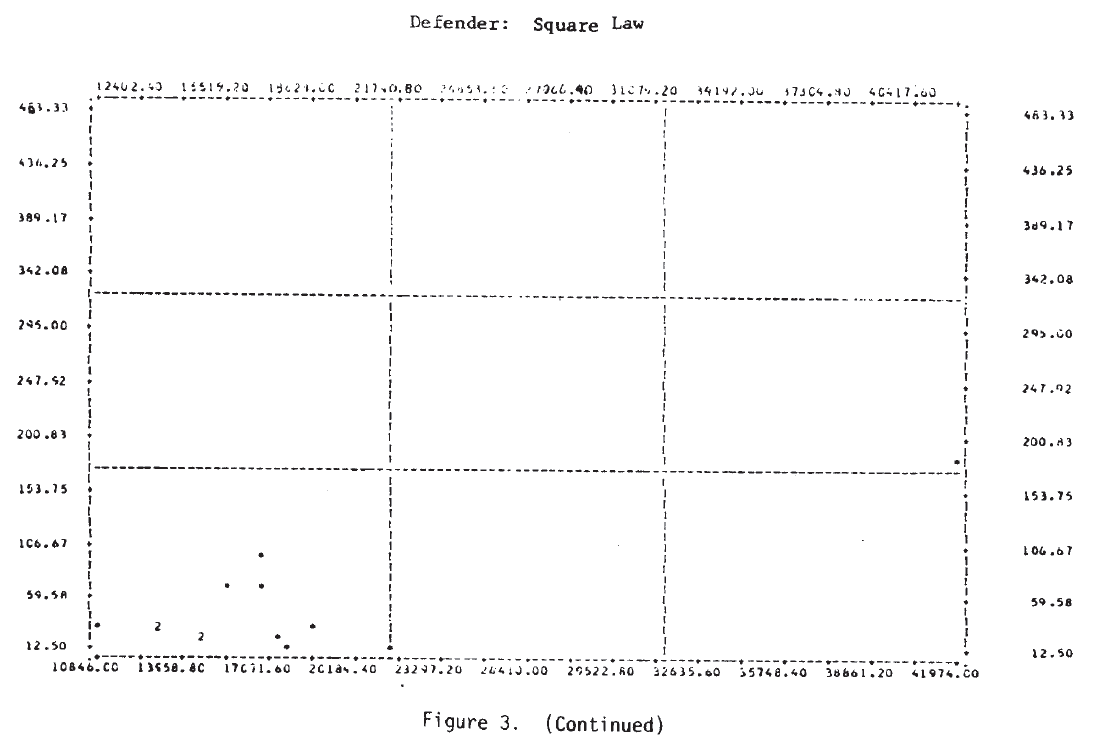
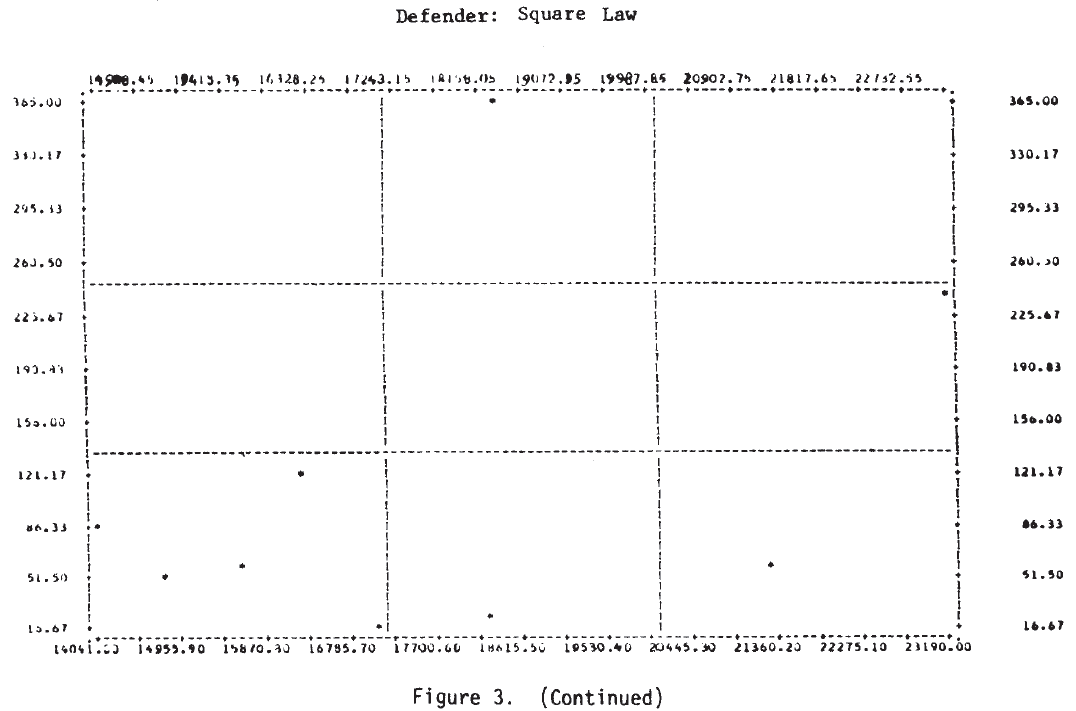
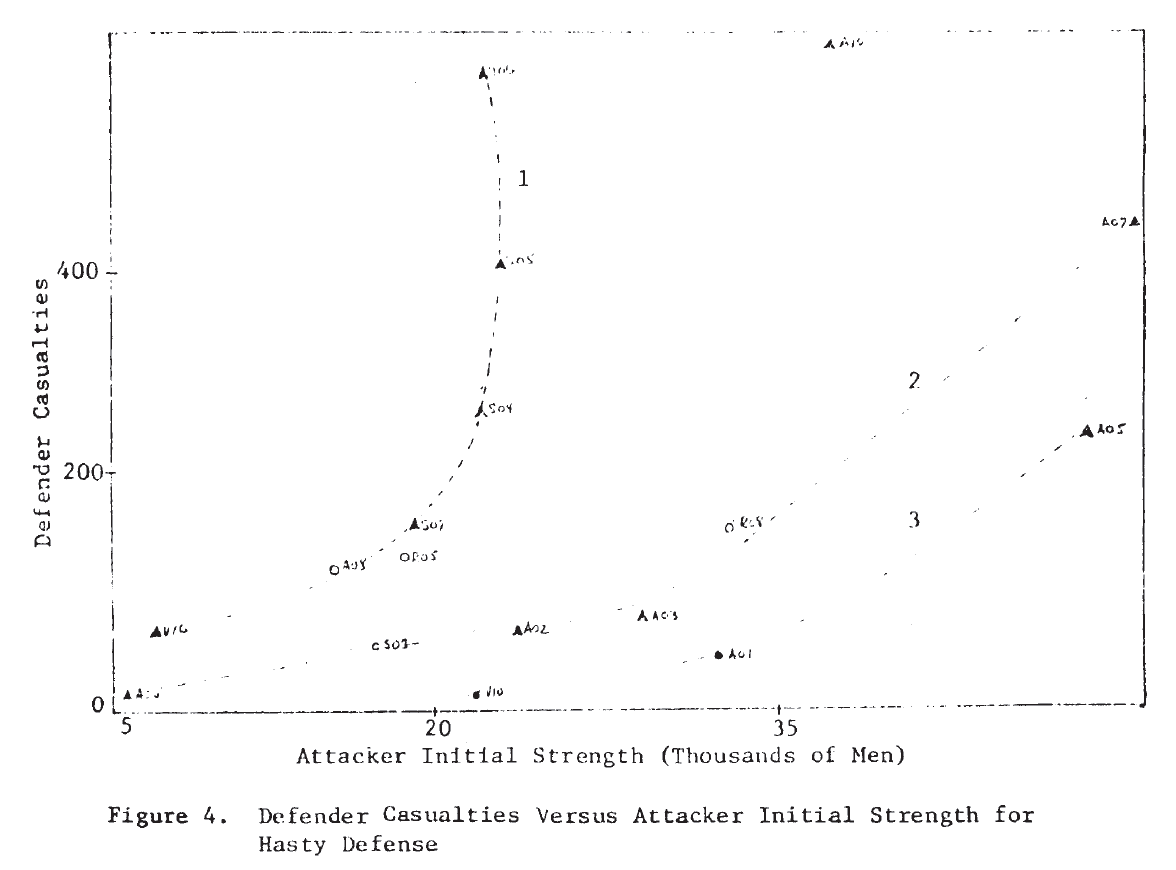
Figure 3 shows the scatterplots for these cases. Examination of these plots suggests that a tentative answer to the study question posed above might be: “Yes, casualties do appear to be related to the force sizes, but the relationship may not be a simple linear one.”
