[The article below is reprinted from April 1997 edition of The International TNDM Newsletter.]
The First Test of the TNDM Battalion-Level Validations: Predicting the Winners
by Christopher A. Lawrence
Part II
CONCLUSIONS:
WWI (12 cases):
For the WWI battles, the nature of the prediction problems are summarized as:
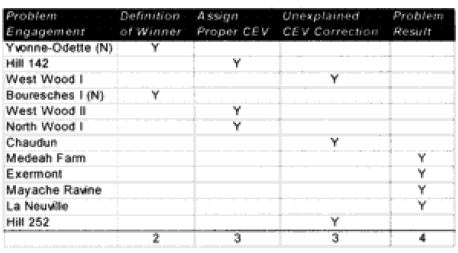 CONCLUSION: In the case of the WWI runs, five of the problem engagements were due to confusion of defining a winner or a clear CEV existing for a side that should have been predictable. Seven out of the 23 runs have some problems, with three problems resolving themselves by assigning a CEV value to a side that may not have deserved it. One (Medeah Farm) was just off any way you look at it, and three suffered a problems because historically the defenders (Germans) suffered surprisingly low losses. Two had the battle outcome predicted correctly on the first run, and then had the outcome incorrectly predicted after a CEV was assigned.
CONCLUSION: In the case of the WWI runs, five of the problem engagements were due to confusion of defining a winner or a clear CEV existing for a side that should have been predictable. Seven out of the 23 runs have some problems, with three problems resolving themselves by assigning a CEV value to a side that may not have deserved it. One (Medeah Farm) was just off any way you look at it, and three suffered a problems because historically the defenders (Germans) suffered surprisingly low losses. Two had the battle outcome predicted correctly on the first run, and then had the outcome incorrectly predicted after a CEV was assigned.
With 5 to 7 clear failures (depending on how you count them), this leads one to conclude that the TNDM can be relied upon to predict the winner in a WWI battalion-level battle in about 70% of the cases.
WWII (8 cases):
For the WWII battles, the nature of the prediction problems are summarized as:
 CONCLUSION: In the case of the WWII runs, three of the problem engagements were due to confusion of defining a winner or a clear CEV existing for a side that should have been predictable. Four out of the 23 runs suffered a problem because historically the defenders (Germans) suffered surprisingly low losses and one case just simply assigned a possible unjustifiable CEV. This led to the battle outcome being predicted correctly on the first run, then incorrectly predicted after CEV was assigned.
CONCLUSION: In the case of the WWII runs, three of the problem engagements were due to confusion of defining a winner or a clear CEV existing for a side that should have been predictable. Four out of the 23 runs suffered a problem because historically the defenders (Germans) suffered surprisingly low losses and one case just simply assigned a possible unjustifiable CEV. This led to the battle outcome being predicted correctly on the first run, then incorrectly predicted after CEV was assigned.
With 3 to 5 clear failures, one can conclude that the TNDM can be relied upon to predict the winner in a WWII battalion-level battle in about 80% of the cases.
Modern (8 cases):
For the post-WWll battles, the nature of the prediction problems are summarized as:
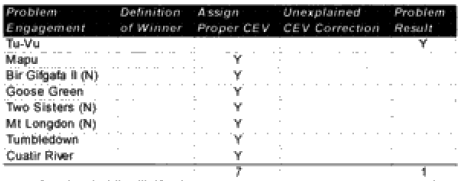 CONCLUSION: ln the case of the modem runs, only one result was a problem. In the other seven cases, when the force with superior training is given a reasonable CEV (usually around 2), then the correct outcome is achieved. With only one clear failure, one can conclude that the TNDM can be relied upon to predict the winner in a modern battalion-level battle in over 90% of the cases.
CONCLUSION: ln the case of the modem runs, only one result was a problem. In the other seven cases, when the force with superior training is given a reasonable CEV (usually around 2), then the correct outcome is achieved. With only one clear failure, one can conclude that the TNDM can be relied upon to predict the winner in a modern battalion-level battle in over 90% of the cases.
FINAL CONCLUSIONS: In this article, the predictive ability of the model was examined only for its ability to predict the winner/loser. We did not look at the accuracy of the casualty predictions or the accuracy of the rates of advance. That will be done in the next two articles. Nonetheless, we could not help but notice some trends.
