There are a few comments from Dr. Paul Davis (RAND) starting on page 13 that are worth quoting:
I was struck through the workshop by a schism among attendees. One group believes, intuitively and viscerally, that human gaming–although quite powerful–is just a subset of modeling general. The other group believes, just as intuitively and viscerally, that human gaming is very different….
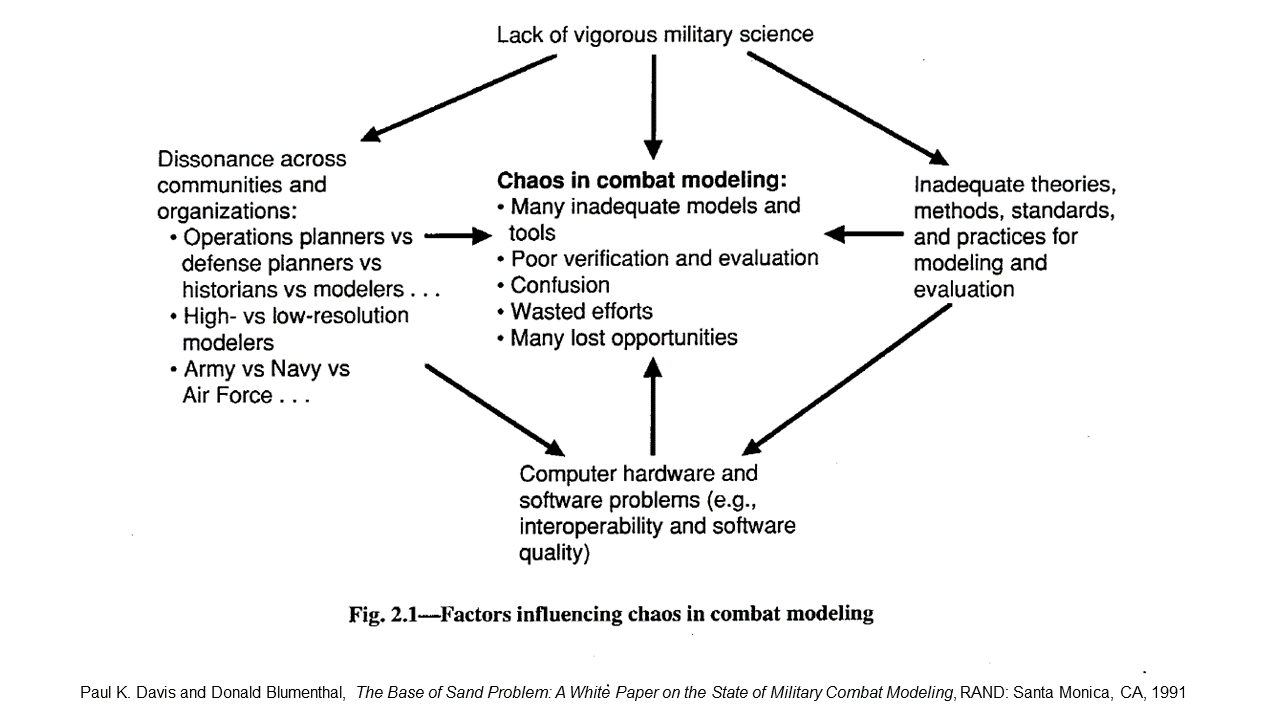
The impression had deep roots. Writings in the 1950s about defense modeling and systems analysis emphasized being scientific, rigorous, quantitative, and tied to mathematics. This was to be an antidote for hand-waving subjective assertions. That desire translated into an emphasis on “closed” models with no human interactions, which allowed reproducibility. Most DoD-level models have often been at theater or campaign level (e.g., IDAGAM, TACWAR, JICM, Thunder, and Storm). Many represent combat as akin to huge armies grinding each other down, as in the European theaters of World Wars I and II. such models are quite large, requiring considerable expertise and experience to understand.
Another development was standardized scenarios and date set with the term “data” referring to everything from facts to highly uncertain assumptions about scenario, commander decisions, and battle outcomes. Standardization allowed common baselines, which assured that policymakers would receive reports with common assumptions rather than diverse hidden assumptions chosen to favor advocates’ programs. The baselines also promoted joint thinking and assured a level playing field for joint analysis. Such reasons were prominent in DoD’s Analytic Agenda (later called Support for Strategic Analysis). Not surprisingly, however, the tendency was often to be disdainful of such other forms of modeling as the history-base formula models of Trevor Dupuy and the commercial board games of Jim Dunnigan and Mark Herman. These alternative approaches seen as somehow “lesser,” because they were allegedly less rigorous and scientific. Uncertainty analysis has been seriously inadequate. I have demurred on these matters for many years, as in the “Base of Sand” paper in 1993 and more recent monographs available on the RAND website….