In several of these plots it appears that two or more functional forms may be involved. Consider, for example, the defender‘s casualties as a function of the attacker’s initial strength in the case of a hasty defense. This plot is repeated in Figure 4, where the points appear to fit the curves sketched there. It would appear that there are at least two, possibly three, separate relationships. Also on that plot, the individual engagements have been identified, and it is interesting to note that on the curve marked (1), five of the seven attacks were made by Germans—four of them from the Salerno campaign. It would appear from this that German attacks are associated with higher than average defender casualties for the attacking force size. Since there are so few data points, this cannot be more than a hint or interesting suggestion.
Future Research
This work suggests two conclusions that might have an impact on future lines of research on combat dynamics:
Tactics appear to be an important determinant of combat results. This conclusion, in itself, does not appear startling, at least not to the military. However, it does not always seem to have been the case that tactical questions have been considered seriously by analysts in their studies of the effects of varying force levels and force mixes.
Historical data of this type offer rich opportunities for studying the effects of tactics. For example, consideration of the narrative accounts of these battles might permit re-coding the engagements into a larger, more sensitive set of engagement categories. (It would, of course, then be highly desirable to add more engagements to the data set.)
While predictions of the future are always dangerous, I would nevertheless like to suggest what appears to be a possible trend. While military analysis of the past two decades has focused almost exclusively on the hardware of weapons systems, at least part of our future analysis will be devoted to the more behavioral aspects of combat.
Janice Bloom Fain, a Senior Associate of CACI, lnc., is a physicist whose special interests are in the applications of computer simulation techniques to industrial and military operations; she is the author of numerous reports and articles in this field. This paper was presented by Dr. Fain at the Military Operations Research Symposium at Fort Eustis, Virginia.
[5.] HERO, “A Study of the Relationship of Tactical Air Support Operations to Land Combat, Appendix B, Historical Data Base.” Historical Evaluation and Research Organization, report prepared for the Defense Operational Analysis Establishment, U.K.T.S.D., Contract D-4052 (1971).
[6.] T. N. Dupuy, The Quantified Judgment Method of Analysis of Historical Combat Data, HERO Monograph, (January 1973); HERO, “Statistical Inference in Analysis in Combat,” Annex F, Historical Data Research on Tactical Air Operations, prepared for Headquarters USAF, Assistant Chief of Staff for Studies and Analysis, Contract No. F-44620-70-C-0058 (1972).
[7.] The Operational Lethality Index (OLI) is a measure of weapon effectiveness developed by HERO.
[8.] Since Willard’s data did not indicate which side was the attacker, his force ratio is defined to be (larger force/smaller force). The HERO force ratio is (attacker/defender).
[9.] Since the criteria for success may have been rather different for the two sets of battles, this comparison may not be very meaningful.
[10.] This work includes more complex analysis in which the possibility that the two forces may be engaging in different types of combat is considered, leading to the use of two exponents rather than the single one, Stochastic combat processes are also treated.
[11.] Correlation coefficient = -.262;
Intercept = .00115; slope = -.594.
[12.] Correlation coefficient = -.184;
Intercept = .0539; slope = -,413.
