A painting by a Marine officer present during the Guadalcanal campaign depicts Marines defending Hill 123 during the Battle of Edson’s Ridge, 12-14 September 1942. [Wikipedia]
The First Test of the TNDM Battalion-Level Validations: Predicting the Winners by Christopher A. Lawrence
CASE STUDIES: WHERE AND WHY THE MODEL FAILED CORRECT PREDICTIONS
World War ll (8 cases):
Overall, we got a much better prediction rate with WWII combat. We had eight cases where there was a problem. They are:
Makin Raid—On the first run, the model predicted a defender win. Historically, the attackers (US Marines) won with a 2.5 km advance. When the Marine CEV was put in (a hefty 2.4), this produced a reasonable prediction, although the advance rate was too slow. This appears to be a case where the side that would be expected to have the higher CEV needed that CEV input into the combat run in order to replicate historical results.
Edson’s Ridge (Night)—On the first run, the model predicted a defender win. Historically, the battle must be considered at best a draw, or more probably a defender win, as the mission accomplishment score of the attacker is 3 while the defender is 5.5. The attacker did advance 2 kilometers, but suffered heavy casualties. The second run was done with a US CEV of 1.5. This maintained a defender win and even balanced more in favor of the Marines. This is clearly a problem in defining who is the winner.
Lausdell X-Road: (Night)—On the first run, the model predicted an attacker victory with an advance rate of 0.4 kilometer. Historically, the German attackers advanced 0.75 kilometer, but had a mission accomplishment score of 4 versus the defender’s mission accomplishment score of 6. A second run was done with a US CEV of 1.1, but this did not significantly change the result. This is clearly a problem in defining who is the winner.
VER-9CX—On the first run, the attacker is reported as the winner. Historically this is the case, with the attacker advancing 1.2 kilometers although suffering higher losses than the defender. On the second run, however, the model predicted that the engagement was a draw. The model assigned the defenders (German) a CEV of 1.3 relative to the attackers in attempt to better reflect the casualty exchange. The model is clearly having a problem with this engagement due to the low defender casualties.
VER-2ASX—On the first run, the defender was reported as the winner. Historically, the attacker won. On the second run, the battle was recorded as a draw with the attacker (British) CEV being 1.3. This high CEV for the British is not entirely explainable, although they did fire a massive suppressive bombardment. In this case the model appears to be assigning a CEV bonus to the wrong side in an attempt to adjust a problem run. The model is still clearly having a problem with this engagement due to the low defender casualties.
VER-XHLX—On the first run, the model predicted that the defender won. Historically, the attacker won. On the second run, the battle was recorded as an attacker win with the attacker (British) CEV being 1.3. This high CEV is not entirely explainable. There is no clear explanation for these results.
VER-RDMX—On the first run, the model predicted that the attacker won. Historically, this is correct. On the second run, the battle recorded that the defender won. This indicates an attempt by the model to get the casualties correct. The model is clearly having a problem with this engagement due to the low defender casualties.
VER-CHX—On the first run, the model predicted that the defender won. Historically, the attacker won. On the second run, the battle was recorded as an attacker win with the attacker (Canadian) CEV being 1.3. Again, this high CEV is not entirely explainable. The model appears to be assigning a CEV bonus to the wrong side in an attempt to adjust a problem run. The model is still clearly having a problem with this engagement due to the low defender casualties.
Advancing Germans halted by 2nd Battalion, Fifth Marine, June 3 1918. Les Mares form 2 1/2 miles west of Belleau Wood attacked the American lines through the wheat fields. From a painting by Harvey Dunn. [U.S. Navy]
The First Test of the TNDM Battalion-Level Validations: Predicting the Winners by Christopher A. Lawrence
CASE STUDIES: WHERE AND WHY THE MODEL FAILED CORRECT PREDICTIONS
World War I (12 cases):
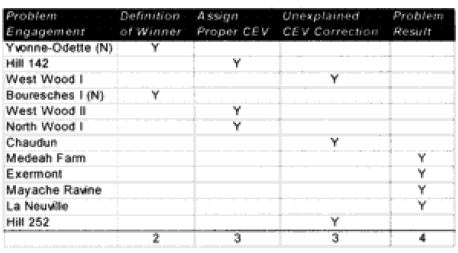
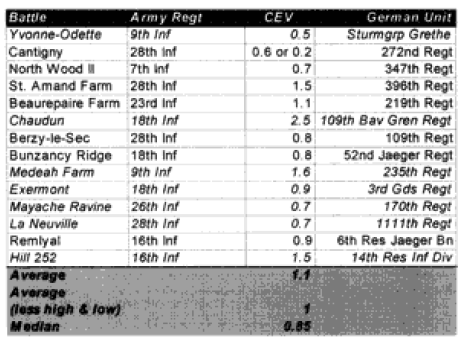
Yvonne-Odette (Night)—On the first prediction, selected the defender as a winner, with the attacker making no advance. The force ratio was 0.5 to 1. The historical results also show e attacker making no advance, but rate the attacker’s mission accomplishment score as 6 while the defender is rated 4. Therefore, this battle was scored as a draw.
On the second run, the Germans (Sturmgruppe Grethe) were assigned a CEV of 1.9 relative to the US 9th Infantry Regiment. This produced a draw with no advance.
This appears to be a result that was corrected by assigning the CEV to the side that would be expected to have that advantage. There is also a problem in defining who is winner.
Hill 142—On the first prediction the defending Germans won, whereas in the real world the attacking Marines won. The Marines are recorded as having a higher CEV in a number of battles, so when this correction is put in the Marines win with a CEV of 1.5. This appears to be a case where the side that would be expected to have the higher CEV needed that CEV input into the combat rim to replicate historical results.
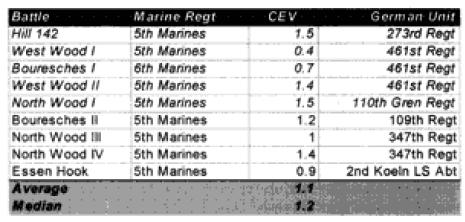
Note that while many people would expect the Germans to have the higher CEV, at this juncture in WWI the German regular army was becoming demoralized, while the US Army was highly motivated, trained and fresh. While l did not initially expect to see a superior CEV for the US Marines, when l did see it l was not surprised. I also was not surprised to note that the US Army had a lower CEV than the Marine Corps or that the German Sturmgruppe Grethe had a higher CEV than the US side. As shown in the charts below, the US Marines’ CEV is usually higher than the German CEV for the engagements of Belleau Wood, although this result is not very consistent in value. But this higher value does track with Marine Corps legend. l personally do not have sufficient expertise on WWI to confirm or deny the validity of the legend.
West Wood I—0n the first prediction the model rated the battle a draw with minimal advance (0.265 km) for the attacker, whereas historically the attackers were stopped cold with a bloody repulse. The second run predicted a very high CEV of 2.3 for the Germans, who stopped the attackers with a bloody repulse. The results are not easily explainable.
Bouresches I (Night)—On the first prediction the model recorded an attacker victory with an advance of 0.5 kilometer. Historically, the battle was a draw with an attacker advance of one kilometer. The attacker’s mission accomplishment score was 5, while the defender’s was 6. Historically, this battle could also have been considered an attacker victory. A second run with an increased German CEV to 1.5 records it as a draw with no advance. This appears to be a problem in defining who is the winner.
West Wood II—On the first run, the model predicted a draw with an advance of 0.3 kilometers. Historically, the attackers won and advanced 1.6 kilometers. A second run with a US CEV of 1.4 produced a clear attacker victory. This appears to be a case where the side that would be expected to have the higher CEV needed that CEV input into the combat run.
North Woods I—On the first prediction, the model records the defender winning, while historically the attacker won. A second run with a US CEV of 1.5 produced a clear attacker victory. This appears to be a case where the side that would be expected to have the higher CEV needed that CEV input into the combat run.
Chaudun—On the first prediction, the model predicted the defender winning when historically, the attacker clearly won. A second run with an outrageously high US CEV of 2.5 produced a clear attacker victory. The results are not easily explainable.
Medeah Farm—On the first prediction, the model recorded the defender as winning when historically the attacker won with high casualties. The battle consists of a small number of German defenders with lots of artillery defending against a large number of US attackers with little artillery. On the second run, even with a US CEV of 1.6, the German defender won. The model was unable to select a CEV that would get a correct final result yet reflect the correct casualties. The model is clearly having a problem with this engagement.
Exermont—On the first prediction, the model recorded the defender as winning when historically, the attacker did, with both the attackers and the defender’s mission accomplishment scores being rated at 5. The model did rate the defender‘s casualties too high, so when it calculated what the CEV should be, it gave the defender a higher CEV so that it could bring down the defenders losses relative to the attackers. Otherwise, this is a normal battle. The second prediction was no better. The model is clearly having a problem with this engagement due to the low defender casualties.
Mayache Ravine—The model predicted the winner (the attacker) correctly on the first run, with the attacker having an opposed advance of 0.8 kilometer. Historically, the attacker had an opposed rate of advance of 1.3 kilometers. Both sides had a mission accomplishment score of 5. The problem is that the model predicted higher defender casualties than the attacker, while in the actual battle the defender had lower casualties that the attacker. On the second run, therefore, the model put in a German CEV of 1.5, which resulted in a draw with the attacker advancing 0.3 kilometers. This brought the casualty estimates more in line, but turned a successful win/loss prediction into one that was “off by one.” The model is clearly having a problem with this engagement due to the low defender casualties.