The quantitative/qualitative split is a bugaboo. Many “soft” phenomena can be characterized with meaningful, albeit imprecise, numbers.
Hopefully this is my last post on the subject (but I suspect not, as I expect a public response from the three TRADOC authors). This is in response to the article in the December 2018 issue of the Phalanxby Alt, Morey and Larimer (see Part 1, Part 2, Part 3, Part 4, Part 5, Part 6). The issue here is the “Base of Sand” problem, which is what the original blog post that “inspired” their article was about:
While the first paragraph of their article addressed this blog post and they reference Paul Davis’ 1992 Base of Sand paper in their footnotes (but not John Stockfish’s paper, which is an equally valid criticism), they then do not discuss the “Base of Sand” problem further. They do not actually state whether this is a problem or not a problem. I gather by this notable omission that in fact they do understand that it is a problem, but being employees of TRADOC they are limited as to what they can publicly say. I am not.
I do address the “Base of Sand” problem in my book War by Numbers, Chapter 18. It has also been addressed in a few other posts on this blog. We are critics because we do not see significant improvement in the industry. In some cases, we are seeing regression.
In the end, I think the best solution for the DOD modeling and simulation community is not to “circle the wagons” and defend what they are currently doing, but instead acknowledge the limitations and problems they have and undertake a corrective action program. This corrective action program would involve: 1) Properly addressing how to measure and quantify certain aspects of combat (for example: Breakpoints) and 2) Validating these aspects and the combat models these aspects are part of by using real-world combat data. This would be an iterative process, as you develop and then test the model, then further develop it, and then test it again. This moves us forward. It is a more valued approach than just “circling the wagons.” As these models and simulations are being used to analyze processes that may or may not make us fight better, and may or may not save American service members lives, then I think it is important enough to do right. That is what we need to be focused on, not squabbling over a blog post (or seven).
SMEs….is a truly odd sounding acronym that means Subject Matter Experts. They talk about it extensively in their article, and this I have no problem with. I do want to make three points related to that:
A SME is not a substitution for validation.
In some respects, the QJM (Quantified Judgment Model) is a quantified and validated SME.
How do you know that the SME is right?
If you can substitute a SME for a proper validation effort, then perhaps you could just substitute the SME for the model. This would save time and money. If your SME is knowledgable enough to sprinkle holy water on the model and bless its results, why not just skip the model and ask the SME. We could certainly simplify and speed up analysis by removing the models and just asking our favorite SME. The weaknesses of this approach are obvious.
Then there is Trevor N. Dupuy’s Quantified Judgment Model (QJM) and Quantified Judgment Method of Analysis (QJMA). This is, in some respects, a SME quantified. Actually it was a board of SMEs, who working with a series of historical studies (the list of studies starts here: http://www.dupuyinstitute.org/tdipubs.htm ). These SMEs developed a set of values for different situations, and then insert them into a model. They then validated the model to historical data (also known as real-world combat data). While the QJM has come under considerable criticism from elements of the Operations Research community…..if you are using SMEs, then in fact, you are using something akin, but less rigorous, than Trevor Dupuy’s Quantified Judgment Method of Analysis.
This last point, how do we know that the SME is right, is significant. How do you test your SMEs to ensure that what they are saying is correct? Another SME, a board of SMEs? Maybe a BOGSAT? Can you validate SMEs? There are limits to SME’s. In the end, you need a validated model.
The authors of the Phalanx article then make the snarky statement that:
Combat simulations have been successfully used to replicate historical battles as a demonstration, but this is not a requirement or their primary intended use.
So, they say in three sentences that combat models using human factors are difficult to validate, they then say that physics-based models are validated, and then they say that running a battle through a model is a demonstration. Really?
Does such a demonstration show that the model works or does not work? Does such a demonstration show that they can get a reasonable outcome when using real-world data? The definition of validation that they gave on the first page of their article is:
The process of determining the degree to which a model or simulation with its associated data is an accurate representation of the real world from the perspective of its intended use is referred to as validation.
