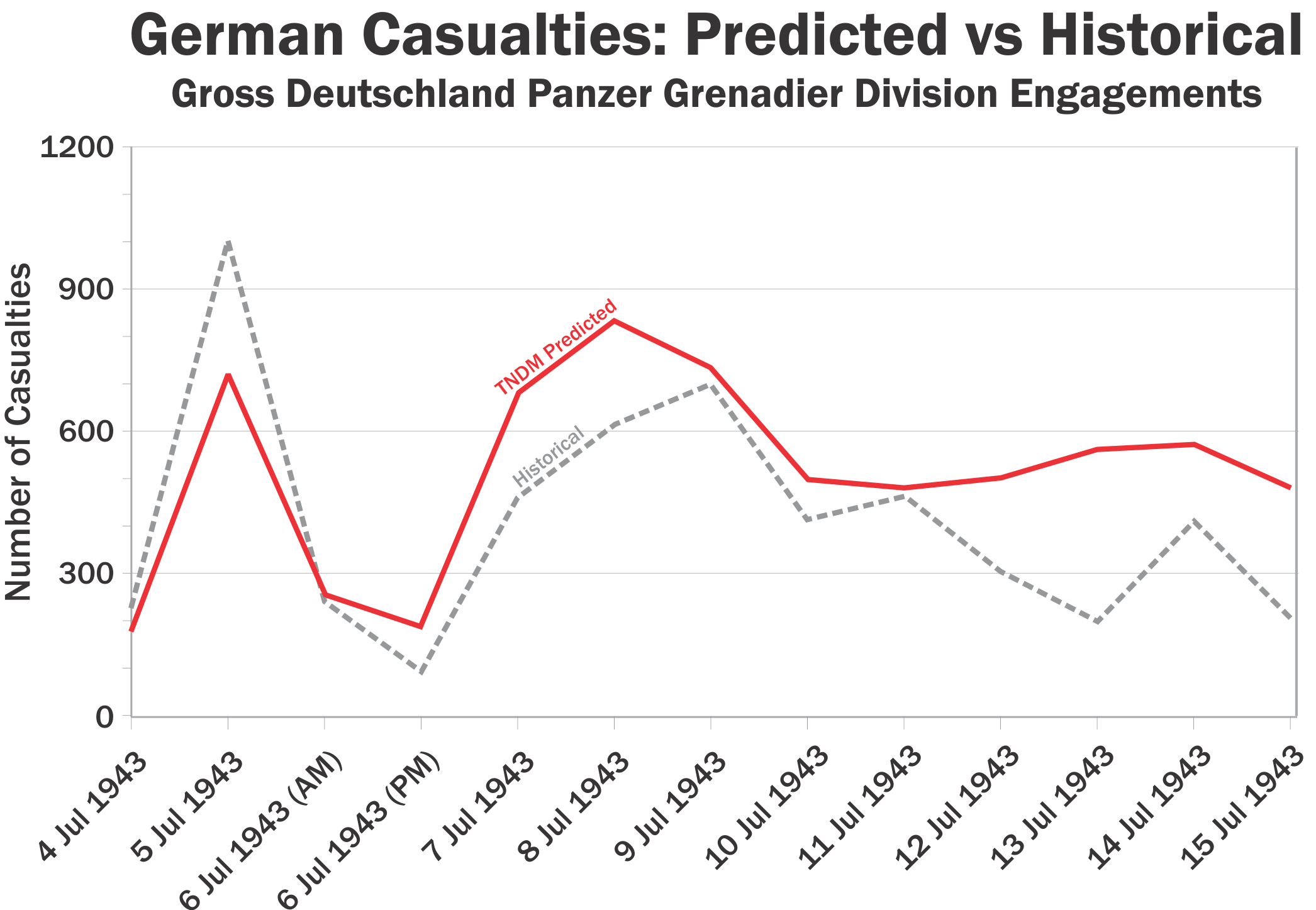
The phrase “face validation” shows up in our blog post earlier this week on Combat Adjudication. It is a phrase I have heard many times over the decades, sometimes by very established Operation Researchers (OR). So what does it mean?
Well, it is discussed in the Department of the Army Pamphlet 5-11: Verification, Validation and Accreditation of Army Models and Simulations: Pamphlet 5-11
Their first mention of it is on page 34: “SMEs [Subject Matter Experts] or other recognized individuals in the field of inquiry. The process by which experts compare M&S [Modeling and Simulation] structure and M&S output to their estimation of the real world is called face validation, peer review, or independent review.”
On page 35 they go on to state: “RDA [Research, Development, and Acquisition]….The validation method typically chosen for this category of M&S is face validation.”
And on page 36 under Technical Methods: “Face validation. This is the process of determining whether an M&S, on the surface, seems reasonable to personnel who are knowledgeable about the system or phenomena under study. This method applies the knowledge and understanding of experts in the field and is subject to their biases. It can produce a consensus of the community if the number of breadth of experience of the experts represent the key commands and agencies. Face validation is a point of departure to determine courses of action for more comprehensive validation efforts.” [I put the last part in bold]
Page 36: “Functional decomposition (sometimes known as piecewise validation)….When used in conjunction with face validation of the overall M&S results, functional decomposition is extremely useful in reconfirming previous validation of a recently modified portions of the M&S.”
I have not done a survey of all army, air force, navy, marine, coast guard or Department of Defense (DOD) regulations. This one is enough.
So, “face validation” is asking one or more knowledgeable (or more senior) people if the model looks good. I guess it really depends on whose the expert is and to what depth they look into it. I have never seen a “face validation” report (validation reports are also pretty rare).
Who’s “faces” do they use? Are they outside independent people or people inside the organization (or the model designer himself)? I am kind of an expert, yet, I have never been asked. I do happen to be one of the more experienced model validation people out there, having managed or directly created six+ validation databases and having conducted five validation-like exercises. When you consider that most people have not done one, should I be a “face” they contact? Or is this process often just to “sprinkle holy water” on the model and be done?
In the end, I gather for practical purposes the process of face validation is that if a group of people think it is good, then it is good. In my opinion, “face validation” is often just an argument that allows people to explain away or simply dismiss the need for any rigorous analysis of the model. The pamphlet does note that “Face validation is a point of departure to determine courses of action for more comprehensive validation efforts.” How often have we’ve seen the subsequent comprehensive validation effort? Very, very rarely. It appears that “face validation” is the end point.
…
Is this really part of the scientific method?
…