Another William “Chip” Sayers article. He has done over a dozen postings to this blog. Some of his previous postings include:
Wargaming 101: A Tale of Two Forces | Mystics & Statistics (dupuyinstitute.org)
A story about planning for Desert Storm (1991) | Mystics & Statistics (dupuyinstitute.org)
Wargaming 101: The Bad Use of a Good Tool
In the mid to late 1980s, an office tasked with analysis and support concerning our NATO allies used Col. Dupuy’s Quantified Judgement Model (the predecessor of the TNDM) in analyzing the probable performance of NATO forces in the event of a conventional war in Europe. Why their counterpart for Soviet/Warsaw Pact countries, did not buy the QJM nor, apparently, participate in this analysis is unknown. The NATO office set out to do a series of analytical papers on the various NATO corps areas, presumably producing a study for each. Only two studies were published, one for each of two of the Corps that were considered NATO’s weakest.
To understand how this project was conceived and designed, one needs to be familiar with NATO’s basic force structure for the Cold War. NATO’s Central Region was divided into eight national corps “slices.” The British, Dutch and Belgians each contributed one corps while the US provided two (plus a third that could rapidly deploy manpower from CONUS to fall in on prepositioned equipment) and the Germans three. Stacked together, they made up what was commonly referred to as the “layer cake” by those who saw fundamental weakness in this scheme.
By assigning each nation a front-line area to defend, all of NATO would be involved from the outset, with no room for political maneuver — less resolute nations would be locked in from the start of the conflict. However, this meant that certain corps sectors were defended by suspect armies, creating opportunities for Soviet forces to breakthrough NATO’s main line of resistance and romp through their vulnerable and lucrative rear areas. NATO partially compensated by narrowing some of the weaker corps’ sectors and assigning more frontage to the stronger corps. Nevertheless, many believed this scheme of defense was more about politics and less about warfighting.
From North to South, NATO’s Northern Army Group (NORTHAG) consisted of I Netherlands (NE) Corps, I German (GE) Corps, I British (UK) Corps and I Belgian (BE) Corps. Immediately South of NORTHAG was NATO’s Central Army Group (CENTAG), made up of III GE Corps, US Seventh Army (V US Corps and VII US Corps) and II GE Corps.
The first thing one might notice about this arrangement of national corps sectors is that they vaguely look like cylinders of an in-line engine and would take little imagination to envision the Warsaw Pact forces as pistons attempting to push through those cylinders. In fact, a lot of 1980s Pentagon-type wargaming was done based on this idea. Of course, there are a couple of problems inherent to this concept. First, the Soviets knew there would be boundaries between the NATO corps, and that those boundaries would be natural weak points in the defensive scheme. How does one replicate that in a piston-based model? Second, it does not allow for maneuver, particularly across corps boundaries, but also within the “cylinder.” One rather expensive system by a beltway bandit contractor attempted to compensate in their piston-based model by using some mathematical modification, but this never proved convincing. Piston-based models were imminently tempting, but they were a trap that should never have been used. The first time I encountered one, I commented to a friend that I had better wargames in my closet at home, and they cost a whole lot less: $40, vice $1,000,000. I could have saved the Pentagon a lot of money on that one.

Unfortunately, the analysts in question fell for the piston trap. With apparently little or no input from their Soviet counterparts, they chose a relatively weak Soviet Combined Arms Army to act as an attacker, lined them up in the cylinder and sent them off in what was conceptually a simple frontal attack.
Feeding this rather simplistic scenario into the QJM gave results that were satisfying, but would have been suspect to analysts familiar with Soviet Army doctrine. In essence, the study’s analysts “found” that a weak NATO corps could successfully hold off a Soviet CAA and, by implication, a strong corps might be able to defeat or even successfully counterattack its Soviet assailant. A recent QJM run of this scenario resulted in an advance rate of only 2.7km per day — approximately 10% of Soviet planning norms. The second study had similar results, reinforcing their views. Both studies were beautifully done with color graphics and lavish detail. I was green with envy. My agency should have done one of these studies for each NATO corps, and they should have been done with much more understanding of how both sides would fight. It was a huge missed opportunity.