This is a perfectly good definition of validation. So where does one get that real-world data? If you are using the model to measure combat effects (as opposed to physical affects) then you probably need to validate it to real-world combat data. This means historical combat data, whether it is from 3,400 years ago or 1 second ago. You need to assemble the data from a (preferably recent) combat situation and run it through the model.
This has been done. The Dupuy Institute does not exist in a vacuum. We have assembled four sets of combat data bases for use in validation. They are:
The Ardennes Campaign Simulation Data Base
The Kursk Data Base
The Battle of Britain Data Base
Our various division-level, battalion-level and company-level engagement database bases.
Now, the reason we have mostly used World War II data is that you can get detailed data from the unit records of both sides. To date….this is not possible for almost any war since 1945. But, if your high-tech model cannot predict lower-tech combat….then you probably also have a problem modeling high-tech combat. So, it is certainly a good starting point.
More to the point, this was work that was funded in part by the Center for Army Analysis, the Deputy Secretary of the Army (Operations Research) and Office of Secretary of Defense, Planning, Analysis and Evaluation. Hundreds of thousands of dollars were spent developing some of these databases. This was not done just for “demonstration.” This was not done as a hobby. If their sentence was meant to be-little the work of TDI, which is how I do interpret that sentence, then is also belittles the work of CAA, DUSA(OR) and OSD PA&E. I am not sure that is the three author’s intent.
The next sentence in the article is interesting. After saying that validating models incorporating human behavior is difficult (and therefore should not be done?) they then say:
In combat simulations, those model components that lend themselves to empirical validation, such as the physics-based aspects of combat, are developed, validated, and verified using data from an accredited source.
This is good. But, the problem lies that it limits one to only validating models that do not include humans. If one is comparing a weapon system to a weapon system, as they discuss later, this is fine. On the other hand, if one is comparing units in combat to units in combat…then there are invariably humans involved. Even if you are comparing weapon systems versus weapon systems in an operational environment, there are humans involved. Therefore, you have to address human factors. Once you have gone beyond simple weapon versus weapon comparisons, you need to use models that are gaming situations that involved humans. I gather from the previous sentence (see part 3 of 7) and this sentence, that means that they are using un-validated models. Their extended discussions of SMEs (Subject Matter Experts) that follows just reinforces that impression.
But, TRADOC is the training and doctrine command. They are clearly modeling something other than just the “physics-based aspect of combat.”