[13.] Correlation coefficient = .303;
Intercept = -.638; slope = .466.
[14.] Correlation coefficients for the linear law are inflated with respect to the square law since the independent variable is a product of force sizes and, thus, has a higher variance than the single force size unit in the square law case.
[15.] This is a subjective judgment based on the following considerations Since the correlation coefficient is inflated for the linear law, when it is lower the square law case is chosen. When the linear law correlation coefficient is higher, the case with the intercept closer to 0 is chosen.
[17.] As pointed out by Mr. Alan Washburn, who prepared a critique on this paper, when comparing numerical values of the square law and linear law killing rates, the differences in units must be considered. (See footnotes to Table 7).
French retreat from Russia in 1812 by Illarion Mikhailovich Pryanishnikov (1812) [Wikipedia]
After discussing with Chris the series of recent posts on the subject of breakpoints, it seemed appropriate to provide a better definition of exactly what a breakpoint is.
Dorothy Kneeland Clark was the first to define the notion of a breakpoint in her study, Casualties as a Measure of the Loss of Combat Effectiveness of an Infantry Battalion (Operations Research Office, The Johns Hopkins University: Baltimore, 1954). She found it was not quite as clear-cut as it seemed and the working definition she arrived at was based on discussions and the specific combat outcomes she found in her data set [pp 9-12].
DETERMINATION OF BREAKPOINT
The following definitions were developed out of many discussions. A unit is considered to have lost its combat effectiveness when it is unable to carry out its mission. The onset of this inability constitutes a breakpoint. A unit’s mission is the objective assigned in the current operations order or any other instructional directive, written or verbal. The objective may be, for example, to attack in order to take certain positions, or to defend certain positions.
How does one determine when a unit is unable to carry out its mission? The obvious indication is a change in operational directive: the unit is ordered to stop short of its original goal, to hold instead of attack, to withdraw instead of hold. But one or more extraneous elements may cause the issue of such orders:
(1) Some other unit taking part in the operation may have lost its combat effectiveness, and its predicament may force changes, in the tactical plan. For example the inability of one infantry battalion to take a hill may require that the two adjoining battalions be stopped to prevent exposing their flanks by advancing beyond it.
(2) A unit may have been assigned an objective on the basis of a G-2 estimate of enemy weakness which, as the action proceeds, proves to have been over-optimistic. The operations plan may, therefore, be revised before the unit has carried out its orders to the point of losing combat effectiveness.
(3) The commanding officer, for reasons quite apart from the tactical attrition, may change his operations plan. For instance, General Ridgway in May 1951 was obliged to cancel his plans for a major offensive north of the 38th parallel in Korea in obedience to top level orders dictated by political considerations.
(4) Even if the supposed combat effectiveness of the unit is the determining factor in the issuance of a revised operations order, a serious difficulty in evaluating the situation remains. The commanding officer’s decision is necessarily made on the basis of information available to him plus his estimate of his unit’s capacities. Either or both of these bases may be faulty. The order may belatedly recognize a collapse which has in factor occurred hours earlier, or a commanding officer may withdraw a unit which could hold for a much longer time.
It was usually not hard to discover when changes in orders resulted from conditions such as the first three listed above, but it proved extremely difficult to distinguish between revised orders based on a correct appraisal of the unit’s combat effectiveness and those issued in error. It was concluded that the formal order for a change in mission cannot be taken as a definitive indication of the breakpoint of a unit. It seemed necessary to go one step farther and search the records to learn what a given battalion did regardless of provisions in formal orders…
CATEGORIES OF BREAKPOINTS SELECTED
In the engagements studied the following categories of breakpoint were finally selected:
Category of Breakpoint
No. Analyzed
I. Attack [Symbol] rapid reorganization [Symbol] attack
9
II. Attack [Symbol] defense (no longer able to attack without a few days of recuperation and reinforcement
21
III. Defense [Symbol] withdrawal by order to a secondary line
13
IV. Defense [Symbol] collapse
5
Disorganization and panic were taken as unquestionable evidence of loss of combat effectiveness. It appeared, however, that there were distinct degrees of magnitude in these experiences. In addition to the expected breakpoints at attack [Symbol] defense and defense [Symbol] collapse, a further category, I, seemed to be indicated to include situations in which an attacking battalion was ‘pinned down” or forced to withdraw in partial disorder but was able to reorganize in 4 to 24 hours and continue attacking successfully.