Unfortunately, these beautiful studies were foundationally flawed and would have misled had they gained traction. I don’t know why they failed to do that, whether it was patently obvious to Soviet analysts that the studies were wrong, whether no one believed in the QJM, or whether they were a tree falling in a forest with no one to hear. Most likely, they simply hit the street too late to be of interest, because the Warsaw Pact was crumbling and taking the Soviet threat to Europe off the board.
The studies’ analysts made several fundamental errors in setting up their scenarios. First and foremost, they misjudged the threat they were working against. They posited that the weakest corps in NATO would face off against a weak Combined Arms Army with no reinforcement. Nothing could have been further from the truth. The Soviets knew NATO’s strengths and weaknesses — in some cases, apparently better than NATO itself — and had no intention of pitting weakness against weakness. Take a look at the following illustration, typical of the time and with at least a fair understanding of how the Soviets planned to go to war:

Note the thrust through Göttingen. Clearly, this is the main effort for the entire Western TVD (Theater of Military Operations). Rather than attack with a weak CAA, the Soviets would likely have thrown the full weight of their operation at the Schwerpunkt of the weak NATO corps. Not only would the strongest Soviet CAA made the attack, it would have had the assistance of second echelon artillery brigades whose parent armies were yet committed, their organic air support, and the lion’s share of Front supporting assets, as well — a very formidable force, indeed.
A second major mistake the studies’ analysts made was assuming that the Soviet thrust would have respected NATO corps boundaries. Take another look at the illustration, above. The main thrust is clearly divided between two armies. It was typical of Soviet battle planning that two adjacent armies would plan their breakthroughs to be side-by-side to take advantage of the potential for sharing supporting assets, to double the size of the breakthrough, and to add to the enemy’s confusion and dislocation by presenting a perplexing attack exploiting seams between defending corps. These two mistakes are why I surmise that Soviet analysts didn’t participate in the study. Surely, they would have corrected these errors.
These were problems with the scenario, but the modeling they did was fatally flawed in itself. If one is examining an operation at a particular level, one must use sub elements of that level to do a proper exploration. To simply feed the model two sides and press “start” is to believe in magic — that the model is able to sort out how the units would interact. By simply dumping the two sides into the model and pressing “start,” they were modeling a simple frontal attack circa 1915. To get legitimate results, the analysts must contribute more than this.
The QJM was scaled to division/day operations, which means it works best if the maneuver elements are divisions. It works well with brigades/regiments and even down to the battalion and company levels. If the analysts wanted to explore the operations of a corps, they should, at a minimum, have laid out a division-level defense. Better yet, they should have taken it down to the brigade-level to account for nuance. Certainly, the model would have had no problem doing so and the results obtained would have been far more believable. Yet they did their simulation at the corps level, with no maneuver attempted. It’s no wonder they got such desultory results. Unfortunately, the analysts didn’t understand this.
So, how should the QJM have been used to better shed light on the reality of the situation? Clearly, the studies’ analysts needed a better order of battle for the Soviet side. Soviet analysts should have provided that for them, and it assuredly would have been more formidable than what they came up on their own. Further, they needed Soviet experts to set up a better attack for them. It should have included a mix of low-combat power attacks designed to fix enemy forces in place over wide frontages, and high-combat power attacks over a limited frontage to achieve the actual penetration of enemy defenses. Finally, they should have set up a detailed defense. Generically, it would have looked something like this:
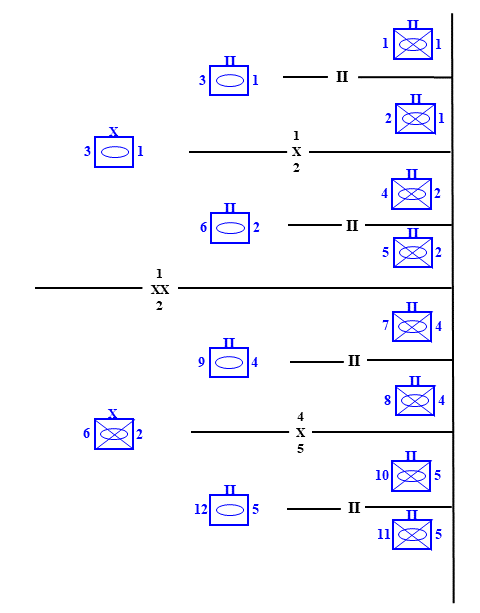
A generic NATO corps of two mechanized divisions and a mechanized brigade in a “2 up, 1 back” defensive posture.
