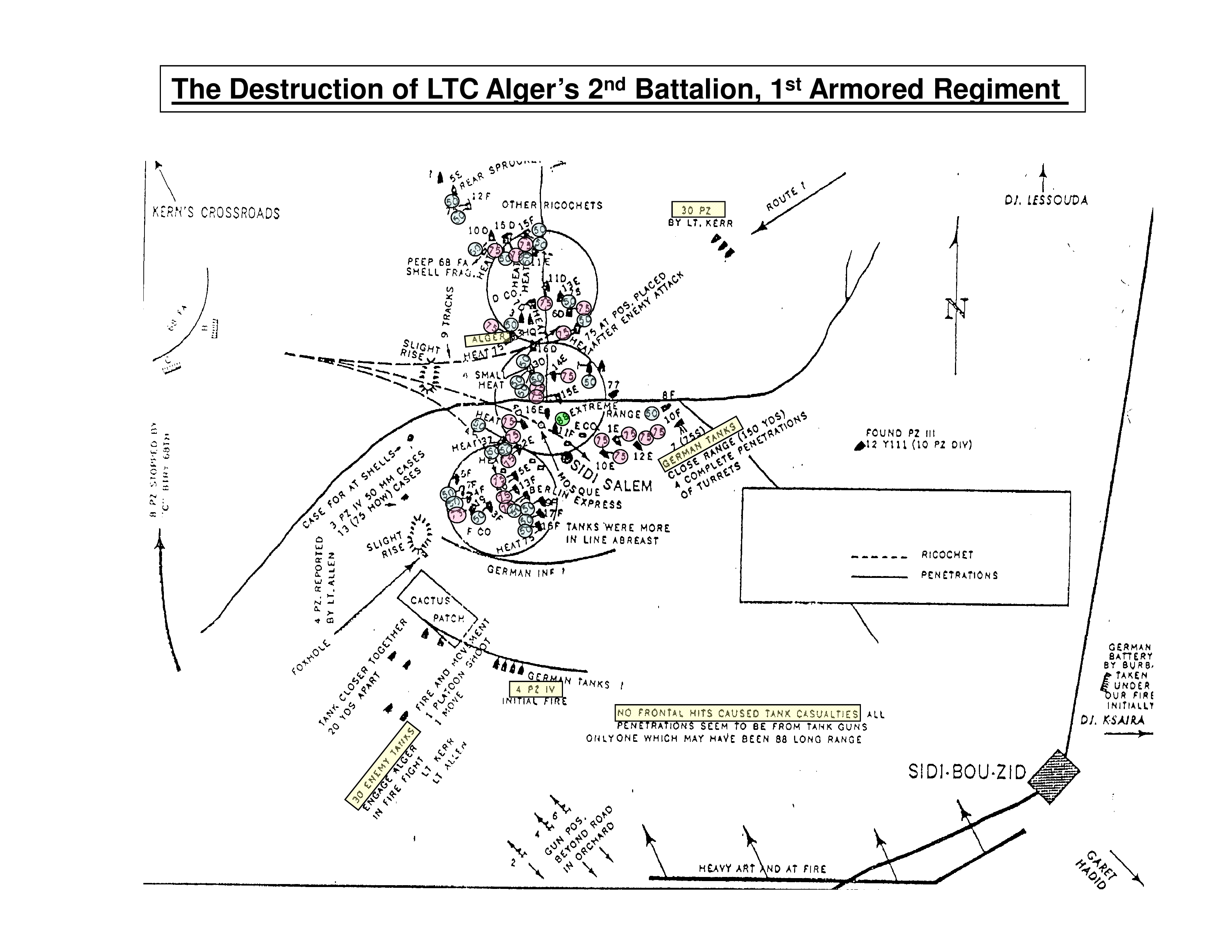
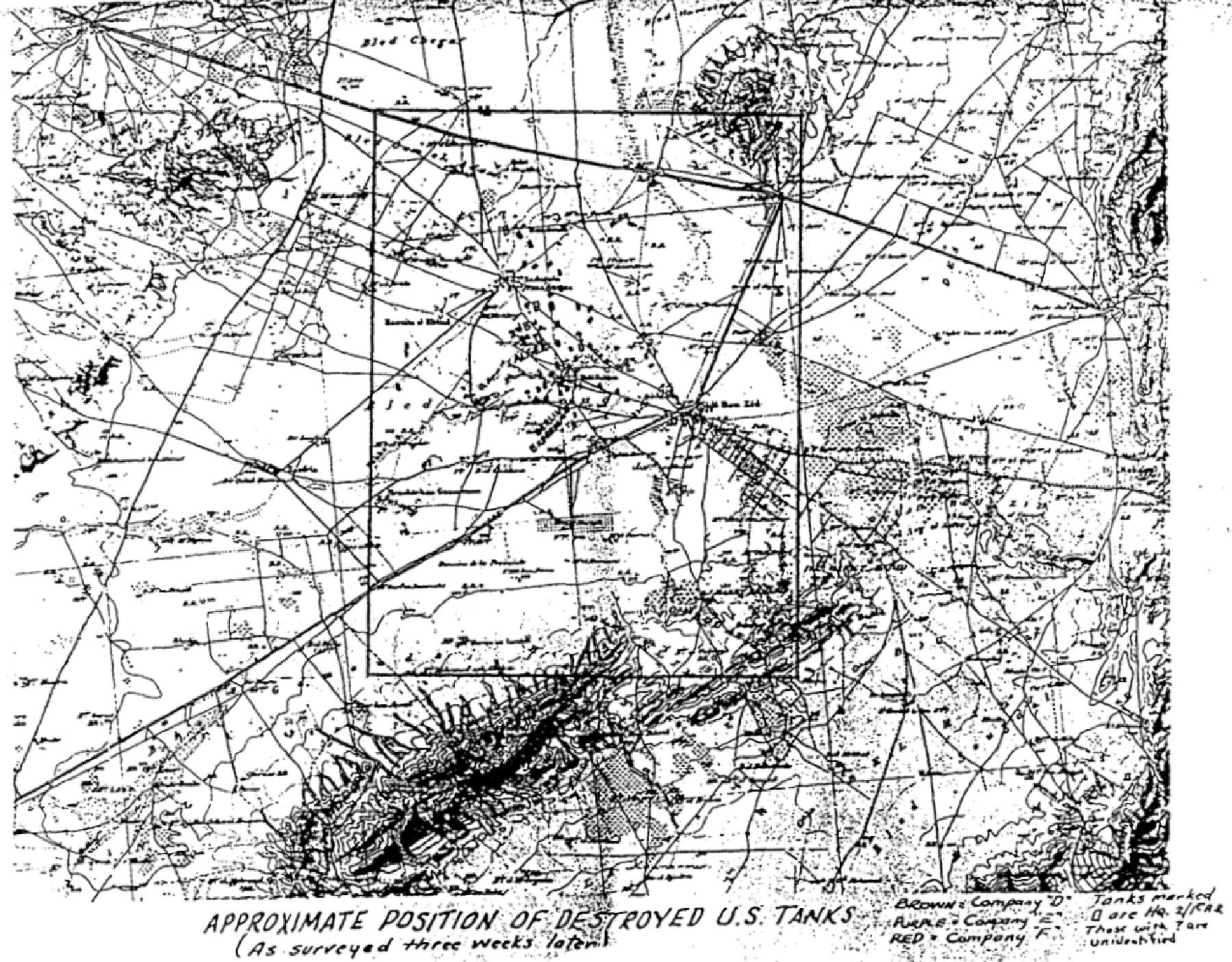