Category II includes (a) situations in which an attacking battalion was ordered into the defensive after severe fighting or temporary panic; (b) situations in which a battalion, after attacking successfully, failed to gain ground although still attempting to advance and was finally ordered into defense, the breakpoint being taken as occurring at the end of successful advance. In other words, the evident inability of the unit to fulfill its mission was used as the criterion for the breakpoint whether orders did or did not recognize its inability. Battalions after experiencing such a breakpoint might be able to recuperate in a few days to the point of renewing successful attack or might be able to continue for some time in defense.
The sample of breakpoints coming under category IV, defense [Symbol] collapse, proved to be very small (5) and unduly weighted in that four of the examples came from the same engagement. It was, therefore, discarded as probably not representative of the universe of category IV breakpoints,* and another category (III) was added: situations in which battalions on the defense were ordered withdrawn to a quieter sector. Because only those instances were included in which the withdrawal orders appeared to have been dictated by the condition of the unit itself, it is believed that casualty levels for this category can be regarded as but slightly lower than those associated with defense [Symbol] collapse.
In both categories II and III, “‘defense” represents an active situation in which the enemy is attacking aggressively.
* It had been expected that breakpoints in this category would be associated with very high losses. Such did not prove to be the case. In whatever way the data were approached, most of the casualty averages were only slightly higher than those associated with category II (attack [Symbol] defense), although the spread in data was wider. It is believed that factors other than casualties, such as bad weather, difficult terrain, and heavy enemy artillery fire undoubtedly played major roles in bringing about the collapse in the four units taking part in the same engagement. Furthermore, the casualty figures for the four units themselves is in question because, as the situation deteriorated, many of the men developed severe cases of trench foot and combat exhaustion, but were not evacuated, as they would have been in a less desperate situation, and did not appear in the casualty records until they had made their way to the rear after their units had collapsed.
In 1987-1988, Trevor Dupuy and colleagues at Data Memory Systems, Inc. (DMSi), Janice Fain, Rich Anderson, Gay Hammerman, and Chuck Hawkins sought to create a broader, more generally applicable definition for breakpoints for the study, Forced Changes of Combat Posture (DMSi, Fairfax, VA, 1988) [pp. I-2-3]
The combat posture of a military force is the immediate intention of its commander and troops toward the opposing enemy force, together with the preparations and deployment to carry out that intention. The chief combat postures are attack, defend, delay, and withdraw.
A change in combat posture (or posture change) is a shift from one posture to another, as, for example, from defend to attack or defend to withdraw. A posture change can be either voluntary or forced.
A forced posture change (FPC) is a change in combat posture by a military unit that is brought about, directly or indirectly, by enemy action. Forced posture changes are characteristically and almost always changes to a less aggressive posture. The most usual FPCs are from attack to defend and from defend to withdraw (or retrograde movement). A change from withdraw to combat ineffectiveness is also possible.
Breakpoint is a term sometimes used as synonymous with forced posture change, and sometimes used to mean the collapse of a unit into ineffectiveness or rout. The latter meaning is probably more common in general usage, while forced posture change is the more precise term for the subject of this study. However, for brevity and convenience, and because this study has been known informally since its inception as the “Breakpoints” study, the term breakpoint is sometimes used in this report. When it is used, it is synonymous with forced posture change.
Hopefully this will help clarify the previous discussions of breakpoints on the blog.
U.S. Army prisoners of war captured by German forces during the Battle of the Bulge in 1944. [Wikipedia]
One of the least studied aspects of combat is battle termination. Why do units in combat stop attacking or defending? Shifts in combat posture (attack, defend, delay, withdrawal) are usually voluntary, directed by a commander, but they can also be involuntary, as a result of direct or indirect enemy action. Why do involuntary changes in combat posture, known as breakpoints, occur?