La Neuville—The model also predicted the winner (the attacker) correctly here, with the attacker advancing 0.5 kilometer. In the historical battle they advanced 1.6 kilometers. But again, the model predicted lower attacker losses than the defender losses, while in the actual battle the defender losses were much lower than the attacker losses. So, again on the second run, the model gave the defender (the Germans) a CEV of 1.4, which turned an accurate win/loss prediction into an inaccurate one. It still didn’t do a very good job on the casualties. The model is clearly having a problem with this engagement due to the low defender casualties.
Hill 252—On the first run, the model predicts a draw with a distanced advanced of 0.2 km, while the real battle was an attacker victory with an advance of 2.9 kilometers. The model’s casualty predictions are quite good. On the second run, the model correctly predicted an attacker win with a US CEV of 1.5. The distance advanced increases to 0.6 kilometer, while the casualty prediction degrades noticeably. The model is having some problems with this engagement that are not really explainable, but the results are not far off the mark.
The First Test of the TNDM Battalion-Level Validations: Predicting the Winners by Christopher A. Lawrence
Part II
CONCLUSIONS:
WWI (12 cases):
For the WWI battles, the nature of the prediction problems are summarized as:
CONCLUSION: In the case of the WWI runs, five of the problem engagements were due to confusion of defining a winner or a clear CEV existing for a side that should have been predictable. Seven out of the 23 runs have some problems, with three problems resolving themselves by assigning a CEV value to a side that may not have deserved it. One (Medeah Farm) was just off any way you look at it, and three suffered a problems because historically the defenders (Germans) suffered surprisingly low losses. Two had the battle outcome predicted correctly on the first run, and then had the outcome incorrectly predicted after a CEV was assigned.
With 5 to 7 clear failures (depending on how you count them), this leads one to conclude that the TNDM can be relied upon to predict the winner in a WWI battalion-level battle in about 70% of the cases.
WWII (8 cases):
For the WWII battles, the nature of the prediction problems are summarized as:
CONCLUSION: In the case of the WWII runs, three of the problem engagements were due to confusion of defining a winner or a clear CEV existing for a side that should have been predictable. Four out of the 23 runs suffered a problem because historically the defenders (Germans) suffered surprisingly low losses and one case just simply assigned a possible unjustifiable CEV. This led to the battle outcome being predicted correctly on the first run, then incorrectly predicted after CEV was assigned.
With 3 to 5 clear failures, one can conclude that the TNDM can be relied upon to predict the winner in a WWII battalion-level battle in about 80% of the cases.
Modern (8 cases):
For the post-WWll battles, the nature of the prediction problems are summarized as:
CONCLUSION: ln the case of the modem runs, only one result was a problem. In the other seven cases, when the force with superior training is given a reasonable CEV (usually around 2), then the correct outcome is achieved. With only one clear failure, one can conclude that the TNDM can be relied upon to predict the winner in a modern battalion-level battle in over 90% of the cases.
FINAL CONCLUSIONS: In this article, the predictive ability of the model was examined only for its ability to predict the winner/loser. We did not look at the accuracy of the casualty predictions or the accuracy of the rates of advance. That will be done in the next two articles. Nonetheless, we could not help but notice some trends.
First and foremost, while the model was expected to be a reasonably good predictor of WWII combat, it did even better for modem combat. It was noticeably weaker for WWI combat. In the case of the WWI data, all attrition figures were multiplied by 4 ahead of time because we knew that there would be a fit problem otherwise.
This would strongly imply that there were more significant changes to warfare between 1918 and 1939 than between 1939 and 1989.
Secondly, the model is a pretty good predictor of winner and loser in WWII and modern cases. Overall, the model predicted the winner in 68% of the cases on the first run and in 84% of the cases in the run incorporating CEV. While its predictive powers were not perfect, there were 13 cases where it just wasn’t getting a good result (17%). Over half of these were from WWI, only one from the modern period.
In some of these battles it was pretty obvious who was going to win. Therefore, the model needed to do a step better than 50% to be even considered. Historically, in 51 out of 76 cases (67%). the larger side in the battle was the winner. One could predict the winner/loser with a reasonable degree of success by just looking at that rule. But the percentage of the time the larger side won varied widely with the period. In WWI the larger side won 74% of the time. In WWII it was 87%. In the modern period it was a counter-intuitive 47% of the time, yet the model was best at selecting the winner in the modern period.
The model’s ability to predict WWI battles is still questionable. It obviously does a pretty good job with WWII battles and appears to be doing an excellent job in the modern period. We suspect that the difference in prediction rates between WWII and the modern period is caused by the selection of battles, not by any inherit ability of the model.
RECOMMENDED CHANGES: While it is too early to settle upon a model improvement program, just looking at the problems of winning and losing, and the ancillary data to that, leads me to three corrections:
Adjust for times of less than 24 hours. Create a formula so that battles of six hours in length are not 1/4 the casualties of a 24-hour battle, but something greater than that (possibly the square root of time). This adjustment should affect both casualties and advance rates.
Adjust advance rates for smaller unit: to account for the fact that smaller units move faster than larger units.
Adjust for fanaticism to account for those armies that continue to fight after most people would have accepted the result, driving up casualties for both sides.
The First Test of the TNDM Battalion-Level Validations: Predicting the Winners by Christopher A. Lawrence
Part I
In the basic concept of the TNDM battalion-level validation, we decided to collect data from battles from three periods: WWI, WWII, and post-WWII. We then made a TNDM run for each battle exactly as the battle was laid out, with both sides having the same CEV [Combat Effectiveness Value]. The results of that run indicated what the CEV should have been for the battle, and we then made a second run using that CEV. That was all we did. We wanted to make sure that there was no “tweaking” of the model for the validation, so we stuck rigidly to this procedure. We then evaluated each run for its fit in three areas:
Predicting the winner/loser
Predicting the casualties
Predicting the advance rate
We did end up changing two engagements around. We had a similar situation with one WWII engagement (Tenaru River) and one modern period engagement (Bir Gifgafa), where the defender received reinforcements part-way through the battle and counterattacked. In both cases we decided to run them as two separate battles (adding two more battles to our database), with the conditions from the first engagement being the starting strength, plus the reinforcements, for the second engagement. Based on our previous experience with running Goose Green, for all the Falklands Island battles we counted the Milans and Carl Gustavs as infantry weapons. That is the only “tweaking” we did that affected the battle outcome in the model. We also put in a casualty multiplier of 4 for WWI engagements, but that is discussed in the article on casualties.
This is the analysis of the first test, predicting the winner/loser. Basically, if the attacker won historically, we assigned it a value of 1, a draw was 0, and a defender win was -1. In the TNDM results summary, it has a column called “winner” which records either an attacker win, a draw, or a defender win. We compared these two results. If they were the same, this is a “correct” result. If they are “off by one,” this means the model predicted an attacker win or loss, where the actual result was a draw, or the model predicted a draw, where the actual result was a win or loss. If they are “off by two” then the model simply missed and predicted the wrong winner.
The results are (the envelope please….):
It is hard to determine a good predictability from a bad one. Obviously, the initial WWI prediction of 57% right is not very good, while the Modern second run result of 97% is quite good. What l would really like to do is compare these outputs to some other model (like TACWAR) to see if they get a closer fit. I have reason to believe that they will not do better.
Most cases in which the model was “off by 1″ were easily correctable by accounting for the different personnel capabilities of the army. Therefore, just to look where the model really failed. let‘s just look at where it simply got the wrong winner:
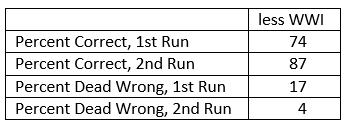
The TNDM is not designed or tested for WWI battles. It is basically designed to predict combat between 1939 and the present. The total percentages without the WWI data in it are:
Overall, based upon this data I would be willing to claim that the model can predict the correct winner 75% of the time without accounting for human factors and 90% of the time if it does.
CEVs: Quite simply a user of the TNDM must develop a CEV to get a good prediction. In this particular case, the CEVs were developed from the first run. This means that in the second run, the numbers have been juggled (by changing the CEV) to get a better result. This would make this effort meaningless if the CEVs were not fairly consistent over several engagements for one side versus its other side. Therefore, they are listed below in broad groupings so that the reader can determine if the CEVs appear to be basically valid or are simply being used as a “tweak.”
Now, let’s look where it went wrong. The following battles were not predicted correctly:
There are 19 night engagements in the data base, five from WWI, three from WWII, and 11 modern. We looked at whether the miss prediction was clustered among night engagements and that did not seem to be the case. Unable to find a pattern, we examined each engagement to see what the problem was. See the attachments at the end of this article for details.
We did obtain CEVs that showed some consistency. These are shown below. The Marines in World War l record the following CEVs in these WWI battles:
Compare those figures to the performance of the US Army:
In the above two and in all following cases, the italicized battles are the ones with which we had prediction problems.
For comparison purposes, the CEVs were recorded in the battles in World War II between the US and Japan:
For comparison purposes, the following CEVs were recorded in Operation Veritable:
These are the other engagements versus Germans for which CEVs were recorded:
For comparison purposes, the following CEVs were recorded in the post-WWII battles between Vietnamese forces and their opponents:
Note that the Americans have an average CEV advantage of 1 .6 over the NVA (only three cases) while having a 1.8 advantage over the VC (6 cases).
For comparison purposes, the following CEVs were recorded in the battles between the British and Argentine’s:
Numerical Adjustment of CEV Results: Averages and Means by Christopher A. Lawrence and David L. Bongard
As part of the battalion-level validation effort, we made two runs with the model for each test case—one without CEV [Combat Effectiveness Value] incorporated and one with the CEV incorporated. The printout of a TNDM [Tactical Numerical Deterministic Model] run has three CEV figures for each side: CEVt CEVl and CEVad. CEVt shows the CEV as calculated on the basis of battlefield results as a ratio of the performance of side a versus side b. It measures performance based upon three factors: mission accomplishment, advance, and casualty effectiveness. CEVt is calculated according to the following formula:
P′ = Refined Combat Power Ratio (sum of the modified OLls). The ′ in P′ indicates that this ratio has been “refined” (modified) by two behavioral values already: the factor for Surprise and the Set Piece Factor.
