
[This post was originally published on June 9, 2017]
Last autumn, U.S. Army Chief of Staff General Mark Milley asserted that “we are on the cusp of a fundamental change in the character of warfare, and specifically ground warfare. It will be highly lethal, very highly lethal, unlike anything our Army has experienced, at least since World War II.” He made these comments while describing the Army’s evolving Multi-Domain Battle concept for waging future combat against peer or near-peer adversaries.
How lethal will combat on future battlefields be? Forecasting the future is, of course, an undertaking fraught with uncertainties. Milley’s comments undoubtedly reflect the Army’s best guesses about the likely impact of new weapons systems of greater lethality and accuracy, as well as improved capabilities for acquiring targets. Many observers have been closely watching the use of such weapons on the battlefield in the Ukraine. The spectacular success of the Zelenopillya rocket strike in 2014 was a convincing display of the lethality of long-range precision strike capabilities.
It is possible that ground combat attrition in the future between peer or near-peer combatants may be comparable to the U.S. experience in World War II (although there were considerable differences between the experiences of the various belligerents). Combat losses could be heavier. It certainly seems likely that they would be higher than those experienced by U.S. forces in recent counterinsurgency operations.
Unfortunately, the U.S. Defense Department has demonstrated a tenuous understanding of the phenomenon of combat attrition. Despite wildly inaccurate estimates for combat losses in the 1991 Gulf War, only modest effort has been made since then to improve understanding of the relationship between combat and casualties. The U.S. Army currently does not have either an approved tool or a formal methodology for casualty estimation.
Historical Trends in Combat Attrition
Trevor Dupuy did a great deal of historical research on attrition in combat. He found several trends that had strong enough empirical backing that he deemed them to be verities. He detailed his conclusions in Understanding War: History and Theory of Combat (1987) and Attrition: Forecasting Battle Casualties and Equipment Losses in Modern War (1995).
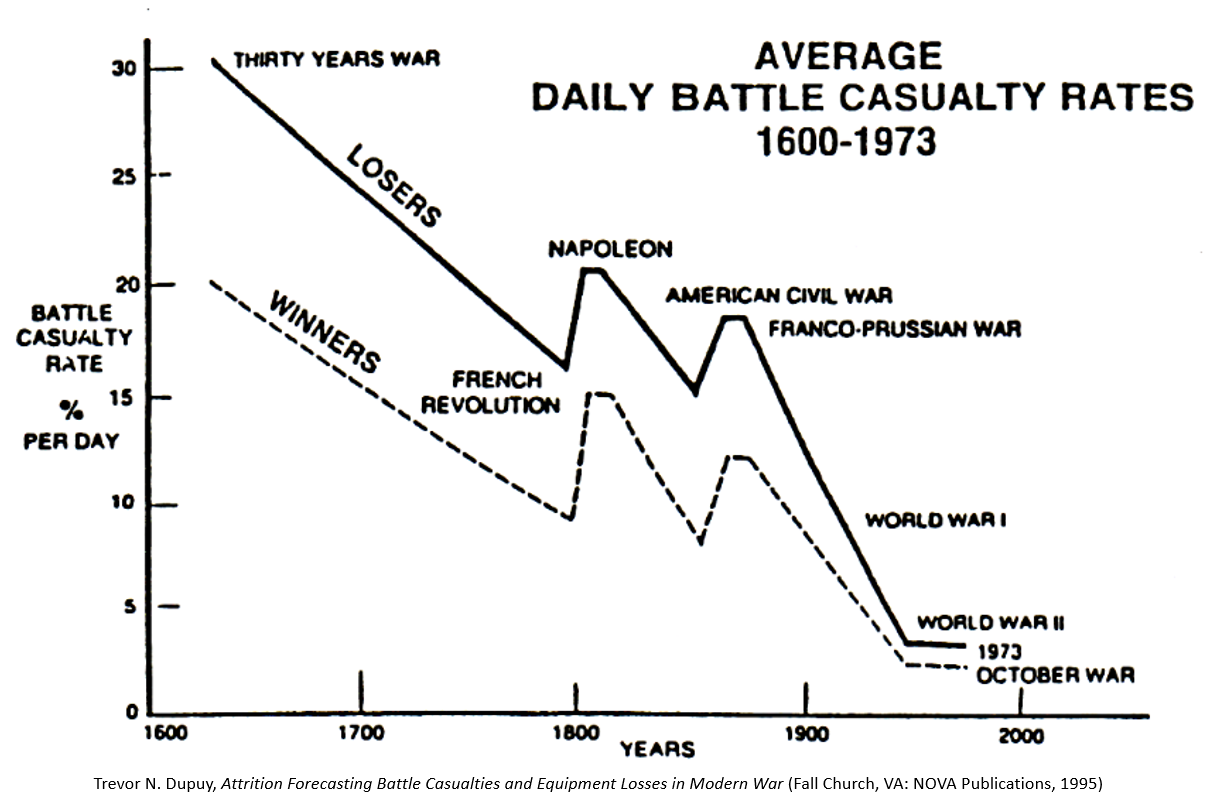
Dupuy documented a clear relationship over time between increasing weapon lethality, greater battlefield dispersion, and declining casualty rates in conventional combat. Even as weapons became more lethal, greater dispersal in frontage and depth among ground forces led daily personnel loss rates in battle to decrease.
 The average daily battle casualty rate in combat has been declining since 1600 as a consequence. Since battlefield weapons continue to increase in lethality and troops continue to disperse in response, it seems logical to presume the trend in loss rates continues to decline, although this may not necessarily be the case. There were two instances in the 19th century where daily battle casualty rates increased—during the Napoleonic Wars and the American Civil War—before declining again. Dupuy noted that combat casualty rates in the 1973 Arab-Israeli War remained roughly the same as those in World War II (1939-45), almost thirty years earlier. Further research is needed to determine if average daily personnel loss rates have indeed continued to decrease into the 21st century.