As Chris pointed out in a previous post, the topic of breakpoints has only been addressed by two known studies since 1954. Most existing military combat models and wargames address breakpoints in at least a cursory way, usually through some calculation based on personnel casualties. Both of the breakpoints studies suggest that involuntary changes in posture are seldom related to casualties alone, however.
Current U.S. Army doctrine addresses changes in combat posture through discussions of culmination points in the attack, and transitions from attack to defense, defense to counterattack, and defense to retrograde. But these all pertain to voluntary changes, not breakpoints.
Army doctrinal literature has little to say about breakpoints, either in the context of friendly forces or potential enemy combatants. The little it does say relates to the effects of fire on enemy forces and is based on personnel and material attrition.
According to ADRP 1-02 Terms and Military Symbols, an enemy combat unit is considered suppressed after suffering 3% personnel casualties or material losses, neutralized by 10% losses, and destroyed upon sustaining 30% losses. The sources and methodology for deriving these figures is unknown, although these specific terms and numbers have been a part of Army doctrine for decades.
The joint U.S. Army and U.S. Marine Corps vision of future land combat foresees battlefields that are highly lethal and demanding on human endurance. How will such a future operational environment affect combat performance? Past experience undoubtedly offers useful insights but there seems to be little interest in seeking out such knowledge.
“All models are wrong, some models are useful.” – George Box
Models, no matter what their subjects, must always be an imperfect copy of the original. The term “model” inherently has this connotation. If the subject is exact and precise, then it is a duplicate, a replica, a clone, or a copy, but not a “model.” The most common dimension to be compromised is generally size, or more literally the three spatial dimensions of length, width and height. A good example of this would be a scale model airplane, generally available in several ratios from the original, such as 1/144, 1/72 or 1/48 (which are interestingly all factors of 12 … there are also 1/100 for the more decimal-minded). These mean that the model airplane at 1/72 scale would be 72 times smaller … take the length, width and height measurements of the real item, and divide by 72 to get the model’s value.
If we take the real item’s weight and divide by 72, we would not expect our model to weight 72 times less! Not unless the same or similar materials would be used, certainly. Generally, the model has a different purpose than replicating the subject’s functionality. It is helping to model the subject’s qualities, or to mimic them in some useful way. In the case of the 1/72 plastic model airplane of the F-15J fighter, this might be replicating the sight of a real F-15J, to satisfy the desire of the youth to look at the F-15J and to imagine themselves taking flight. Or it might be for pilots at a flight school to mimic air combat with models instead of ha
The model aircraft is a simple physical object; once built, it does not change over time (unless you want to count dropping it and breaking it…). A real F-15J, however, is a dynamic physical object, which changes considerably over the course of its normal operation. It is loaded with fuel, ordnance, both of which have a huge effect on its weight, and thus its performance characteristics. Also, it may be occupied by different crew members, whose experience and skills may vary considerably. These qualities of the unit need to be taken into account, if the purpose of the model is to represent the aircraft. The classic example of this is a flight envelope model of an F-15A/C:
[Quora]
This flight envelope itself is a model, it represents the flight characteristics of the F-15 using two primary quantitative axes – altitude and speed (in numbers of mach), and also throttle setting. Perhaps the most interesting thing about this is the realization than an F-15 slows down as it descends. Are these particular qualities of an F-15 required to model air combat involving such and aircraft?
How to Apply This Modeling Process to a Wargame?
The purpose of the war game is to model or represent the possible outcome of a real combat situation, played forward in the model at whatever pace and scale the designer has intended.