CEVd = 1/CEVa (the reciprocal)
In effect the formula is relative results multiplied by the modified combat power ratio. This is basically the formulation that was used for the QJM [Quantified Judgement Model].
In the TNDM Manual, there is an alternate CEV method based upon comparative effective lethality. This methodology has the advantage that the user doesn’t have to evaluate mission accomplishment on a ten point scale. The CEVI calculated according to the following formula:
In effect, CEVt is a measurement of the difference in results predicted by the model from actual historical results based upon assessment for three different factors (mission success, advance rates, and casualties), while CEVl is a measurement of the difference in predicted casualties from actual casualties. The CEVt and the CEVl of the defender is the reciprocal of the one for the attacker.
Now the problem comes in when one creates the CEVad, which is the average of the two CEVs above. l simply do not know why it was decided to create an alternate CEV calculation from the old QJM method, and then average the two, but this is what is currently being done in the model. This averaging results in a revised CEV for the attacker and for the defender that are not reciprocals of each other, unless the CEVt and the CEVl were the same. We even have some cases where both sides had a CEVad of greater than one. Also, by averaging the two, we have heavily weighted casualty effectiveness relative to mission effectiveness and mission accomplishment.
What was done in these cases (again based more on TDI tradition or habit, and not on any specific rule) was:
(1.) If CEVad are reciprocals, then use as is.
(2.) If one CEV is greater than one while the other is less than 1, then add the higher CEV to the value of the reciprocal of the lower CEV (1/x) and divide by two. This result is the CEV for the superior force, and its reciprocal is the CEV for the inferior force.
(3.) If both CEVs are above zero, then we divide the larger CEVad value by the smaller, and use its result as the superior force’s CEV.
In the case of (3.) above, this methodology usually results in a slightly higher CEV for the attacker side than if we used the average of the reciprocal (usually 0.1 or 0.2 higher). While the mathematical and logical consistency of the procedure bothered me, the logic for the different procedure in (3.) was that the model was clearly having a problem with predicting the engagement to start with, but that in most cases when this happened before (meaning before the validation), a higher CEV usually produced a better fit than a lower one. As this is what was done before. I accepted it as is, especially if one looks at the example of Mediah Farm. If one averages the reciprocal with the US’s CEV of 8.065, one would get a CEV of 4.13. By the methodology in (3.), one comes up with a more reasonable US CEV of 1.58.
The interesting aspect is that the TNDM rules manual explains how CEVt, CEVl and CEVad are calculated, but never is it explained which CEVad (attacker or defender) should be used. This is the first explanation of this process, and was based upon the “traditions” used at TDI. There is a strong argument to merge the two CEVs into one formulation. I am open to another methodology for calculating CEV. I am not satisfied with how CEV is calculated in the TNDM and intend to look into this further. Expect another article on this subject in the next issue.
Is this the only innovation in weapons technology in history with the ability in itself to change warfare and alter the balance of power? Trevor Dupuy thought it might be. Shot IVY-MIKE, Eniwetok Atoll, 1 November 1952. [Wikimedia]
Trevor Dupuy was skeptical about the role of technology in determining outcomes in warfare. While he did believe technological innovation was crucial, he did not think that technology itself has decided success or failure on the battlefield. As he wrote posthumously in 1997,
I am a humanist, who is also convinced that technology is as important today in war as it ever was (and it has always been important), and that any national or military leader who neglects military technology does so to his peril and that of his country. But, paradoxically, perhaps to an extent even greater than ever before, the quality of military men is what wins wars and preserves nations. (emphasis added)
His conclusion was largely based upon his quantitative approach to studying military history, particularly the way humans have historically responded to the relentless trend of increasingly lethal military technology.
The Historical Relationship Between Weapon Lethality and Battle Casualty Rates
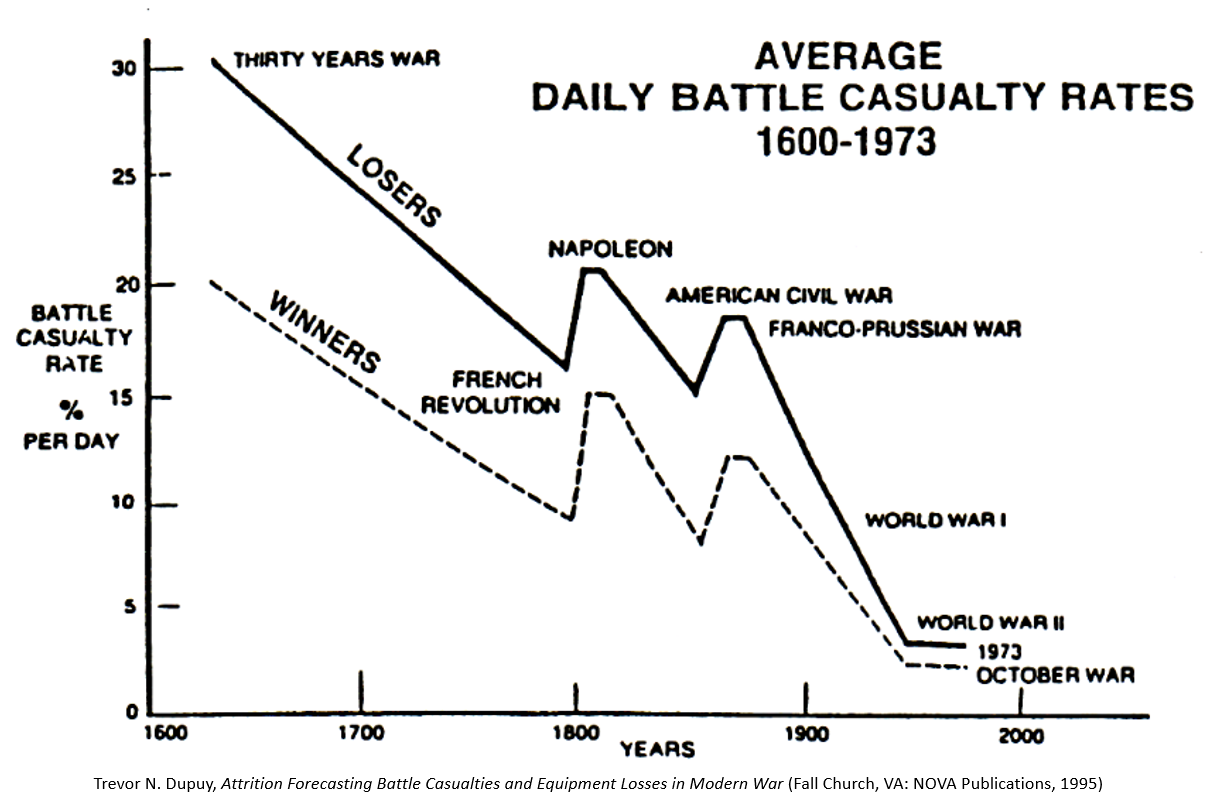
Based on a 1964 study for the U.S. Army, Dupuy identified a long-term historical relationship between increasing weapon lethality and decreasing average daily casualty rates in battle. (He summarized these findings in his book, The Evolution of Weapons and Warfare (1980). The quotes below are taken from it.)
Since antiquity, military technological development has produced weapons of ever increasing lethality. The rate of increase in lethality has grown particularly dramatically since the mid-19th century.
However, in contrast, the average daily casualty rate in combat has been in decline since 1600. With notable exceptions during the 19th century, casualty rates have continued to fall through the late 20th century. If technological innovation has produced vastly more lethal weapons, why have there been fewer average daily casualties in battle?
the granting of greater freedom to maneuver through decentralized decision-making and enhanced mobility; and
improved use of combined arms and interservice coordination.
Technological Innovation and Organizational Assimilation
Dupuy noted that the historical correlation between weapons development and their use in combat has not been linear because the pace of integration has been largely determined by military leaders, not the rate of technological innovation. “The process of doctrinal assimilation of new weapons into compatible tactical and organizational systems has proved to be much more significant than invention of a weapon or adoption of a prototype, regardless of the dimensions of the advance in lethality.” [p. 337]
As a result, the history of warfare has been exemplified more often by a discontinuity between weapons and tactical systems than effective continuity.
During most of military history there have been marked and observable imbalances between military efforts and military results, an imbalance particularly manifested by inconclusive battles and high combat casualties. More often than not this imbalance seems to be the result of incompatibility, or incongruence, between the weapons of warfare available and the means and/or tactics employing the weapons. [p. 341]
In short, military organizations typically have not been fully effective at exploiting new weapons technology to advantage on the battlefield. Truly decisive alignment between weapons and systems for their employment has been exceptionally rare. Dupuy asserted that
There have been six important tactical systems in military history in which weapons and tactics were in obvious congruence, and which were able to achieve decisive results at small casualty costs while inflicting disproportionate numbers of casualties. These systems were:
the Macedonian system of Alexander the Great, ca. 340 B.C.
the Roman system of Scipio and Flaminius, ca. 200 B.C.
the Mongol system of Ghengis Khan, ca. A.D. 1200
the English system of Edward I, Edward III, and Henry V, ca. A.D. 1350
the French system of Napoleon, ca. A.D. 1800
the German blitzkrieg system, ca. A.D. 1940 [p. 341]
With one caveat, Dupuy could not identify any single weapon that had decisively changed warfare in of itself without a corresponding human adaptation in its use on the battlefield.