On the first page (page 28) in the third column they make the statement that:
Models of complex systems, especially those that incorporate human behavior, such as that demonstrated in combat, do not often lend themselves to empirical validation of output measures, such as attrition.
Really? Why can’t you? If fact, isn’t that exactly the model you should be validating?
More to the point, people have validated attrition models. Let me list a few cases (this list is not exhaustive):
1. Done by Center for Army Analysis (CAA) for the CEM (Concepts Evaluation Model) using Ardennes Campaign Simulation Study (ARCAS) data. Take a look at this study done for Stochastic CEM (STOCEM): https://apps.dtic.mil/dtic/tr/fulltext/u2/a489349.pdf
2. Done in 2005 by The Dupuy Institute for six different casualty estimation methodologies as part of Casualty Estimation Methodologies Studies. This was work done for the Army Medical Department and funded by DUSA (OR). It is listed here as report CE-1: http://www.dupuyinstitute.org/tdipub3.htm
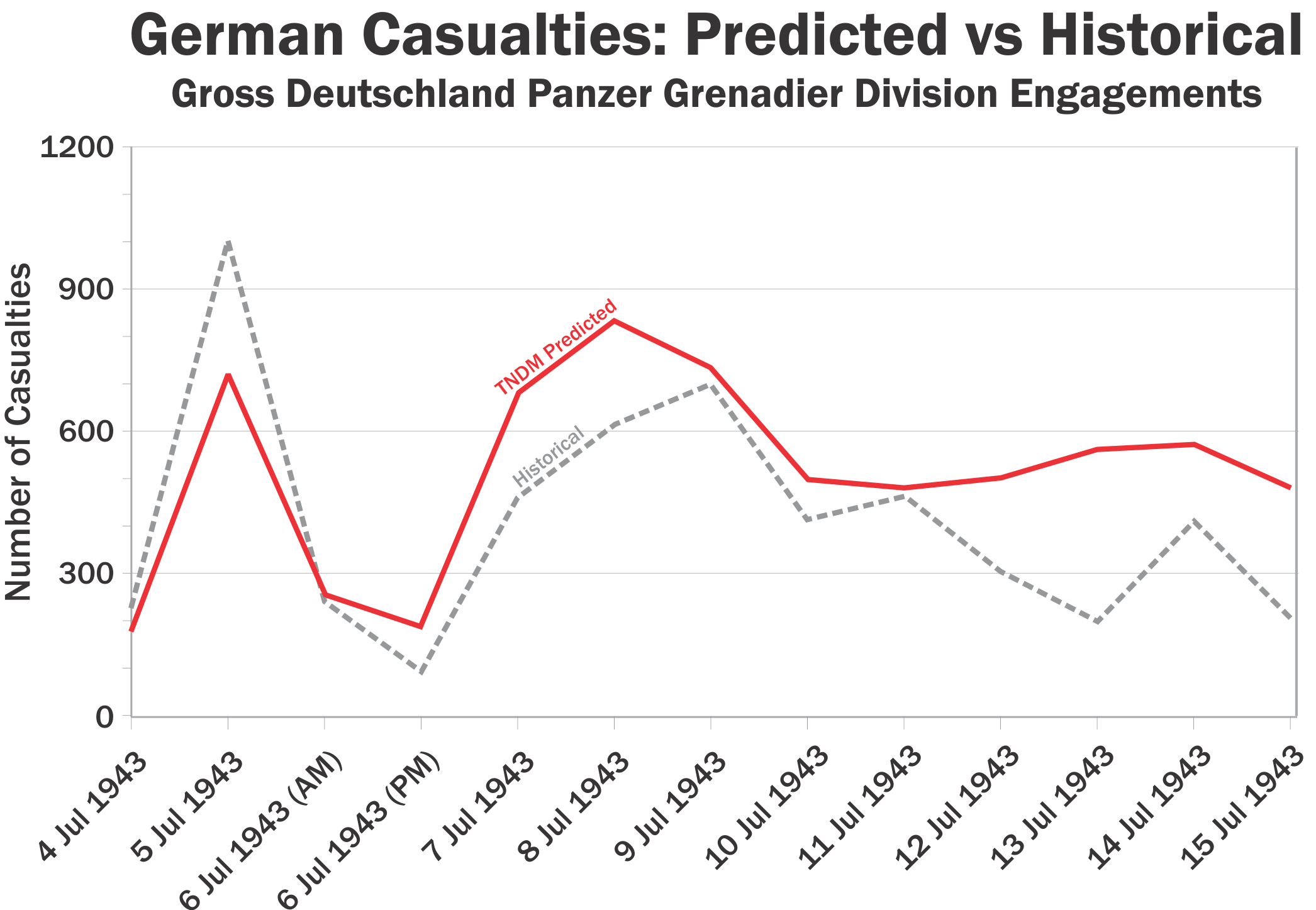
3. Done in 2006 by The Dupuy Institute for the TNDM (Tactical Numerical Deterministic Model) using Corps and Division-level data. This effort was funded by Boeing, not the U.S. government. This is discussed in depth in Chapter 19 of my book War by Numbers (pages 299-324) where we show 20 charts from such an effort. Let me show you one from page 315:
So, this is something that multiple people have done on multiple occasions. It is not so difficult that The Dupuy Institute was not able to do it. TRADOC is an organization with around 38,000 military and civilian employees, plus who knows how many contractors. I think this is something they could also do if they had the desire.
On the first page (page 28) top of the third column they make the rather declarative statement that:
The combat simulations used by military operations research and analysis agencies adhere to strict standards established by the DoD regarding verification, validation and accreditation (Department of Defense, 2009).
Now, I have not reviewed what has been done on verification, validation and accreditation since 2009, but I did do a few fairly exhaustive reviews before then. One such review is written up in depth in The International TNDM Newsletter. It is Volume 1, No. 4 (February 1997). You can find it here:
The newsletter includes a letter dated 21 January 1997 from the Scientific Advisor to the CG (Commanding General) at TRADOC (Training and Doctrine Command). This is the same organization that the three gentlemen who wrote the article in the Phalanx work for. The Scientific Advisor sent a letter out to multiple commands to try to flag the issue of validation (letter is on page 6 of the newsletter). My understanding is that he received few responses (I saw only one, it was from Leavenworth). After that, I gather there was no further action taken. This was a while back, so maybe everything has changed, as I gather they are claiming with that declarative statement. I doubt it.