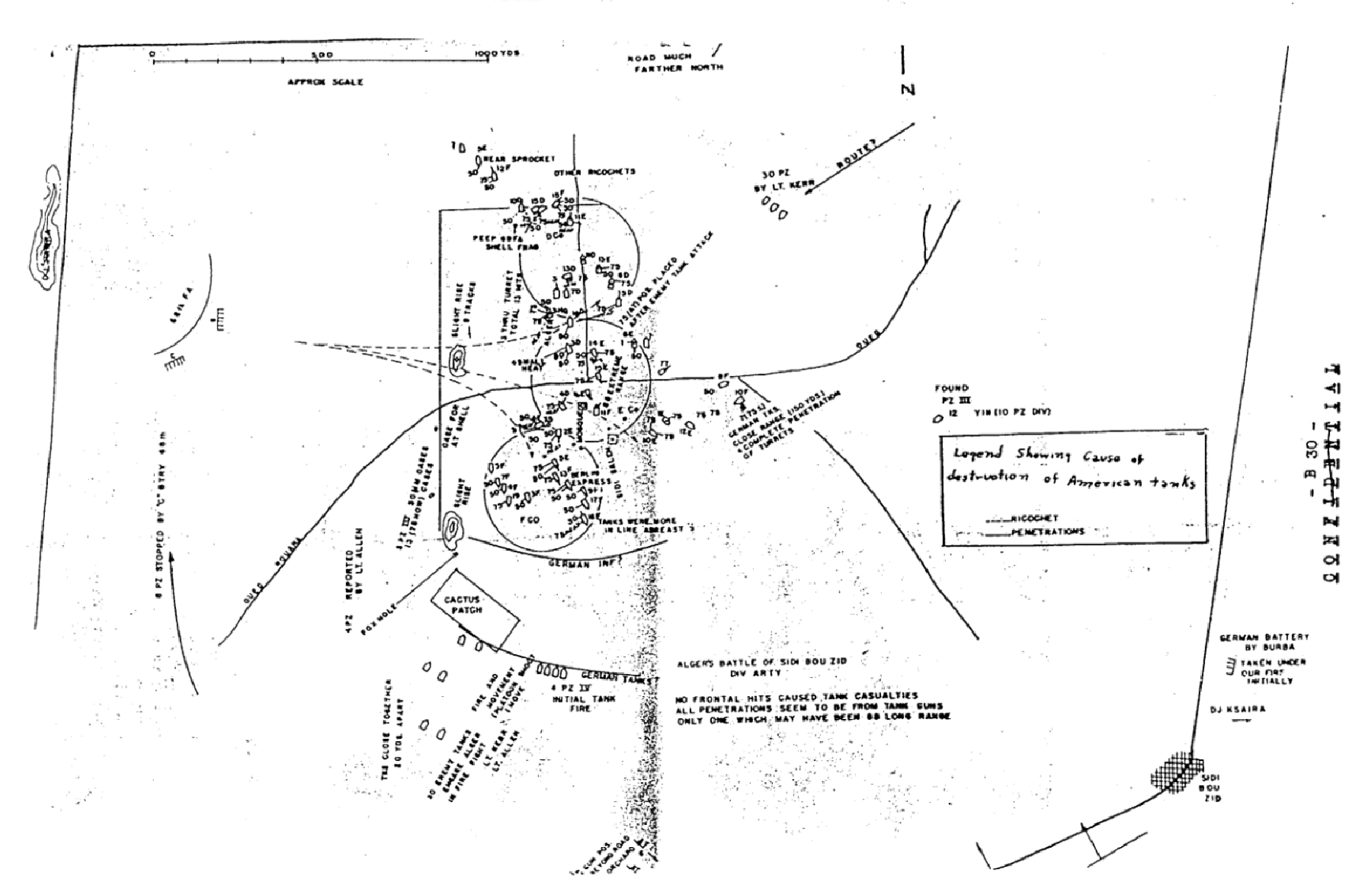
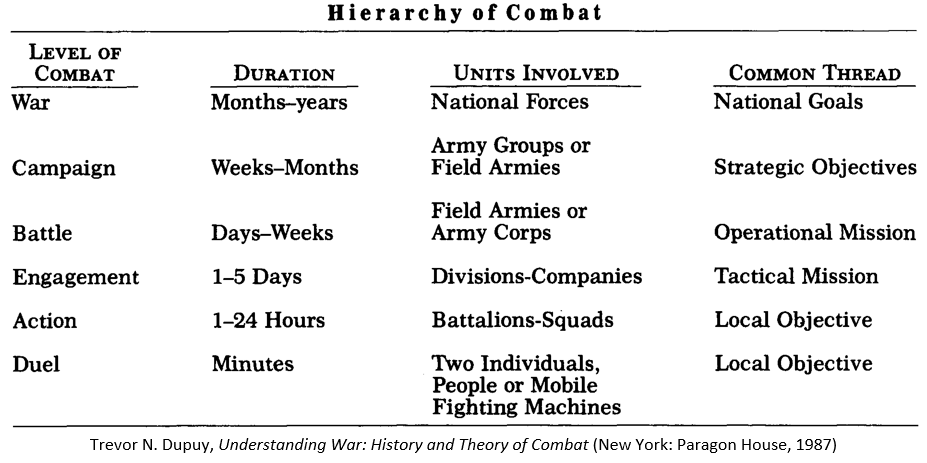
[The article below is reprinted from April 1997 edition of The International TNDM Newsletter.]