Save for the recent significant exception of strategic nuclear weapons, there have been no historical instances in which new and lethal weapons have, of themselves, altered the conduct of war or the balance of power until they have been incorporated into a new tactical system exploiting their lethality and permitting their coordination with other weapons; the full significance of this one exception is not yet clear, since the changes it has caused in warfare and the influence it has exerted on international relations have yet to be tested in war.
Until the present time, the application of sound, imaginative thinking to the problem of warfare (on either an individual or an institutional basis) has been more significant than any new weapon; such thinking is necessary to real assimilation of weaponry; it can also alter the course of human affairs without new weapons. [p. 340]
Technological Superiority and Offset Strategies
Will new technologies like robotics and artificial intelligence provide the basis for a seventh tactical system where weapons and their use align with decisive battlefield results? Maybe. If Dupuy’s analysis is accurate, however, it is more likely that future increases in weapon lethality will continue to be counterbalanced by human ingenuity in how those weapons are used, yielding indeterminate—perhaps costly and indecisive—battlefield outcomes.
Genuinely effective congruence between weapons and force employment continues to be difficult to achieve. Dupuy believed the preconditions necessary for successful technological assimilation since the mid-19th century have been a combination of conducive military leadership; effective coordination of national economic, technological-scientific, and military resources; and the opportunity to evaluate and analyze battlefield experience.
Can the U.S. meet these preconditions? That certainly seemed to be the goal of the so-called Third Offset Strategy, articulated in 2014 by the Obama administration. It called for maintaining “U.S. military superiority over capable adversaries through the development of novel capabilities and concepts.” Although the Trump administration has stopped using the term, it has made “maximizing lethality” the cornerstone of the 2018 National Defense Strategy, with increased funding for the Defense Department’s modernization priorities in FY2019 (though perhaps not in FY2020).
Dupuy’s original work on weapon lethality in the 1960s coincided with development in the U.S. of what advocates of a “revolution in military affairs” (RMA) have termed the “First Offset Strategy,” which involved the potential use of nuclear weapons to balance Soviet superiority in manpower and material. RMA proponents pointed to the lopsided victory of the U.S. and its allies over Iraq in the 1991 Gulf War as proof of the success of a “Second Offset Strategy,” which exploited U.S. precision-guided munitions, stealth, and intelligence, surveillance, and reconnaissance systems developed to counter the Soviet Army in Germany in the 1980s. Dupuy was one of the few to attribute the decisiveness of the Gulf War both to airpower and to the superior effectiveness of U.S. combat forces.
Trevor Dupuy certainly was not an anti-technology Luddite. He recognized the importance of military technological advances and the need to invest in them. But he believed that the human element has always been more important on the battlefield. Most wars in history have been fought without a clear-cut technological advantage for one side; some have been bloody and pointless, while others have been decisive for reasons other than technology. While the future is certainly unknown and past performance is not a guarantor of future results, it would be a gamble to rely on technological superiority alone to provide the margin of success in future warfare.
Response to Niklas Zetterling’s Article by Christopher A. Lawrence
Mr. Zetterling is currently a professor at the Swedish War College and previously worked at the Swedish National Defense Research Establishment. As I have been having an ongoing dialogue with Prof. Zetterling on the Battle of Kursk, I have had the opportunity to witness his approach to researching historical data and the depth of research. I would recommend that all of our readers take a look at his recent article in the Journal of Slavic Military Studies entitled “Loss Rates on the Eastern Front during World War II.” Mr. Zetterling does his German research directly from the Captured German Military Records by purchasing the rolls of microfilm from the US National Archives. He is using the same German data sources that we are. Let me attempt to address his comments section by section:
The Database on Italy 1943-44:
Unfortunately, the Italian combat data was one of the early HERO research projects, with the results first published in 1971. I do not know who worked on it nor the specifics of how it was done. There are references to the Captured German Records, but significantly, they only reference division files for these battles. While I have not had the time to review Prof. Zetterling‘s review of the original research. I do know that some of our researchers have complained about parts of the Italian data. From what I’ve seen, it looks like the original HERO researchers didn’t look into the Corps and Army files, and assumed what the attached Corps artillery strengths were. Sloppy research is embarrassing, although it does occur, especially when working under severe financial constraints (for example, our Battalion-level Operations Database). If the research is sloppy or hurried, or done from secondary sources, then hopefully the errors are random, and will effectively counterbalance each other, and not change the results of the analysis. If the errors are all in one direction, then this will produce a biased result.
I have no basis to believe that Prof. Zetterling’s criticism is wrong, and do have many reasons to believe that it is correct. Until l can take the time to go through the Corps and Army files, I intend to operate under the assumption that Prof. Zetterling’s corrections are good. At some point I will need to go back through the Italian Campaign data and correct it and update the Land Warfare Database. I did compare Prof. Zetterling‘s list of battles with what was declared to be the forces involved in the battle (according to the Combat Data Subscription Service) and they show the following attached artillery:
It is clear that the battles were based on the assumption that here was Corps-level German artillery. A strength comparison between the two sides is displayed in the chart on the next page.
The Result Formula:
CEV is calculated from three factors. Therefore a consistent 20% error in casualties will result in something less than a 20% error in CEV. The mission effectiveness factor is indeed very “fuzzy,” and these is simply no systematic method or guidance in its application. Sometimes, it is not based upon the assigned mission of the unit, but its perceived mission based upon the analyst’s interpretation. But, while l have the same problems with the mission accomplishment scores as Mr. Zetterling, I do not have a good replacement. Considering the nature of warfare, I would hate to create CEVs without it. Of course, Trevor Dupuy was experimenting with creating CEVs just from casualty effectiveness, and by averaging his two CEV scores (CEVt and CEVI) he heavily weighted the CEV calculation for the TNDM towards measuring primarily casualty effectiveness (see the article in issue 5 of the Newsletter, “Numerical Adjustment of CEV Results: Averages and Means“). At this point, I would like to produce a new, single formula for CEV to replace the current two and its averaging methodology. I am open to suggestions for this.
Supply Situation:
The different ammunition usage rate of the German and US Armies is one of the reasons why adding a logistics module is high on my list of model corrections. This was discussed in Issue 2 of the Newsletter, “Developing a Logistics Model for the TNDM.” As Mr. Zetterling points out, “It is unlikely that an increase in artillery ammunition expenditure will result in a proportional increase in combat power. Rather it is more likely that there is some kind of diminished return with increased expenditure.” This parallels what l expressed in point 12 of that article: “It is suspected that this increase [in OLIs] will not be linear.”
The CEV does include “logistics.” So in effect, if one had a good logistics module, the difference in logistics would be accounted for, and the Germans (after logistics is taken into account) may indeed have a higher CEV.
General Problems with Non-Divisional Units Tooth-to-Tail Ratio
Point taken. The engagements used to test the TNDM have been gathered over a period of over 25 years, by different researchers and controlled by different management. What is counted when and where does change from one group of engagements to the next. While l do think this has not had a significant result on the model outcomes, it is “sloppy” and needs to be addressed.
The Effects of Defensive Posture
This is a very good point. If the budget was available, my first step in “redesigning” the TNDM would be to try to measure the effects of terrain on combat through the use of a large LWDB-type database and regression analysis. I have always felt that with enough engagements, one could produce reliable values for these figures based upon something other than judgement. Prof. Zetterling’s proposed methodology is also a good approach, easier to do, and more likely to get a conclusive result. I intend to add this to my list of model improvements.
Conclusions
There is one other problem with the Italian data that Prof. Zetterling did not address. This was that the Germans and the Allies had different reporting systems for casualties. Quite simply, the Germans did not report as casualties those people who were lightly wounded and treated and returned to duty from the divisional aid station. The United States and England did. This shows up when one compares the wounded to killed ratios of the various armies, with the Germans usually having in the range of 3 to 4 wounded for every one killed, while the allies tend to have 4 to 5 wounded for every one killed. Basically, when comparing the two reports, the Germans “undercount” their casualties by around 17 to 20%. Therefore, one probably needs to use a multiplier of 20 to 25% to match the two casualty systems. This was not taken into account in any the work HERO did.
Because Trevor Dupuy used three factors for measuring his CEV, this error certainly resulted in a slightly higher CEV for the Germans than should have been the case, but not a 20% increase. As Prof. Zetterling points out, the correction of the count of artillery pieces should result in a higher CEV than Col. Dupuy calculated. Finally, if Col. Dupuy overrated the value of defensive terrain, then this may result in the German CEV being slightly lower.
As you may have noted in my list of improvements (Issue 2, “Planned Improvements to the TNDM”), I did list “revalidating” to the QJM Database. [NOTE: a summary of the QJM/TNDM validation efforts can be found here.] As part of that revalidation process, we would need to review the data used in the validation data base first, account for the casualty differences in the reporting systems, and determine if the model indeed overrates the effect of terrain on defense.
Perhaps one of the most debated results of the TNDM (and its predecessors) is the conclusion that the German ground forces on average enjoyed a measurable qualitative superiority over its US and British opponents. This was largely the result of calculations on situations in Italy in 1943-44, even though further engagements have been added since the results were first presented. The calculated German superiority over the Red Army, despite the much smaller number of engagements, has not aroused as much opposition. Similarly, the calculated Israeli effectiveness superiority over its enemies seems to have surprised few.
However, there are objections to the calculations on the engagements in Italy 1943. These concern primarily the database, but there are also some questions to be raised against the way some of the calculations have been made, which may possibly have consequences for the TNDM.
Here it is suggested that the German CEV [combat effectiveness value] superiority was higher than originally calculated. There are a number of flaws in the original calculations, each of which will be discussed separately below. With the exception of one issue, all of them, if corrected, tend to give a higher German CEV.