As mentioned previously, my colleague and I are playing Asian Fleet, a war game that covers several types of naval combat, including those involving air units, surface units and submarine units. This was published in 2007, and updated in 2010. We’ve selected a scenario that has only air units on either side. The premise of this scenario is quite simple:
The Chinese air force, in trying to prevent the United States from intervening in a Taiwan invasion, will carry out an attack on the SDF as well as the US military base on Okinawa. Forces around Shanghai consisting of state-of-the-art fighter bombers and long-range attack aircraft have been placed for the invasion of Taiwan, and an attack on Okinawa would be carried out with a portion of these forces. [Asian Fleet Scenario Book]
Of course, this game is a model of reality. The infinite geospatial and temporal possibilities of space-time which is so familiar to us has been replaced by highly aggregated discreet buckets, such as turns that may last for a day, or eight hours. Latitude, longitude and altitude are replaced with a two-dimensional hexagonal “honey comb” surface. Hence, distance is no longer computed in miles or meters, but rather in “hexes”, each of which is about 50 nautical miles. Aircraft are effectively aloft, or on the ground, although a “high mission profile” will provide endurance benefits. Submarines are considered underwater, or may use “deep mode” attempting to hide from sonar searches.
Maneuver units are represented by “counters” or virtual chits to be moved about the map as play progresses. Their level of aggregation varies from large and powerful ships and subs represented individually, to smaller surface units and weaker subs grouped and represented by a single counter (a “flotilla”), to squadrons or regiments of aircraft represented by a single counter. Depending upon the nation and the military branch, this may be a few as 3-5 aircraft in a maritime patrol aircraft (MPA) detachment (“recon” in this game), to roughly 10-12 aircraft in a bomber unit, to 24 or even 72 aircraft in a fighter unit (“interceptor” in this game).
Enough Theory, What Happened?!
The Chinese Air Force mobilized their H6H bomber, escorted by large numbers of Flankers (J11 and Su-30MK2 fighters from the Shanghai area, and headed East towards Okinawa. The US Air Force F-15Cs supported by airborne warning and control system (AWACS) detected this inbound force and delayed engagement until their Japanese F-15J unit on combat air patrol (CAP) could support them, and then engaged the Chinese force about 50 miles from the AWACS orbits. In this game, air combat is broken down into two phases, long-range air to air (LRAA) combat (aka beyond visual range, BVR), and “regular” air combat, or within visual range (WVR) combat.
In BVR combat, only units marked as equipped with BVR capability may attack:
2 x F-15C units have a factor of 32; scoring a hit in 5 out of 10 cases, or roughly 50%.
Su-30MK2 unit has a factor of 16; scoring a hit in 4 out of 10 cases, ~40%.
To these numbers a modifier of +2 exists when the attacker is supported by AWACS, so the odds to score a hit increase to roughly 70% for the F-15Cs … but in our example they miss, and the Chinese shot misses as well. Thus, the combat proceeds to WVR.
In WVR combat, each opposing side sums their aerial combat factors:
2 x F-15C (32) + F-15J (13) = 45
Su-30MK2 (15) + J11 (13) + H6H (1) = 29
These two numbers are then expressed as a ratio, attacker-to-defender (45:29), and rounded down in favor of the defender (1:1), and then a ten-sided-die (d10) is rolled to consult the Air-to-Air Combat Results Table, on the “CAP/AWACS Interception” line. The die was rolled, and a result of “0/0r” was achieved, which basically says that neither side takes losses, but the defender is turned back from the mission (“r” being code for “return to base”). Given the +2 modifier for the AWACS, the worst outcome for the Allies would be a mutual return to base result (“0r/0r”). The best outcome would be inflicting two “steps” of damage, and sending the rest home (“0/2r”). A step of loss is about one half of an air unit, represented by flipping over the counter or chit, and operating with the combat factors at about half strength.
To sum this up, as the Allied commander, my conclusion was that the Americans were hung-over or asleep for this engagement.
I am encouraged by some similarities between this game and the fantastic detail that TDI has just posted about the DACM model, here and here. Thus, I plan to not only dissect this Asian Fleet game (VGAF), but also go a gap analysis between VGAF and DACM.

 [This article was originally posted on 11 October 2016]
[This article was originally posted on 11 October 2016]