The average daily battle casualty rate in combat has been declining since 1600 as a consequence. Since battlefield weapons continue to increase in lethality and troops continue to disperse in response, it seems logical to presume the trend in loss rates continues to decline, although this may not necessarily be the case. There were two instances in the 19th century where daily battle casualty rates increased—during the Napoleonic Wars and the American Civil War—before declining again. Dupuy noted that combat casualty rates in the 1973 Arab-Israeli War remained roughly the same as those in World War II (1939-45), almost thirty years earlier. Further research is needed to determine if average daily personnel loss rates have indeed continued to decrease into the 21st century.
 Dupuy also discovered that, as with battle outcomes, casualty rates are influenced by the circumstantial variables of combat. Posture, weather, terrain, season, time of day, surprise, fatigue, level of fortification, and “all out” efforts affect loss rates. (The combat loss rates of armored vehicles, artillery, and other other weapons systems are directly related to personnel loss rates, and are affected by many of the same factors.) Consequently, yet counterintuitively, he could find no direct relationship between numerical force ratios and combat casualty rates. Combat power ratios which take into account the circumstances of combat do affect casualty rates; forces with greater combat power inflict higher rates of casualties than less powerful forces do.
Dupuy also discovered that, as with battle outcomes, casualty rates are influenced by the circumstantial variables of combat. Posture, weather, terrain, season, time of day, surprise, fatigue, level of fortification, and “all out” efforts affect loss rates. (The combat loss rates of armored vehicles, artillery, and other other weapons systems are directly related to personnel loss rates, and are affected by many of the same factors.) Consequently, yet counterintuitively, he could find no direct relationship between numerical force ratios and combat casualty rates. Combat power ratios which take into account the circumstances of combat do affect casualty rates; forces with greater combat power inflict higher rates of casualties than less powerful forces do.
Winning forces suffer lower rates of combat losses than losing forces do, whether attacking or defending. (It should be noted that there is a difference between combat loss rates and numbers of losses. Depending on the circumstances, Dupuy found that the numerical losses of the winning and losing forces may often be similar, even if the winner’s casualty rate is lower.)