The Database on Italy 1943-44
According to the database the German divisions had considerable fire support from GHQ artillery units. This is the only possible conclusion from the fact that several pieces of the types 15cm gun, 17cm gun, 21cm gun, and 15cm and 21cm Nebelwerfer are included in the data for individual engagements. These types of guns were almost exclusively confined to GHQ units. An example from the database are the three engagements Port of Salerno, Amphitheater, and Sele-Calore Corridor. These take place simultaneously (9-11 September 1943) with the German 16th Pz Div on the Axis side in all of them (no other division is included in the battles). Judging from the manpower figures, it seems to have been assumed that the division participated with one quarter of its strength in each of the two former battles and half its strength in the latter. According to the database, the number of guns were:
15cm gun
28
17cm gun
12
21cm gun
12
15cm NbW
27
21cm NbW
21
This would indicate that the 16th Pz Div was supported by the equivalent of more than five non-divisional artillery battalions. For the German army this is a suspiciously high number, usually there were rather something like one GHQ artillery battalion for each division, or even less. Research in the German Military Archives confirmed that the number of GHQ artillery units was far less than indicated in the HERO database. Among the useful documents found were a map showing the dispositions of 10th Army artillery units. This showed clearly that there was only one non-divisional artillery unit south of Rome at the time of the Salerno landings, the III/71 Nebelwerfer Battalion. Also the 557th Artillery Battalion (17cm gun) was present, it was included in the artillery regiment (33rd Artillery Regiment) of 15th Panzergrenadier Division during the second half of 1943. Thus the number of German artillery pieces in these engagements is exaggerated to an extent that cannot be considered insignificant. Since OLI values for artillery usually constitute a significant share of the total OLI of a force in the TNDM, errors in artillery strength cannot be dismissed easily.
While the example above is but one, further archival research has shown that the same kind of error occurs in all the engagements in September and October 1943. It has not been possible to check the engagements later during 1943, but a pattern can be recognized. The ratio between the numbers of various types of GHQ artillery pieces does not change much from battle to battle. It seems that when the database was developed, the researchers worked with the assumption that the German corps and army organizations had organic artillery, and this assumption may have been used as a “rule of thumb.” This is wrong, however; only artillery staffs, command and control units were included in the corps and army organizations, not firing units. Consequently we have a systematic error, which cannot be corrected without changing the contents of the database. It is worth emphasizing that we are discussing an exaggeration of German artillery strength of about 100%, which certainly is significant. Comparing the available archival records with the database also reveals errors in numbers of tanks and antitank guns, but these are much smaller than the errors in artillery strength. Again these errors do always inflate the German strength in those engagements l have been able to check against archival records. These errors tend to inflate German numerical strength, which of course affects CEV calculations. But there are further objections to the CEV calculations.
The Result Formula
The “result formula” weighs together three factors: casualties inflicted, distance advanced, and mission accomplishment. It seems that the first two do not raise many objections, even though the relative weight of them may always be subject to argumentation.
The third factor, mission accomplishment, is more dubious however. At first glance it may seem to be natural to include such a factor. Alter all, a combat unit is supposed to accomplish the missions given to it. However, whether a unit accomplishes its mission or not depends both on its own qualities as well as the realism of the mission assigned. Thus the mission accomplishment factor may reflect the qualities of the combat unit as well as the higher HQs and the general strategic situation. As an example, the Rapido crossing by the U.S. 36th Infantry Division can serve. The division did not accomplish its mission, but whether the mission was realistic, given the circumstances, is dubious. Similarly many German units did probably, in many situations, receive unrealistic missions, particularly during the last two years of the war (when most of the engagements in the database were fought). A more extreme example of situations in which unrealistic missions were given is the battle in Belorussia, June-July 1944, where German units were regularly given impossible missions. Possibly it is a general trend that the side which is fighting at a strategic disadvantage is more prone to give its combat units unrealistic missions.
On the other hand it is quite clear that the mission assigned may well affect both the casualty rates and advance rates. If, for example, the defender has a withdrawal mission, advance may become higher than if the mission was to defend resolutely. This must however not necessarily be handled by including a missions factor in a result formula.
I have made some tentative runs with the TNDM, testing with various CEV values to see which value produced an outcome in terms of casualties and ground gained as near as possible to the historical result. The results of these runs are very preliminary, but the tendency is that higher German CEVs produce more historical outcomes, particularly concerning combat.
Supply Situation
According to scattered information available in published literature, the U.S. artillery fired more shells per day per gun than did German artillery. In Normandy, US 155mm M1 howitzers fired 28.4 rounds per day during July, while August showed slightly lower consumption, 18 rounds per day. For the 105mm M2 howitzer the corresponding figures were 40.8 and 27.4. This can be compared to a German OKH study which, based on the experiences in Russia 1941-43, suggested that consumption of 105mm howitzer ammunition was about 13-22 rounds per gun per day, depending on the strength of the opposition encountered. For the 150mm howitzer the figures were 12-15.
While these figures should not be taken too seriously, as they are not from primary sources and they do also reflect the conditions in different theaters, they do at least indicate that it cannot be taken for granted that ammunition expenditure is proportional to the number of gun barrels. In fact there also exist further indications that Allied ammunition expenditure was greater than the German. Several German reports from Normandy indicate that they were astonished by the Allied ammunition expenditure.
It is unlikely that an increase in artillery ammunition expenditure will result in a proportional increase combat power. Rather it is more likely that there is some kind of diminished return with increased expenditure.
General Problems with Non-Divisional Units
A division usually (but not necessarily) includes various support services, such as maintenance, supply, and medical services. Non-divisional combat units have to a greater extent to rely on corps and army for such support. This makes it complicated to include such units, since when entering, for example, the manpower strength and truck strength in the TNDM, it is difficult to assess their contribution to the overall numbers.
Furthermore, the amount of such forces is not equal on the German and Allied sides. In general the Allied divisional slice was far greater than the German. In Normandy the US forces on 25 July 1944 had 812,000 men on the Continent, while the number of divisions was 18 (including the 5th Armored, which was in the process of landing on the 25th). This gives a divisional slice of 45,000 men. By comparison the German 7th Army mustered 16 divisions and 231,000 men on 1 June 1944, giving a slice of 14,437 men per division. The main explanation for the difference is the non-divisional combat units and the logistical organization to support them. In general, non-divisional combat units are composed of powerful, but supply-consuming, types like armor, artillery, antitank and antiaircraft. Thus their contribution to combat power and strain on the logistical apparatus is considerable. However I do not believe that the supporting units’ manpower and vehicles have been included in TNDM calculations.
There are however further problems with non-divisional units. While the whereabouts of tank and tank destroyer units can usually be established with sufficient certainty, artillery can be much harder to pin down to a specific division engagement. This is of course a greater problem when the geographical extent of a battle is small.
Tooth-to-Tail Ratio
Above was discussed the lack of support units in non-divisional combat units. One effect of this is to create a force with more OLI per man. This is the result of the unit‘s “tail” belonging to some other part of the military organization.
In the TNDM there is a mobility formula, which tends to favor units with many weapons and vehicles compared to the number of men. This became apparent when I was performing a great number of TNDM runs on engagements between Swedish brigades and Soviet regiments. The Soviet regiments usually contained rather few men, but still had many AFVs, artillery tubes, AT weapons, etc. The Mobility Formula in TNDM favors such units. However, I do not think this reflects any phenomenon in the real world. The Soviet penchant for lean combat units, with supply, maintenance, and other services provided by higher echelons, is not a more effective solution in general, but perhaps better suited to the particular constraints they were experiencing when forming units, training men, etc. In effect these services were existing in the Soviet army too, but formally not with the combat units.
This problem is to some extent reminiscent to how density is calculated (a problem discussed by Chris Lawrence in a recent issue of the Newsletter). It is comparatively easy to define the frontal limit of the deployment area of force, and it is relatively easy to define the lateral limits too. It is, however, much more difficult to say where the rear limit of a force is located.
When entering forces in the TNDM a rear limit is, perhaps unintentionally, drawn. But if the combat unit includes support units, the rear limit is pushed farther back compared to a force whose combat units are well separated from support units.
To what extent this affects the CEV calculations is unclear. Using the original database values, the German forces are perhaps given too high combat strength when the great number of GHQ artillery units is included. On the other hand, if the GHQ artillery units are not included, the opposite may be true.
The Effects of Defensive Posture
The posture factors are difficult to analyze, since they alone do not portray the advantages of defensive position. Such effects are also included in terrain factors.
It seems that the numerical values for these factors were assigned on the basis of professional judgement. However, when the QJM was developed, it seems that the developers did not assume the German CEV superiority. Rather, the German CEV superiority seems to have been discovered later. It is possible that the professional judgement was about as wrong on the issue of posture effects as they were on CEV. Since the British and American forces were predominantly on the offensive, while the Germans mainly defended themselves, a German CEV superiority may, at least partly, be hidden in two high effects for defensive posture.
When using corrected input data on the 20 situations in Italy September-October 1943, there is a tendency that the German CEV is higher when they attack. Such a tendency is also discernible in the engagements presented in Hitler’s Last Gamble. Appendix H, even though the number of engagements in the latter case is very small.
As it stands now this is not really more than a hypothesis, since it will take an analysis of a greater number of engagements to confirm it. However, if such an analysis is done, it must be done using several sets of data. German and Allied attacks must be analyzed separately, and preferably the data would be separated further into sets for each relevant terrain type. Since the effects of the defensive posture are intertwined with terrain factors, it is very much possible that the factors may be correct for certain terrain types, while they are wrong for others. It may also be that the factors can be different for various opponents (due to differences in training, doctrine, etc.). It is also possible that the factors are different if the forces are predominantly composed of armor units or mainly of infantry.
One further problem with the effects of defensive position is that it is probably strongly affected by the density of forces. It is likely that the main effect of the density of forces is the inability to use effectively all the forces involved. Thus it may be that this factor will not influence the outcome except when the density is comparatively high. However, what can be regarded as “high” is probably much dependent on terrain, road net quality, and the cross-country mobility of the forces.