In terms of raw combat power, the CAA with no reinforcement had a 2:1 advantage of the defending corps. Modifying the defenders for posture and terrain and other operational factors drove this down to a 1.6:1 advantage.
Our NATO corps defended approximately 40km of frontage divided between two mechanized divisions. One brigade of the northernmost division defended relatively open ground and was the target of the Soviet breakthrough attack. The second brigade of that division and the entire southern division occupied defensive positions on rougher ground and would therefore be subject to economy of force fixing attacks. The two divisions together had eight front-line battalions in the main line of resistance, each on a defensive frontage of 5km — a fairly comfortable force-to-space ratio. Unfortunately for NATO, the Soviet’s breakthrough frontage norms could be compressed to as little as 4km for a division with two regiments leading. In this case, that could mean a single defending battalion would receive the full weight of an entire attacking division, plus its attached fire support means. This might be one thing with a modern, well-equipped, well-trained, and well-supported corps. However, the NATO corps in question was none of these things.
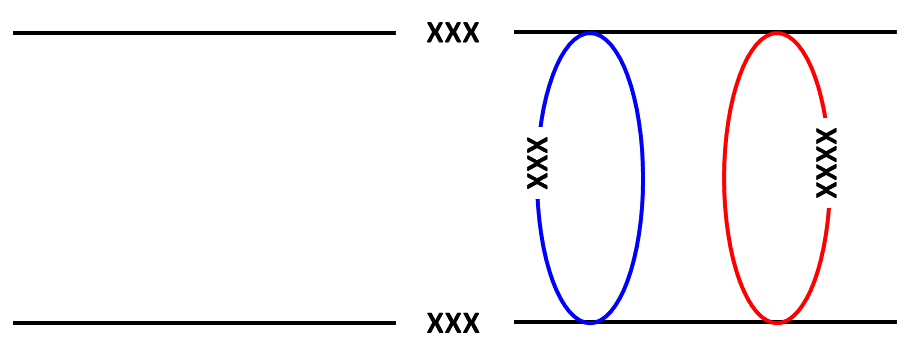
The Soviet Army immediately to the north of our CAA had a more challenging enemy to overcome, so it chose to make its breakthrough attack through the northernmost battalion sector of our weak NATO corps. By aligning these two attacks on their common border, the Soviets ended up with a breakthrough zone of 10km and were able to share resources and targets.
A strictly numerical accounting of the breakthrough would show two defending companies of APC-mounted infantry at the line of contact with a third in depth, behind them. This array would be hit with a short but supremely violent “hurricane” barrage of over 400 artillery tubes and rocket launchers. This would be achieved by using the division’s organic assets (144 systems), plus the assets of an unengaged second-echelon division (144 systems), plus the CAA’s organic artillery brigade (72 systems — an unengaged a second-echelon army’s artillery brigade could provide support to another attacking division), plus assets from the CAA’s MRL regiment (54 systems).