This issue to me is validation. Verification is often done. Actual validations are a lot rarer. In 1997, this was my list of combat models in the industry that had been validated (the list is on page 7 of the newsletter):
1. Atlas (using 1940 Campaign in the West)
2. Vector (using undocumented turning runs)
3. QJM (by HERO using WWII and Middle-East data)
4. CEM (by CAA using Ardennes Data Base)
5. SIMNET/JANUS (by IDA using 73 Easting data)
Now, in 2005 we did a report on Casualty Estimation Methodologies (it is report CE-1 list here: http://www.dupuyinstitute.org/tdipub3.htm). We reviewed the listing of validation efforts, and from 1997 to 2005…nothing new had been done (except for a battalion-level validation we had done for the TNDM). So am I now to believe that since 2009, they have actively and aggressively pursued validation? Especially as most of this time was in a period of severely declining budgets, I doubt it. One of the arguments against validation made in meetings I attended in 1987 was that they did not have the time or budget to spend on validating. The budget during the Cold War was luxurious by today’s standards.
If there have been meaningful validations done, I would love to see the validation reports. The proof is in the pudding…..send me the validation reports that will resolve all doubts.
The Military Operations Research Society (MORS) publishes a periodical journal called the Phalanx. In the December 2018 issue was an article that referenced one of our blog posts. This took us by surprise. We only found out about thanks to one of the viewers of this blog. We are not members of MORS. The article is paywalled and cannot be easily accessed if you are not a member.
It is titled “Perspectives on Combat Modeling” (page 28) and is written by Jonathan K. Alt, U.S. Army TRADOC Analysis Center, Monterey, CA.; Christopher Morey, PhD, Training and Doctrine Command Analysis Center, Ft. Leavenworth, Kansas; and Larry Larimer, Training and Doctrine Command Analysis Center, White Sands, New Mexico. I am not familiar with any of these three gentlemen.
The blog post that appears to be generating this article is this one:
Simply by coincidence, Shawn Woodford recently re-posted this in January. It was originally published on 10 April 2017 and was written by Shawn.
The opening two sentences of the article in the Phalanx reads:
Periodically, within the Department of Defense (DoD) analytic community, questions will arise regarding the validity of the combat models and simulations used to support analysis. Many attempts (sic) to resurrect the argument that models, simulations, and wargames “are built on the thin foundation of empirical knowledge about the phenomenon of combat.” (Woodford, 2017).
It is nice to be acknowledged, although it this case, it appears that we are being acknowledged because they disagree with what we are saying.
Probably the word that gets my attention is “resurrect.” It is an interesting word, that implies that this is an old argument that has somehow or the other been put to bed. Granted it is an old argument. On the other hand, it has not been put to bed. If a problem has been identified and not corrected, then it is still a problem. Age has nothing to do with it.
On the other hand, maybe they are using the word “resurrect” because recent developments in modeling and validation have changed the environment significantly enough that these arguments no longer apply. If so, I would be interested in what those changes are. The last time I checked, the modeling and simulation industry was using many of the same models they had used for decades. In some cases, were going back to using simpler hex-games for their modeling and wargaming efforts. We have blogged a couple of times about these efforts. So, in the world of modeling, unless there have been earthshaking and universal changes made in the last five years that have completely revamped the landscape….then the decades old problems still apply to the decades old models and simulations.
More to come (this is the first of at least 7 posts on this subject).
Source: David A. Shlapak and Michael Johnson. Reinforcing Deterrence on NATO’s Eastern Flank: Wargaming the Defense of the Baltics. Santa Monica, CA: RAND Corporation, 2016.
[UPDATE] We had several readers recommend games they have used or would be suitable for simulating Multi-Domain Battle and Operations (MDB/MDO) concepts. These include several classic campaign-level board wargames:
Chris Lawrence recently looked at C-WAM and found that it uses a lot of traditional board wargaming elements, including methodologies for determining combat results, casualties, and breakpoints that have been found unable to replicate real-world outcomes (aka “The Base of Sand” problem).
What other wargames, models, and simulations are there being used out there? Are there any commercial wargames incorporating MDB/MDO elements into their gameplay? What methodologies are being used to portray MDB/MDO effects?
A great deal of importance has been placed on the knowledge derived from these activities. As the U.S. Army Training and Doctrine Command recently stated,
Concept analysis informed by joint and multinational learning events…will yield the capabilities required of multi-domain battle. Resulting doctrine, organization, training, materiel, leadership, personnel and facilities solutions will increase the capacity and capability of the future force while incorporating new formations and organizations.