Conclusions
While the TNDM has been criticized here, it is also fitting to praise the model. The very fact that it can be criticized in this way is a testimony to its openness. In a sense a model is also a theory, and to use Popperian terminology, the TNDM is also very testable.
It should also be emphasized that the greatest errors are probably those in the database. As previously stated, I can only conclude safely that the data on the engagements in Italy in 1943 are wrong; later engagements have not yet been checked against archival documents. Overall the errors do not represent a dramatic change in the CEV values. Rather, the Germans seem to have (in Italy 1943) a superiority on the order of 1.4-1.5, compared to an original figure of 1.2-1.3.
During September and October 1943, almost all the German divisions in southern Italy were mechanized or parachute divisions. This may have contributed to a higher German CEV. Thus it is not certain that the conclusions arrived at here are valid for German forces in general, even though this factor should not be exaggerated, since many of the German divisions in Italy were either newly raised (e.g., 26th Panzer Division) or rebuilt after the Stalingrad disaster (16th Panzer Division plus 3rd and 29th Panzergrenadier Divisions) or the Tunisian debacle (15th Panzergrenadier Division).
Missile fire lit up the Damascus sky last week as the U.S. and allies launched an attack on chemical weapons sites. [Hassan Ammar, AP/USA Today]
Even as pundits and wonks debate the political and strategic impact of the 14 April combined U.S., British, and French cruise missile strike on Assad regime chemical warfare targets in Syria, it has become clear that effort was a notable tactical success.
Despite ample warning that the strike was coming, the Syrian regime’s Russian-made S-200 surface-to-air missile defense system failed to shoot down a single incoming missile. The U.S. Defense Department claimed that all 105 cruise missiles fired struck their targets. It also reported that the Syrians fired 40 interceptor missiles but nearly all launched after the incoming cruise missiles had already struck their targets.
Although cruise missiles are difficult to track and engage even with fully modernized air defense systems, the dismal performance of the Syrian network was a surprise to many analysts given the wary respect paid to it by U.S. military leaders in the recent past. Although the S-200 dates from the 1960s, many surmise an erosion in the combat effectiveness of the personnel manning the system is the real culprit.
[A] lack of training, command and control and other human factors are probably responsible for the failure, analysts said.
“It’s not just about the physical capability of the air defense system,” said David Deptula, a retired, three-star Air Force general. “It’s about the people who are operating the system.”
The Syrian regime has become dependent upon assistance from Russia and Iran to train, equip, and maintain its military forces. Russian forces in Syria have deployed the more sophisticated S-400 air defense system to protect their air and naval bases, which reportedly tracked but did not engage the cruise missile strike. The Assad regime is also believed to field the Russian-made Pantsir missile and air-defense artillery system, but it likely was not deployed near enough to the targeted facilities to help.
Despite the pervasive role technology plays in modern warfare, the human element remains the most important factor in determining combat effectiveness.
Technology and the Human Factor in War by Trevor N. Dupuy
The Debate
It has become evident to many military theorists that technology has become increasingly important in war. In fact (even though many soldiers would not like to admit it) most such theorists believe that technology has actually reduced the significance of the human factor in war, In other words, the more advanced our military technology, these “technocrats” believe, the less we need to worry about the professional capability and competence of generals, admirals, soldiers, sailors, and airmen.
The technocrats believe that the results of the Kuwait, or Gulf, War of 1991 have confirmed their conviction. They cite the contribution to those results of the U.N. (mainly U.S.) command of the air, stealth aircraft, sophisticated guided missiles, and general electronic superiority, They believe that it was technology which simply made irrelevant the recent combat experience of the Iraqis in their long war with Iran.
Yet there are a few humanist military theorists who believe that the technocrats have totally misread the lessons of this century‘s wars! They agree that, while technology was important in the overwhelming U.N. victory, the principal reason for the tremendous margin of U.N. superiority was the better training, skill, and dedication of U.N. forces (again, mainly U.S.).
And so the debate rests. Both sides believe that the result of the Kuwait War favors their point of view, Nevertheless, an objective assessment of the literature in professional military journals, of doctrinal trends in the U.S. services, and (above all) of trends in the U.S. defense budget, suggest that the technocrats have stronger arguments than the humanists—or at least have been more convincing in presenting their arguments.
I suggest, however, that a completely impartial comparison of the Kuwait War results with those of other recent wars, and with some of the phenomena of World War II, shows that the humanists should not yet concede the debate.
I am a humanist, who is also convinced that technology is as important today in war as it ever was (and it has always been important), and that any national or military leader who neglects military technology does so to his peril and that of his country, But, paradoxically, perhaps to an extent even greater than ever before, the quality of military men is what wins wars and preserves nations.
To elevate the debate beyond generalities, and demonstrate convincingly that the human factor is at least as important as technology in war, I shall review eight instances in this past century when a military force has been successful because of the quality if its people, even though the other side was at least equal or superior in the technological sophistication of its weapons. The examples I shall use are:
Germany vs. the USSR in World War II
Germany vs. the West in World War II
Israel vs. Arabs in 1948, 1956, 1967, 1973 and 1982
The Vietnam War, 1965-1973
Britain vs. Argentina in the Falklands 1982
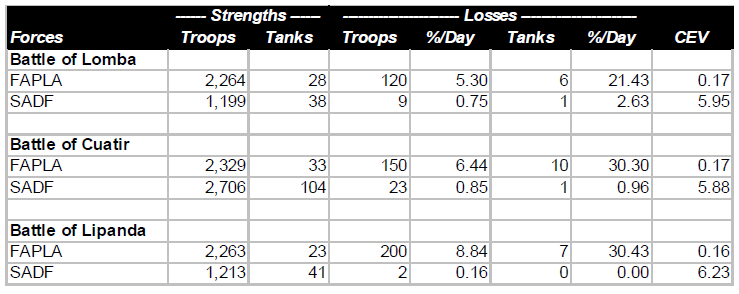
South Africans vs. Angolans and Cubans, 1987-88
The U.S. vs. Iraq, 1991
The demonstration will be based upon a marshaling of historical facts, then analyzing those facts by means of a little simple arithmetic.
Relative Combat Effectiveness Value (CEV)
The purpose of the arithmetic is to calculate relative combat effectiveness values (CEVs) of two opposing military forces. Let me digress to set up the arithmetic. Although some people who hail from south of the Mason-Dixon Line may be reluctant to accept the fact, statistics prove that the fighting quality of Northern soldiers and Southern soldiers was virtually equal in the American Civil War. (I invite those who might disagree to look at Livermore’s Numbers and Losses in the Civil War). That assumption of equality of the opposing troop quality in the Civil War enables me to assert that the successful side in every important battle in the Civil War was successful either because of numerical superiority or superior generalship. Three of Lee’s battles make the point:
Despite being outnumbered, Lee won at Antietam. (Though Antietam is sometimes claimed as a Union victory, Lee, the defender, held the battlefield; McClellan, the attacker, was repulsed.) The main reason for Lee’s success was that on a scale of leadership his generalship was worth 10, while McClellan was barely a 6.
Despite being outnumbered, Lee won at Chancellorsville because he was a 10 to Hooker’s 5.
Lee lost at Gettysburg mainly because he was outnumbered. Also relevant: Meade did not lose his nerve (like McClellan and Hooker) with generalship worth 8 to match Lee’s 8.
Let me use Antietam to show the arithmetic involved in those simple analyses of a rather complex subject:
The numerical strength of McClellan’s army was 89,000; Lee’s army was only 39,000 strong, but had the multiplier benefit of defensive posture. This enables us to calculate the theoretical combat power ratio of the Union Army to the Confederate Army as 1.4:1.0. In other words, with substantial preponderance of force, the Union Army should have been successful. (The combat power ratio of Confederates to Northerners, of course, was the reciprocal, or 0.71:1.04)
However, Lee held the battlefield, and a calculation of the actual combat power ratio of the two sides (based on accomplishment of mission, gaining or holding ground, and casualties) was a scant, but clear cut: 1.16:1.0 in favor of the Confederates. A ratio of the actual combat power ratio of the Confederate/Union armies (1.16) to their theoretical combat power (0.71) gives us a value of 1.63. This is the relative combat effectiveness of the Lee’s army to McClellan’s army on that bloody day. But, if we agree that the quality of the troops was the same, then the differential must essentially be in the quality of the opposing generals. Thus, Lee was a 10 to McClellan‘s 6.
The simple arithmetic equation[1] on which the above analysis was based is as follows:
CEV = (R/R)/(P/P)
When:
CEV is relative Combat Effectiveness Value
R/R is the actual combat power ratio
P/P is the theoretical combat power ratio.
At Antietam the equation was: 1.63 = 1.16/0.71.
We’ll be revisiting that equation in connection with each of our examples of the relative importance of technology and human factors.
Air Power and Technology
However, one more digression is required before we look at the examples. Air power was important in all eight of the 20th Century examples listed above. Offhand it would seem that the exercise of air superiority by one side or the other is a manifestation of technological superiority. Nevertheless, there are a few examples of an air force gaining air superiority with equivalent, or even inferior aircraft (in quality or numbers) because of the skill of the pilots.
However, the instances of such a phenomenon are rare. It can be safely asserted that, in the examples used in the following comparisons, the ability to exercise air superiority was essentially a technological superiority (even though in some instances it was magnified by human quality superiority). The one possible exception might be the Eastern Front in World War II, where a slight German technological superiority in the air was offset by larger numbers of Soviet aircraft, thanks in large part to Lend-Lease assistance from the United States and Great Britain.