Dupuy’s research confirmed the fact that the combat loss rates of smaller forces is higher than that of larger forces. This is in part due to the fact that smaller forces have a larger proportion of their troops exposed to enemy weapons; combat casualties tend to concentrated in the forward-deployed combat and combat support elements. Dupuy also surmised that Prussian military theorist Carl von Clausewitz’s concept of friction plays a role in this. The complexity of interactions between increasing numbers of troops and weapons simply diminishes the lethal effects of weapons systems on real world battlefields.
Somewhat unsurprisingly, higher quality forces (that better manage the ambient effects of friction in combat) inflict casualties at higher rates than those with less effectiveness. This can be seen clearly in the disparities in casualties between German and Soviet forces during World War II, Israeli and Arab combatants in 1973, and U.S. and coalition forces and the Iraqis in 1991 and 2003.
Combat Loss Rates on Future Battlefields
What do Dupuy’s combat attrition verities imply about casualties in future battles? As a baseline, he found that the average daily combat casualty rate in Western Europe during World War II for divisional-level engagements was 1-2% for winning forces and 2-3% for losing ones. For a divisional slice of 15,000 personnel, this meant daily combat losses of 150-450 troops, concentrated in the maneuver battalions (The ratio of wounded to killed in modern combat has been found to be consistently about 4:1. 20% are killed in action; the other 80% include mortally wounded/wounded in action, missing, and captured).
It seems reasonable to conclude that future battlefields will be less densely occupied. Brigades, battalions, and companies will be fighting in spaces formerly filled with armies, corps, and divisions. Fewer troops mean fewer overall casualties, but the daily casualty rates of individual smaller units may well exceed those of WWII divisions. Smaller forces experience significant variation in daily casualties, but Dupuy established average daily rates for them as shown below.

For example, based on Dupuy’s methodology, the average daily loss rate unmodified by combat variables for brigade combat teams would be 1.8% per day, battalions would be 8% per day, and companies 21% per day. For a brigade of 4,500, that would result in 81 battle casualties per day, a battalion of 800 would suffer 64 casualties, and a company of 120 would lose 27 troops. These rates would then be modified by the circumstances of each particular engagement.
Several factors could push daily casualty rates down. Milley envisions that U.S. units engaged in an anti-access/area denial environment will be constantly moving. A low density, highly mobile battlefield with fluid lines would be expected to reduce casualty rates for all sides. High mobility might also limit opportunities for infantry assaults and close quarters combat. The high operational tempo will be exhausting, according to Milley. This could also lower loss rates, as the casualty inflicting capabilities of combat units decline with each successive day in battle.
It is not immediately clear how cyberwarfare and information operations might influence casualty rates. One combat variable they might directly impact would be surprise. Dupuy identified surprise as one of the most potent combat power multipliers. A surprised force suffers a higher casualty rate and surprisers enjoy lower loss rates. Russian combat doctrine emphasizes using cyber and information operations to achieve it and forces with degraded situational awareness are highly susceptible to it. As Zelenopillya demonstrated, surprise attacks with modern weapons can be devastating.
Some factors could push combat loss rates up. Long-range precision weapons could expose greater numbers of troops to enemy fires, which would drive casualties up among combat support and combat service support elements. Casualty rates historically drop during night time hours, although modern night-vision technology and persistent drone reconnaissance might will likely enable continuous night and day battle, which could result in higher losses.
Drawing solid conclusions is difficult but the question of future battlefield attrition is far too important not to be studied with greater urgency. Current policy debates over whether or not the draft should be reinstated and the proper size and distribution of manpower in active and reserve components of the Army hinge on getting this right. The trend away from mass on the battlefield means that there may not be a large margin of error should future combat forces suffer higher combat casualties than expected.









 Below is an aggregated list of links to Dr.
Below is an aggregated list of links to Dr.