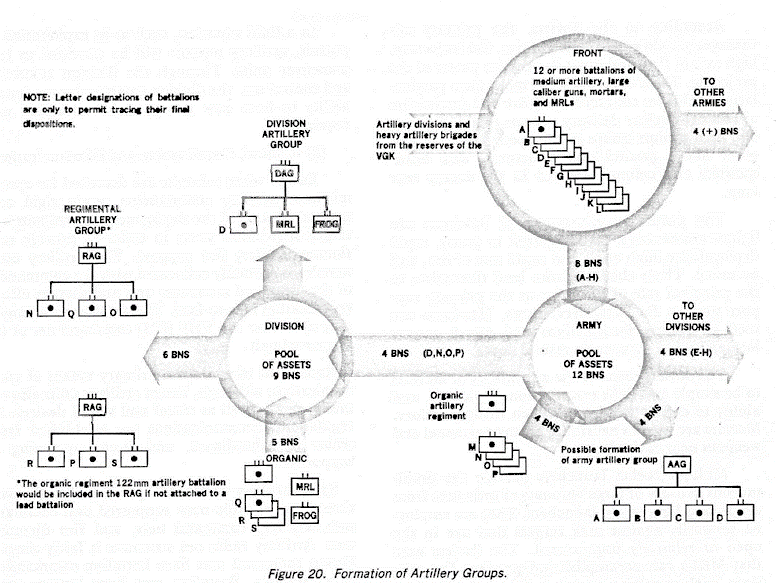
From the unclassified DIA report, DDB-1130-8-82 Soviet Front Fire Support 15Dec81.
400 tubes firing at an average rate of five rounds a minute for 20 minutes would equate to roughly 40,000 rounds at a rate of 34 rounds per second on the positions of a single defending battalion. According to Soviet fire support norms, this is sufficient to completely suppress 12 company positions — 25% in excess of requirements for this attack. And this is without counting Army and Frontal Aviation airstrikes that would be allocated to any breakthrough attempt.
What are the practical effects of such a fire-strike? According to Soviet norms, ‘’A suppressed target has suffered damage sufficient to cause it to temporarily lose its combat effectiveness, or to be restricted in its ability to maneuver or effect command and control. Expressed mathematically, an area target is considered to be “suppressed” when it is highly probable (90 percent) that no less than 25 to 30 percent of the sub-elements of the target or 25 to 30 percent of the target’s area has suffered serious damage.” Put simply, the targeted battalion can be expected to lose a quarter of its combat power before the leading tank and motorized-rifle units engage. Further, many units will reach their breakpoint after 25% losses in such a short period of time, particularly those with lower levels of readiness and morale. Graphically, this can be illustrated in the following manner:
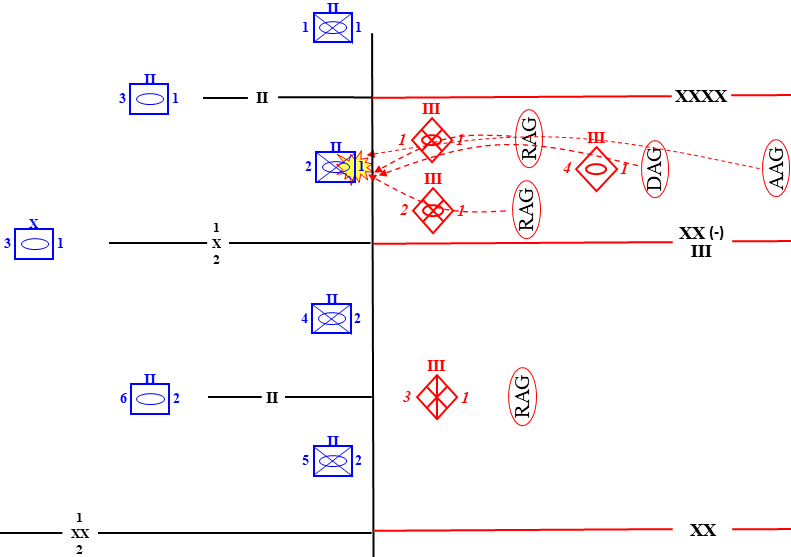
The CAA’s Chief of Rocket Troops and Artillery (CRTA) devises a 20-minute suppressive fire-strike in the breakthrough sector of the targeted NATO corps. Meanwhile, the adjacent CAA is preparing its breakthrough attack in a similar manner.