The First Test of the TNDM Battalion-Level Validations: Predicting the Winners
by Christopher A. Lawrence
CASE STUDIES: WHERE AND WHY THE MODEL FAILED CORRECT PREDICTIONS
World War I (12 cases):
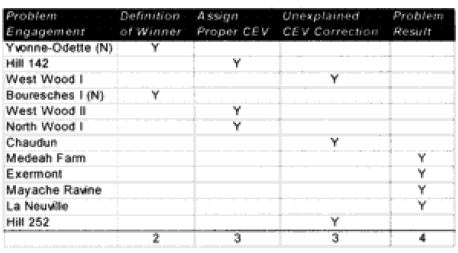
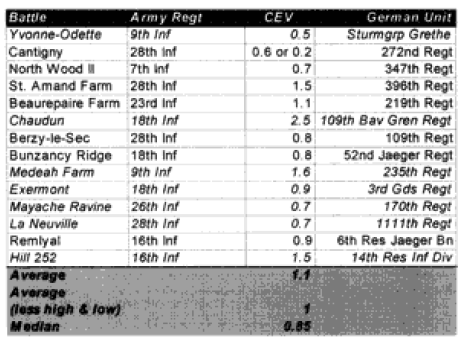
Yvonne-Odette (Night)—On the first prediction, selected the defender as a winner, with the attacker making no advance. The force ratio was 0.5 to 1. The historical results also show e attacker making no advance, but rate the attacker’s mission accomplishment score as 6 while the defender is rated 4. Therefore, this battle was scored as a draw.
On the second run, the Germans (Sturmgruppe Grethe) were assigned a CEV of 1.9 relative to the US 9th Infantry Regiment. This produced a draw with no advance.
This appears to be a result that was corrected by assigning the CEV to the side that would be expected to have that advantage. There is also a problem in defining who is winner.
Hill 142—On the first prediction the defending Germans won, whereas in the real world the attacking Marines won. The Marines are recorded as having a higher CEV in a number of battles, so when this correction is put in the Marines win with a CEV of 1.5. This appears to be a case where the side that would be expected to have the higher CEV needed that CEV input into the combat rim to replicate historical results.
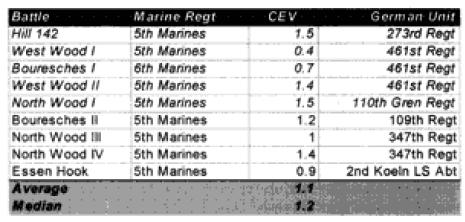
Note that while many people would expect the Germans to have the higher CEV, at this juncture in WWI the German regular army was becoming demoralized, while the US Army was highly motivated, trained and fresh. While l did not initially expect to see a superior CEV for the US Marines, when l did see it l was not surprised. I also was not surprised to note that the US Army had a lower CEV than the Marine Corps or that the German Sturmgruppe Grethe had a higher CEV than the US side. As shown in the charts below, the US Marines’ CEV is usually higher than the German CEV for the engagements of Belleau Wood, although this result is not very consistent in value. But this higher value does track with Marine Corps legend. l personally do not have sufficient expertise on WWI to confirm or deny the validity of the legend.
West Wood I—0n the first prediction the model rated the battle a draw with minimal advance (0.265 km) for the attacker, whereas historically the attackers were stopped cold with a bloody repulse. The second run predicted a very high CEV of 2.3 for the Germans, who stopped the attackers with a bloody repulse. The results are not easily explainable.
