
The Second Test of the TNDM Battalion-Level Validations: Predicting Casualties
by Christopher A. Lawrence
SO WHERE WERE WE REALLY OFF? (WWII)
In the ease of the WWII results, we were getting results in the ball park in less than 60% of the cases for the attacker and in less than 50% of the eases in the case of the defenders. We were often significantly too low. Knowing that we were dealing with a number of Japanese engagements (seven), and they clearly fought in a manner that was different from most western European nations, we expected that they would be under-predicting, and some casualty adjustment would be necessary to reflect this.
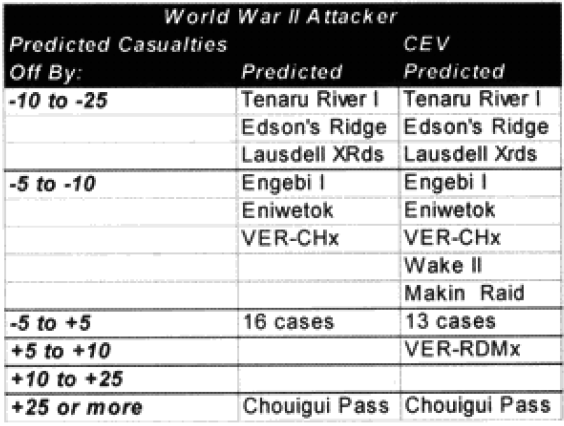
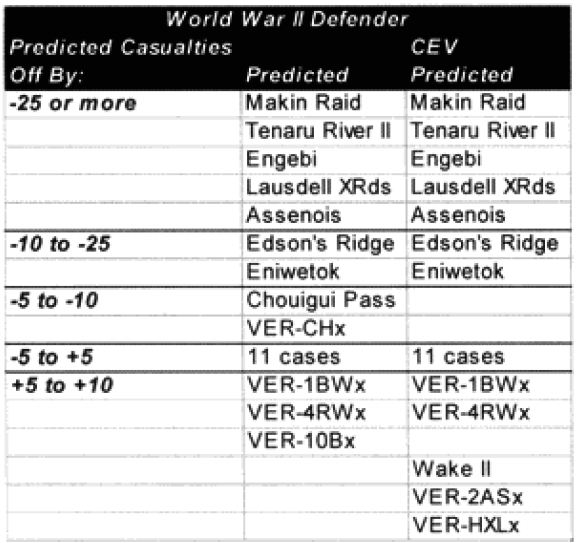 We also examined whether time was an issue (it was not). The under-predicted battles are listed in the next table
We also examined whether time was an issue (it was not). The under-predicted battles are listed in the next table
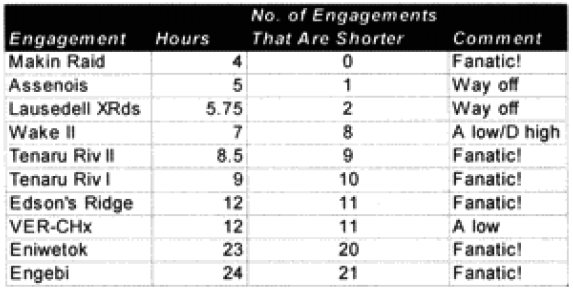 We temporarily defined the Japanese mode of fighting as “fanaticism.” We decided to find a factor for fanaticism by looking at all the battles with the Japanese. They are listed below:
We temporarily defined the Japanese mode of fighting as “fanaticism.” We decided to find a factor for fanaticism by looking at all the battles with the Japanese. They are listed below:
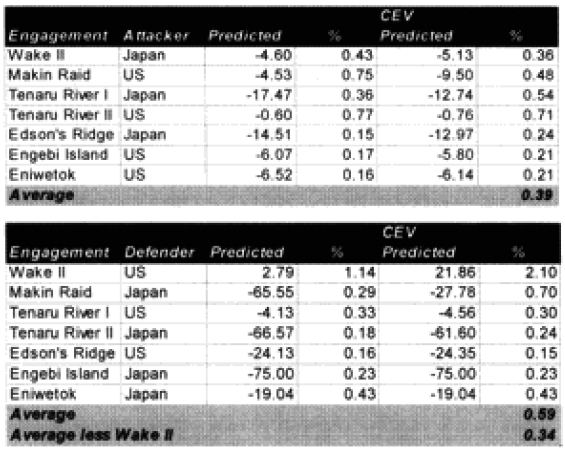 Looking at what multiplier was needed, one notes that .39 times 2.5 = .975 while .34 times 2.5 = .85. This argues for a “fanatic” multiplier of 2.5. The non-fanatic opponent attrition multiplier is also 2.5. There was no indication that both sides should not be affected by the same multiplier.