The Battle of Kursk, 5-18 July, 1943
Following the surrender of the German Sixth Army at Stalingrad, on 2 February, 1943, the Soviets mounted a major winter offensive in south-central Russia and Ukraine which reconquered large areas which the Germans had overrun in 1941 and 1942. A brilliant counteroffensive by German Marshal Erich von Manstein‘s Army Group South halted the Soviet advance, and recaptured the city of Kharkov in mid-March. The end of these operations left the Soviets holding a huge bulge, or salient, jutting westward around the Russian city of Kursk, northwest of Kharkov.
The Germans promptly prepared a new offensive to cut off the Kursk salient, The Soviets energetically built field fortifications to defend the salient against expected German attacks. The German plan was for simultaneous offensives against the northern and southern shoulders of the base of the Kursk salient, Field Marshal Gunther von K1uge’s Army Group Center, would drive south from the vicinity of Orel, while Manstein’s Army Group South pushed north from the Kharkov area, The offensive was originally scheduled for early May, but postponements by Hitler, to equip his forces with new tanks, delayed the operation for two months, The Soviets took advantage of the delays to further improve their already formidable defenses.
The German attacks finally began on 5 July. In the north General Walter Model’s German Ninth Army was soon halted by Marshal Konstantin Rokossovski’s Army Group Center. In the south, however, German General Hermann Hoth’s Fourth Panzer Army and a provisional army commanded by General Werner Kempf, were more successful against the Voronezh Army Group of General Nikolai Vatutin. For more than a week the XLVIII Panzer Corps advanced steadily toward Oboyan and Kursk through the most heavily fortified region since the Western Front of 1918. While the Germans suffered severe casualties, they inflicted horrible losses on the defending Soviets. Advancing similarly further east, the II SS Panzer Corps, in the largest tank battle in history, repulsed a vigorous Soviet armored counterattack at Prokhorovka on July 12-13, but was unable to continue to advance.
The principal reason for the German halt was the fact that the Soviets had thrown into the battle General Ivan Konev’s Steppe Army Group, which had been in reserve. The exhausted, heavily outnumbered Germans had no comparable reserves to commit to reinvigorate their offensive.
A comparison of forces and losses of the Soviet Voronezh Army Group and German Army Group South on the south face of the Kursk Salient is shown below. The strengths are averages over the 12 days of the battle, taking into consideration initial strengths, losses, and reinforcements.
A comparison of the casualty tradeoff can be found by dividing Soviet casualties by German strength, and German losses by Soviet strength. On that basis, 100 Germans inflicted 5.8 casualties per day on the Soviets, while 100 Soviets inflicted 1.2 casualties per day on the Germans, a tradeoff of 4.9 to 1.0
The statistics for the 8-day offensive of the German XLVIII Panzer Corps toward Oboyan are shown below. Also shown is the relative combat effectiveness value (CEV) of Germans and Soviets, as calculated by the TNDM. As was the case for the Battle of Antietam, this is derived from a mathematical comparison of the theoretical combat power ratio of the two forces (simply considering numbers and weapons characteristics), and the actual combat power ratios reflected by the battle results:
The calculated CEVs suggest that 100 German troops were the combat equivalent of 240 Soviet troops, comparably equipped. The casualty tradeoff in this battle shows that 100 Germans inflicted 5.15 casualties per day on the Soviets, while 100 Soviets inflicted 1.11 casualties per day on the Germans, a tradeoff of4.64. It is a rule of thumb that the casualty tradeoff is usually about the square of the CEV.
A similar comparison can be made of the two-day battle of Prokhorovka. Soviet accounts of that battle have claimed this as a great victory by the Soviet Fifth Guards Tank Army over the German II SS Panzer Corps. In fact, since the German advance was halted, the outcome was close to a draw, but with the advantage clearly in favor of the Germans.
The casualty tradeoff shows that 100 Germans inflicted 7.7 casualties per on the Soviets, while 100 Soviets inflicted 1.0 casualties per day on the Germans, for a tradeoff value of 7.7.
When the German offensive began, they had a slight degree of local air superiority. This was soon reversed by German and Soviet shifts of air elements, and during most of the offensive, the Soviets had a slender margin of air superiority. In terms of technology, the Germans probably had a slight overall advantage. However, the Soviets had more tanks and, furthermore, their T-34 was superior to any tank the Germans had available at the time. The CEV calculations demonstrate that the Germans had a great qualitative superiority over the Russians, despite near-equality in technology, and despite Soviet air superiority. The Germans lost the battle, but only because they were overwhelmed by Soviet numbers.
German Performance, Western Europe, 1943-1945
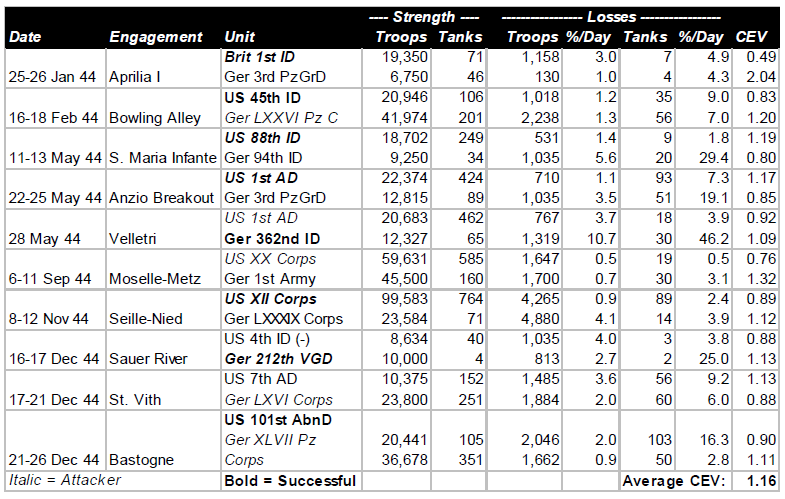
Beginning with operations between Salerno and Naples in September, 1943, through engagements in the closing days of the Battle of the Bulge in January, 1945, the pattern of German performance against the Western Allies was consistent. Some German units were better than others, and a few Allied units were as good as the best of the Germans. But on the average, German performance, as measured by CEV and casualty tradeoff, was better than the Western allies by a CEV factor averaging about 1.2, and a casualty tradeoff factor averaging about 1.5. Listed below are ten engagements from Italy and Northwest Europe during that 1944.
Technologically, German forces and those of the Western Allies were comparable. The Germans had a higher proportion of armored combat vehicles, and their best tanks were considerably better than the best American and British tanks, but the advantages were at least offset by the greater quantity of Allied armor, and greater sophistication of much of the Allied equipment. The Allies were increasingly able to achieve and maintain air superiority during this period of slightly less than two years.
The combination of vast superiority in numbers of troops and equipment, and in increasing Allied air superiority, enabled the Allies to fight their way slowly up the Italian boot, and between June and December, 1944, to drive from the Normandy beaches to the frontier of Germany. Yet the presence or absence of Allied air support made little difference in terms of either CEVs or casualty tradeoff values. Despite the defeats inflicted on them by the numerically superior Allies during the latter part of 1944, in December the Germans were able to mount a major offensive that nearly destroyed an American army corps, and threatened to drive at least a portion of the Allied armies into the sea.
Clearly, in their battles against the Soviets and the Western Allies, the Germans demonstrated that quality of combat troops was able consistently to overcome Allied technological and air superiority. It was Allied numbers, not technology, that defeated the quantitatively superior Germans.
The Six-Day War, 1967
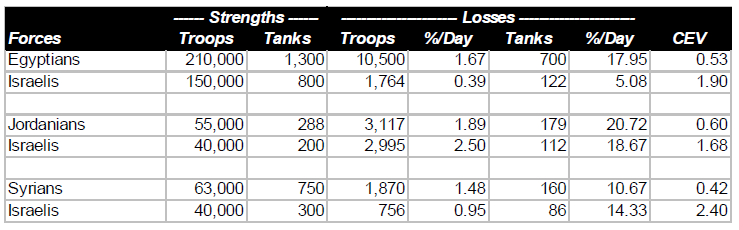
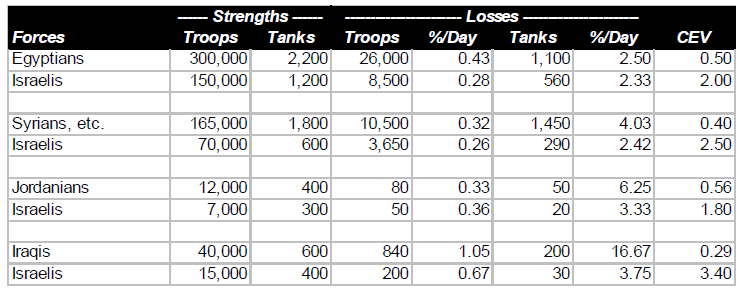
The remarkable Israeli victories over far more numerous Arab opponents—Egyptian, Jordanian, and Syrian—in June, 1967 revealed an Israeli combat superiority that had not been suspected in the United States, the Soviet Union or Western Europe. This superiority was equally awesome on the ground as in the air. (By beginning the war with a surprise attack which almost wiped out the Egyptian Air Force, the Israelis avoided a serious contest with the one Arab air force large enough, and possibly effective enough, to challenge them.) The results of the three brief campaigns are summarized in the table below:
It should be noted that some Israelis who fought against the Egyptians and Jordanians also fought against the Syrians. Thus, the overall Arab numerical superiority was greater than would be suggested by adding the above strength figures, and was approximately 328,000 to 200,000.
It should also be noted that the technological sophistication of the Israeli and Arab ground forces was comparable. The only significant technological advantage of the Israelis was their unchallenged command of the air. (In terms of battle outcomes, it was irrelevant how they had achieved air superiority.) In fact this was a very significant advantage, the full import of which would not be realized until the next Arab-Israeli war.