There is, however, a problem afflicting the Defense Department’s wargames, of which the military operations research and models and simulations communities have long been aware, but have been slow to address: their models are built on a thin foundation of empirical knowledge about the phenomenon of combat. None have proven the ability to replicate real-world battle experience. This is known as the “base of sand” problem.
A Brief History of The Base of Sand
All combat models and simulations are abstracted theories of how combat works. Combat modeling in the United States began in the early 1950s as an extension of military operations research that began during World War II. Early model designers did not have large base of empirical combat data from which to derive their models. Although a start had been made during World War II and the Korean War to collect real-world battlefield data from observation and military unit records, an effort that provided useful initial insights, no systematic effort has ever been made to identify and assemble such information. In the absence of extensive empirical combat data, model designers turned instead to concepts of combat drawn from official military doctrine (usually of uncertain provenance), subject matter expertise, historians and theorists, the physical sciences, or their own best guesses.
As the U.S. government’s interest in scientific management methods blossomed in the late 1950s and 1960s, the Defense Department’s support for operations research and use of combat modeling in planning and analysis grew as well. By the early 1970s, it became evident that basic research on combat had not kept pace. A survey of existing combat models by Gary Shubik and Martin Brewer for RAND in 1972 concluded that
Basic research and knowledge is lacking. The majority of the MSGs [models, simulations and games] sampled are living off a very slender intellectual investment in fundamental knowledge…. [T]he need for basic research is so critical that if no other funding were available we would favor a plan to reduce by a significant proportion all current expenditures for MSGs and to use the saving for basic research.
The [Defense Department]is becoming critically dependent on combat models (including simulations and war games)—even more dependent than in the past. There is considerable activity to improve model interoperability and capabilities for distributed war gaming. In contrast to this interest in model-related technology, there has been far too little interest in the substance of the models and the validity of the lessons learned from using them. In our view, the DoD does not appreciate that in many cases the models are built on a base of sand…
[T]he DoD’s approach in developing and using combat models, including simulations and war games, is fatally flawed—so flawed that it cannot be corrected with anything less than structural changes in management and concept. [Original emphasis]
As a remedy, the authors recommended that the Defense Department create an office to stimulate a national military science program. This Office of Military Science would promote and sponsor basic research on war and warfare while still relying on the military services and other agencies for most research and analysis.
Davis and Blumenthal initially drafted their white paper before the 1991 Gulf War, but the performance of the Defense Department’s models and simulations in that conflict underscored the very problems they described. Defense Department wargames during initial planning for the conflict reportedly predicted tens of thousands of U.S. combat casualties. These simulations were said to have led to major changes in U.S. Central Command’s operational plan. When the casualty estimates leaked, they caused great public consternation and inevitable Congressional hearings.
The Defense Department’s current generation of models and simulations harbor the same weaknesses as the ones in use in the 1990s. Some are new iterations of old models with updated graphics and code, but using the same theoretical assumptions about combat. In most cases, no one other than the designers knows exactly what data and concepts the models are based upon. This practice is known in the technology world as black boxing. While black boxing may be an essential business practice in the competitive world of government consulting, it makes independently evaluating the validity of combat models and simulations nearly impossible. This should be of major concern because many models and simulations in use today contain known flaws.
Others, such as the Joint Conflict And Tactical Simulation (JCATS), MAGTF Tactical Warfare System (MTWS), and Warfighters’ Simulation (WARSIM) adjudicate ground combat using probability of hit/probability of kill (pH/pK) algorithms. Corps Battle Simulation (CBS) uses pH/pK for direct fire attrition and a modified version of Lanchester for indirect fire. While these probabilities are developed from real-world weapon system proving ground data, their application in the models is combined with inputs from subjective sources, such as outputs from other combat models, which are likely not based on real-world data. Multiplying an empirically-derived figure by a judgement-based coefficient results in a judgement-based estimate, which might be accurate or it might not. No one really knows.
This state of affairs seems remarkable given the enormous stakes that are being placed on the output of the Defense Department’s modeling and simulation activities. After decades of neglect, remedying this would require a dedicated commitment to sustained basic research on the military science of combat and warfare, with no promise of a tangible short-term return on investment. Yet, as Biddle pointed out, “With so much at stake, we surely must do better.”
[NOTE: The attrition methodologies used in CBS and WARSIM have been corrected since this post was originally published per comments provided by their developers.]