Looking at what multiplier was needed, one notes that .39 times 2.5 = .975 while .34 times 2.5 = .85. This argues for a “fanatic” multiplier of 2.5. The non-fanatic opponent attrition multiplier is also 2.5. There was no indication that both sides should not be affected by the same multiplier.
We had now tentatively identified two “fixes” to the data. l am sure someone will call them “fudges,“ but I am comfortable enough with the logic behind them (especially the fanaticism) that I would dismiss such criticism. It was now time to look at the modern data, and see what would happen if these fixes were applied to it.
SO WHERE WERE WE REALLY OFF? (Post-WWII)
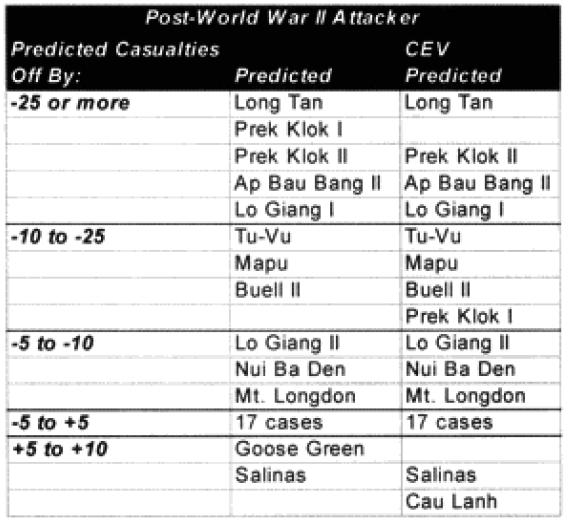
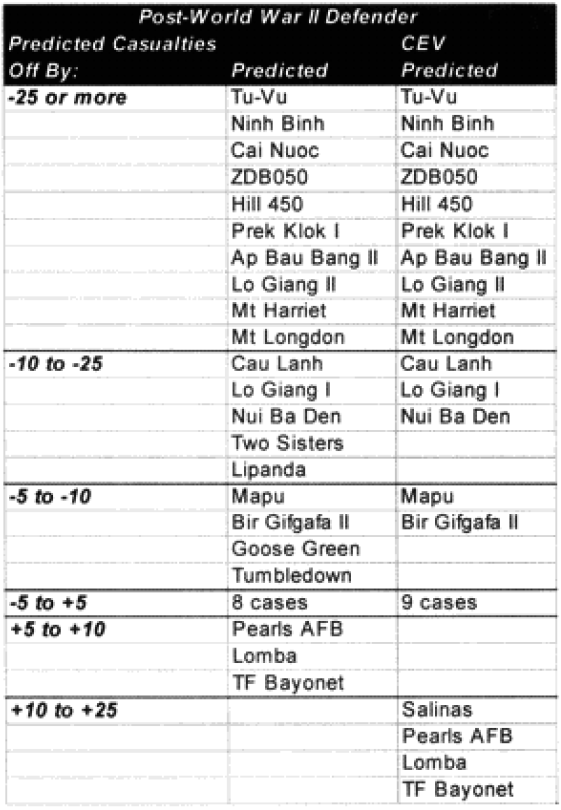 A total of 20 battles were noticeably under-predicted. We examined them to see if there was a pattern in this under-prediction.
A total of 20 battles were noticeably under-predicted. We examined them to see if there was a pattern in this under-prediction.
Next: “Casualty insensitive” systems