The results of the Six Day War do not provide an unequivocal basis for determining the relative importance of human factors and technological superiority (as evidenced in the air). Clearly a major factor in the Israeli victories was the superior performance of their ground forces due mainly to human factors. At least as important in those victories was Israeli command of the air, in which both technology and human factors both played a part.
The October War, 1973
A better basis for comparing the relative importance of human factors and technology is provided by the results of the October War of 1973 (known to Arabs as the War of Ramadan, and to Israelis as the Yom Kippur War). In this war the Israeli unquestioned superiority in the air was largely offset by the Arabs possession of highly sophisticated Soviet air defense weapons.
One important lesson of this war was a reassessment of Israeli contempt for the fighting quality of Arab ground forces (which had stemmed from the ease with which they had won their ground victories in 1967). When Arab ground troops were protected from Israeli air superiority by their air defense weapons, they fought well and bravely, demonstrating that Israeli control of the air had been even more significant in 1967 than anyone had then recognized.
It should be noted that the total Arab (and Israeli) forces are those shown in the first two comparisons, above. A Jordanian brigade and two Iraqi divisions formed relatively minor elements of the forces under Syrian command (although their presence on the ground was significant in enabling the Syrians to maintain a defensive line when the Israelis threatened a breakthrough around 20 October). For the comparison of Jordanians and Iraqis the total strength is the total of the forces in the battles (two each) on which these comparisons are based.
One other thing to note is how the Israelis, possibly unconsciously, confirmed that validity of their CEVs with respect to Egyptians and Syrians by the numerical strengths of their deployments to the two fronts. Since the war ended up in a virtual stalemate on both fronts, the overall strength figures suggest rough equivalence of combat capability.
The CEV values shown in the above table are very significant in relation to the debate about human factors and technology, There was little if anything to choose between the technological sophistication of the two sides. The Arabs had more tanks than the Israelis, but (as Israeli General Avraham Adan once told the author) there was little difference in the quality of the tanks. The Israelis again had command of the air, but this was neutralized immediately over the battlefields by the Soviet air defense equipment effectively manned by the Arabs. Thus, while technology was of the utmost importance to both sides, enabling each side to prevent the enemy from gaining a significant advantage, the true determinant of battlefield outcomes was the fighting quality of the troops, And, while the Arabs fought bravely, the Israelis fought much more effectively. Human factors made the difference.
Israeli Invasion of Lebanon, 1982
In terms of the debate about the relative importance of human factors and technology, there are two significant aspects to this small war, in which Syrians forces and PLO guerrillas were the Arab participants. In the first place, the Israelis showed that their air technology was superior to the Syrian air defense technology, As a result, they regained complete control of the skies over the battlefields. Secondly, it provides an opportunity to include a highly relevant quotation.
The statistical comparison shows the results of the two major battles fought between Syrians and Israelis:
In assessing the above statistics, a quotation from the Israeli Chief of Staff, General Rafael Eytan, is relevant.
In late 1982 a group of retired American generals visited Israel and the battlefields in Lebanon. Just before they left for home, they had a meeting with General Eytan. One of the American generals asked Eytan the following question: “Since the Syrians were equipped with Soviet weapons, and your troops were equipped with American (or American-type) weapons, isn’t the overwhelming Israeli victory an indication of the superiority of American weapons technology over Soviet weapons technology?”
Eytan’s reply was classic: “If we had had their weapons, and they had had ours, the result would have been absolutely the same.”
One need not question how the Israeli Chief of Staff assessed the relative importance of the technology and human factors.
Falkland Islands War, 1982
It is difficult to get reliable data on the Falkland Islands War of 1982. Furthermore, the author of this article had not undertaken the kind of detailed analysis of such data as is available. However, it is evident from the information that is available about that war that its results were consistent with those of the other examples examined in this article.
The total strength of Argentine forces in the Falklands at the time of the British counter-invasion was slightly more than 13,000. The British appear to have landed close to 6,400 troops, although it may have been fewer. In any event, it is evident that not more than 50% of the total forces available to both sides were actually committed to battle. The Argentine surrender came 27 days after the British landings, but there were probably no more than six days of actual combat. During these battles the British performed admirably, the Argentinians performed miserably. (Save for their Air Force, which seems to have fought with considerable gallantry and effectiveness, at the extreme limit of its range.) The British CEV in ground combat was probably between 2.5 and 4.0. The statistics were at least close to those presented below:
It is evident from published sources that the British had no technological advantage over the Argentinians; thus the one-sided results of the ground battles were due entirely to British skill (derived from training and doctrine) and determination.
South African Operations in Angola, 1987-1988
Neither the political reasons for, nor political results of, the South African military interventions in Angola in the 1970s, and again in the late 1980s, need concern us in our consideration of the relative significance of technology and of human factors. The combat results of those interventions, particularly in 1987-1988 are, however, very relevant.
The operations between elements of the South African Defense Force (SADF) and forces of the Popular Movement for the Liberation of Angola (FAPLA) took place in southeast Angola, generally in the region east of the city of Cuito-Cuanavale. Operating with the SADF units were a few small units of Jonas Savimbi’s National Union for the Total Independence of Angola (UNITA). To provide air support to the SADF and UNITA ground forces, it would have been necessary for the South Africans to establish air bases either in Botswana, Southwest Africa (Namibia), or in Angola itself. For reasons that were largely political, they decided not to do that, and thus operated under conditions of FAPLA air supremacy. This led them, despite terrain generally unsuited for armored warfare, to use a high proportion of armored vehicles (mostly light armored cars) to provide their ground troops with some protection from air attack.
Summarized below are the results of three battles east of Cuito-Cuanavale in late 1987 and early 1988. Included with FAPLA forces are a few Cubans (mostly in armored units); included with the SADF forces are a few UNITA units (all infantry).
FAPLA had complete command of air, and substantial numbers of MiG-21 and MiG-23 sorties were flown against the South Africans in all of these battles. This technological superiority was probably partly offset by greater South African EW (electronic warfare) capability. The ability of the South Africans to operate effectively despite hostile air superiority was reminiscent of that of the Germans in World War II. It was a further demonstration that, no matter how important technology may be, the fighting quality of the troops is even more important.
The tank figures include armored cars. In the first of the three battles considered, FAPLA had by far the more powerful and more numerous medium tanks (20 to 0). In the other two, SADF had a slight or significant advantage in medium tank numbers and quality. But it didn’t seem to make much difference in the outcomes.
Kuwait War, 1991
The previous seven examples permit us to examine the results of Kuwait (or Second Gulf) War with more objectivity than might otherwise have possible. First, let’s look at the statistics. Note that the comparison shown below is for four days of ground combat, February 24-28, and shows only operations of U.S. forces against the Iraqis.
There can be no question that the single most important contribution to the overwhelming victory of U.S. and other U.N. forces was the air war that preceded, and accompanied, the ground operations. But two comments are in order. The air war alone could not have forced the Iraqis to surrender. On the other hand, it is evident that, even without the air war, U.S. forces would have readily overwhelmed the Iraqis, probably in more than four days, and with more than 285 casualties. But the outcome would have been hardly less one-sided.
The Vietnam War, 1965-1973
It is impossible to make the kind of mathematical analysis for the Vietnam War as has been done in the examples considered above. The reason is that we don’t have any good data on the Vietcong—North Vietnamese forces,
However, such quantitative analysis really isn’t necessary There can be no doubt that one of the opponents was a superpower, the most technologically advanced nation on earth, while the other side was what Lyndon Johnson called a “raggedy-ass little nation,” a typical representative of “the third world.“
Furthermore, even if we were able to make the analyses, they would very possibly be misinterpreted. It can be argued (possibly with some exaggeration) that the Americans won all of the battles. The detailed engagement analyses could only confirm this fact. Yet it is unquestionable that the United States, despite airpower and all other manifestations of technological superiority, lost the war. The human factor—as represented by the quality of American political (and to a lesser extent military) leadership on the one side, and the determination of the North Vietnamese on the other side—was responsible for this defeat.
Conclusion
In a recent article in the Armed Forces Journal International Col. Philip S. Neilinger, USAF, wrote: “Military operations are extremely difficult, if not impossible, for the side that doesn’t control the sky.” From what we have seen, this is only partly true. And while there can be no question that operations will always be difficult to some extent for the side that doesn’t control the sky, the degree of difficulty depends to a great degree upon the training and determination of the troops.
What we have seen above also enables us to view with a better perspective Colonel Neilinger’s subsequent quote from British Field Marshal Montgomery: “If we lose the war in the air, we lose the war and we lose it quickly.” That statement was true for Montgomery, and for the Allied troops in World War II. But it was emphatically not true for the Germans.
The examples we have seen from relatively recent wars, therefore, enable us to establish priorities on assuring readiness for war. It is without question important for us to equip our troops with weapons and other materiel which can match, or come close to matching, the technological quality of the opposition’s materiel. We must realize that we cannot—as some people seem to think—buy good forces, by technology alone. Even more important is to assure the fighting quality of the troops. That must be, by far, our first priority in peacetime budgets and in peacetime military activities of all sorts.
NOTES
[1] This calculation is automatic in analyses of historical battles by the Tactical Numerical Deterministic Model (TNDM).
[2] The initial tank strength of the Voronezh Army Group was about 1,100 tanks. About 3,000 additional Soviet tanks joined the battle between 6 and 12 July. At the end of the battle there were about 1,800 Soviet tanks operational in the battle area; at the same time there were about 1,000 German tanks still operational.
[3] The relative combat effectiveness value of each force is calculated in comparison to 1.0. Thus the CEV of the Germans is 2.40:1.0, while that of the Soviets is 0.42: 1.0. The opposing CEVs are always the reciprocals of each other.