Before NATO forces can commit reinforcements, the adjacent CAAs have blown a hole 10km wide in the NATO defenses, with little hope of checking the momentum of the deluge..
The breakthrough attack in the 2nd battalion/1st Mech sector is made at more than a 7:1 superiority yielding an advance rate of 24km per day, 16% casualties and a loss of 3/4s of the defenders combat power, effectively eliminating the battalion from the NATO order of battle. In the fixing attack immediately to the south, the slightly reinforced MRR is unable to make any ground, but neither would the NATO mechanized brigade, should it attempt a counterattack. Essentially, these two forces are locked together in stalemate, which is all that the Soviets needed for this attack to achieve its goals. The Soviet’s second MRD would have similar results against the NATO second mechanized division to the south.
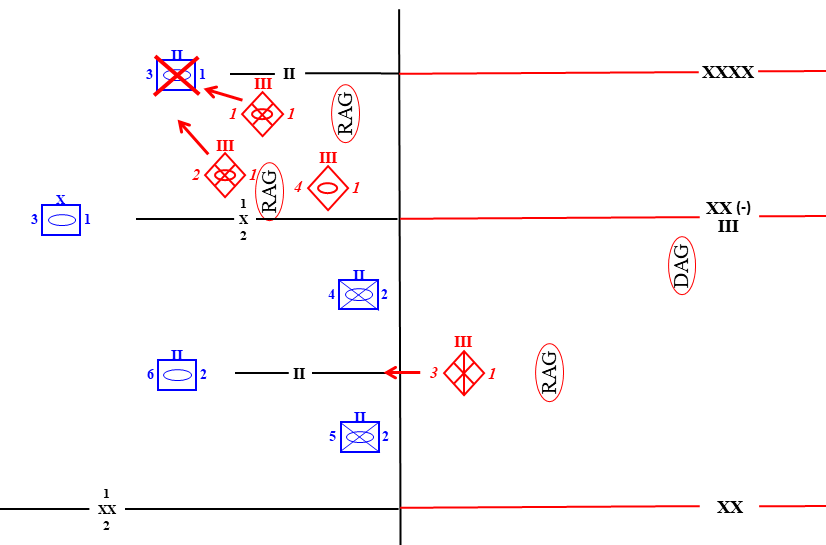
The defending armored battalion is hit by four regiments (the two from the adjacent CAA not shown) and quickly overrun.
It is easy to see that the 1st Brigade’s 3rd Armored Battalion would be quickly overrun by the four-regiment freight train barreling down the line at it, but could the 1st Mech Division’s 3rd Armored Brigade — the Soviet Division’s subsequent objective — do better? With the Division’s 2nd echelon Tank Regiment committed, the attacker achieves a 2.3:1 superiority, which yields a 6.7km per day rate of advance and inflicts a 38% loss in combat power on the defender. That’s not a satisfactory rate of advance, but it is quite sufficient to keep the defending brigade from interfering with the commitment of the CAA’s second echelon, a tank division, for which the NATO corps has no answer.

While the 1st MRD pushes the NATO Corps’ armored brigade out of the way, the CAA’s second echelon tank division is committed into NORTHAG’s rear.
The European analysts predicted that there would be no penetration of the NATO corps’ defensive line. However, it took very little imagination to pass an entire tank division through while destroying a significant amount of the defender’s combat power. The QJM supported both outcomes, but it is not difficult to see that the details matter. The QJM/TNDM models are very good, but they are only as good as the user input. Flawed input may come from poor intelligence (in contemporary analysis) or from incomplete or inaccurate historical data (in the case of historical analysis). As we saw in this case, it can also come from a poor understanding of how one or both sides will fight.