[The article below is reprinted from April 1997 edition of The International TNDM Newsletter.]
The First Test of the TNDM Battalion-Level Validations: Predicting the Winners
by Christopher A. Lawrence
CASE STUDIES: WHERE AND WHY THE MODEL FAILED CORRECT PREDICTIONS
Modern (8 cases):
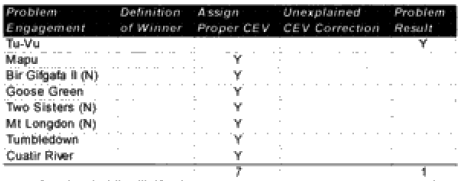
Tu-Vu—On the first run, the model predicted a defender win. Historically, the attackers (Viet Minh) won with a 2.8 km advance. When the CEV for the Viet Minh was put in (1.2), the defender still won. The real problem in this case is the horrendous casualties taken by both sides, with the defending Moroccans losing 250 out of 420 people and the attacker losing 1,200 out of 7,000 people. The model predicted only 140 and 208 respectively. This appears to address a fundamental weakness in the model, which is that if one side is willing to attack (or defend) at all costs, the model cannot predict the extreme losses. This happens in some battles with non-first world armies, with the Japanese in WWII, and apparently sometimes with the WWI predictions. In effect, the model needs some mechanism to predict fanaticism that would increase the intensity and casualties of the battle for both sides. In this case, the increased casualties certainly would have resulted in an attacker advance after over half of the defenders were casualties.
Mapu—On the first run the model predicted an attacker (Indonesian) win. Historically, the defender (British) won. When the British are given a hefty CEV of 2.6 (as one would expect that they would have), the defender wins, although the casualties are way off for the attacker. This appears to be a case in which the side that would be expected to have the higher CEV needed that CEV input into the combat run.
Bir Gifgafa II (Night)—On the first run the model predicted a defender (Egyptian) win. Historically the attacker (Israel) won with an advance of three kilometers. When the Israelis are given a hefty CEV of 3.5 (as historically they have tended to have), they win, although their casualties and distance advanced are way off. These errors are probably due to the short duration (one hour) of the model run. This appears to be a case where the side that would be expected to have the higher CEV needed that CEV input into the combat run in order to replicate historical results.
Goose Green—On the first run the model predicted a draw. Historically, the attacker (British) won. The first run also included the “cheat” of counting the Milans as regular weapons versus anti-tank. When the British are given a hefty CEV of 2.4 (as one could reasonably expect that they would have) they win, although their advance rate is too slow. Casualty prediction is quite good. This appears to be a case where the side that would be expected to have the higher CEV needed that CEV input into the combat run.
Two Sisters (Night)—On the first run the model predicted a draw. Historically the attacker (British) won yet again. When the British are given a CEV of 1.7 (as one would expect that they would have) the attacker wins, although the advance rate is too slow and the casualties a little low. This appears to be a case where the side that would be expected to have the higher CEV needed that CEV input into the combat run.
Mt. Longdon (Night)—0n the first run the model predicted a defender win. Historically, the attacker (British) won as usual. When the British are given a CEV of 2.3 (as one would expect that they should have) the attacker wins, although as usual the advance rate is too slow and the casualties a little low. This appears to be a case where the side that would be expected to have the higher CEV needed that CEV input into the combat run.
Tumbledown—On the first run the model predicted a defender win. Historically the attacker (British) won as usual. When the British were given a CEV of 1.9 (as one would expect that they should have), the attacker wins, although as usual, the advance rate is too slow and the casualties a little low. This appears to be a case where the side that would be expected to have the higher CEV needed that CEV input into the combat run.
Cuatir River—On the first run the model predicted a draw. Historically, the attacker (The Republic of South Africa) won. When the South African forces were given a CEV of 2.3 (as one would expect that they should have) the attacker wins, with advance rates and casualties being reasonably close. This appears to be a case where the side that would be expected to have the higher CEV needed that CEV input into the combat run.
Next: Predicting casualties.