Bouresches I (Night)—On the first prediction the model recorded an attacker victory with an advance of 0.5 kilometer. Historically, the battle was a draw with an attacker advance of one kilometer. The attacker’s mission accomplishment score was 5, while the defender’s was 6. Historically, this battle could also have been considered an attacker victory. A second run with an increased German CEV to 1.5 records it as a draw with no advance. This appears to be a problem in defining who is the winner.
West Wood II—On the first run, the model predicted a draw with an advance of 0.3 kilometers. Historically, the attackers won and advanced 1.6 kilometers. A second run with a US CEV of 1.4 produced a clear attacker victory. This appears to be a case where the side that would be expected to have the higher CEV needed that CEV input into the combat run.
North Woods I—On the first prediction, the model records the defender winning, while historically the attacker won. A second run with a US CEV of 1.5 produced a clear attacker victory. This appears to be a case where the side that would be expected to have the higher CEV needed that CEV input into the combat run.
Chaudun—On the first prediction, the model predicted the defender winning when historically, the attacker clearly won. A second run with an outrageously high US CEV of 2.5 produced a clear attacker victory. The results are not easily explainable.
Medeah Farm—On the first prediction, the model recorded the defender as winning when historically the attacker won with high casualties. The battle consists of a small number of German defenders with lots of artillery defending against a large number of US attackers with little artillery. On the second run, even with a US CEV of 1.6, the German defender won. The model was unable to select a CEV that would get a correct final result yet reflect the correct casualties. The model is clearly having a problem with this engagement.
Exermont—On the first prediction, the model recorded the defender as winning when historically, the attacker did, with both the attackers and the defender’s mission accomplishment scores being rated at 5. The model did rate the defender‘s casualties too high, so when it calculated what the CEV should be, it gave the defender a higher CEV so that it could bring down the defenders losses relative to the attackers. Otherwise, this is a normal battle. The second prediction was no better. The model is clearly having a problem with this engagement due to the low defender casualties.
Mayache Ravine—The model predicted the winner (the attacker) correctly on the first run, with the attacker having an opposed advance of 0.8 kilometer. Historically, the attacker had an opposed rate of advance of 1.3 kilometers. Both sides had a mission accomplishment score of 5. The problem is that the model predicted higher defender casualties than the attacker, while in the actual battle the defender had lower casualties that the attacker. On the second run, therefore, the model put in a German CEV of 1.5, which resulted in a draw with the attacker advancing 0.3 kilometers. This brought the casualty estimates more in line, but turned a successful win/loss prediction into one that was “off by one.” The model is clearly having a problem with this engagement due to the low defender casualties.
La Neuville—The model also predicted the winner (the attacker) correctly here, with the attacker advancing 0.5 kilometer. In the historical battle they advanced 1.6 kilometers. But again, the model predicted lower attacker losses than the defender losses, while in the actual battle the defender losses were much lower than the attacker losses. So, again on the second run, the model gave the defender (the Germans) a CEV of 1.4, which turned an accurate win/loss prediction into an inaccurate one. It still didn’t do a very good job on the casualties. The model is clearly having a problem with this engagement due to the low defender casualties.
Hill 252—On the first run, the model predicts a draw with a distanced advanced of 0.2 km, while the real battle was an attacker victory with an advance of 2.9 kilometers. The model’s casualty predictions are quite good. On the second run, the model correctly predicted an attacker win with a US CEV of 1.5. The distance advanced increases to 0.6 kilometer, while the casualty prediction degrades noticeably. The model is having some problems with this engagement that are not really explainable, but the results are not far off the mark.
Next: WWII Cases














 The question of validating combat models—“To confirm or prove that the output or outputs of a model are consistent with the real-world functioning or operation of the process, procedure, or activity which the model is intended to represent or replicate”—
The question of validating combat models—“To confirm or prove that the output or outputs of a model are consistent with the real-world functioning or operation of the process, procedure, or activity which the model is intended to represent or replicate”—