First and foremost, while the model was expected to be a reasonably good predictor of WWII combat, it did even better for modem combat. It was noticeably weaker for WWI combat. In the case of the WWI data, all attrition figures were multiplied by 4 ahead of time because we knew that there would be a fit problem otherwise.
This would strongly imply that there were more significant changes to warfare between 1918 and 1939 than between 1939 and 1989.
Secondly, the model is a pretty good predictor of winner and loser in WWII and modern cases. Overall, the model predicted the winner in 68% of the cases on the first run and in 84% of the cases in the run incorporating CEV. While its predictive powers were not perfect, there were 13 cases where it just wasn’t getting a good result (17%). Over half of these were from WWI, only one from the modern period.
In some of these battles it was pretty obvious who was going to win. Therefore, the model needed to do a step better than 50% to be even considered. Historically, in 51 out of 76 cases (67%). the larger side in the battle was the winner. One could predict the winner/loser with a reasonable degree of success by just looking at that rule. But the percentage of the time the larger side won varied widely with the period. In WWI the larger side won 74% of the time. In WWII it was 87%. In the modern period it was a counter-intuitive 47% of the time, yet the model was best at selecting the winner in the modern period.
The model’s ability to predict WWI battles is still questionable. It obviously does a pretty good job with WWII battles and appears to be doing an excellent job in the modern period. We suspect that the difference in prediction rates between WWII and the modern period is caused by the selection of battles, not by any inherit ability of the model.
RECOMMENDED CHANGES: While it is too early to settle upon a model improvement program, just looking at the problems of winning and losing, and the ancillary data to that, leads me to three corrections:
- Adjust for times of less than 24 hours. Create a formula so that battles of six hours in length are not 1/4 the casualties of a 24-hour battle, but something greater than that (possibly the square root of time). This adjustment should affect both casualties and advance rates.
- Adjust advance rates for smaller unit: to account for the fact that smaller units move faster than larger units.
- Adjust for fanaticism to account for those armies that continue to fight after most people would have accepted the result, driving up casualties for both sides.
Next Part III: Case Studies

If the magnitudes of the values of one or more independent variables differ between WW1 observations and WW2 observations (plus post-WW2 observations) then consider the possiblity that battle data from the two wars are on different sections (with different slopes) of the true curve and that your model curve fits better with the WW2 (plus post-WW2) section of the true curve than it does with the WW1 section of the true curve.
For example, a given straight line might fit fairly well with one section of a curve while an exponential curve might fit better with a different section of the same curve:
https://files.askiitians.com/cdn1/images/2017426-11423336-7802-5-graph-of-logarithm-function.png
If you go to the webpage for the sample curve, notice that a straight line fits fairly well with the b>1 section of the curve while a more curvy curve (or even another straight line with a steeper slope) would fit better with the b<1 section of the curve.
So, different models might do better for WW1 and WW2 (plus post-WW2) or your model needs to be revised in order to reflect a curve that changes as it reaches different sections of the true curve (because of changes in the mangnitudes of values between the two wars).
“First and foremost, while the model was expected to be a reasonably good predictor of WWII combat, it did even better for modem combat. It was noticeably weaker for WWI combat. In the case of the WWI data, all attrition figures were multiplied by 4 ahead of time because we knew that there would be a fit problem otherwise.
This would strongly imply that there were more significant changes to warfare between 1918 and 1939 than between 1939 and 1989.”
As sientist I can not follow your conclusion: At the moment the issues with WWI shows either, that there were dramatic changes in the decade after WWI or that your model is wrong and the issues come to light for WWI data. Why do you exclude the second possibility?
WWII divisions and most regiments were lead by officers who had a peactime training pre-WWI, served in frontline units during WWI. And many WWII actions at the tactical level were decribed as WWI style, like Sedan in serious German literature.
Why do you expect larger changes within one decade after WWI than in three decades after WWII? That does not really makes sense for me.
I agree. They were evolved great war armies, with an improvement in the element of maneuver. Perhaps it would be wiser to split the conflict between the swift operations from 39 to the end of 41 and the attritional nature experienced post 41 (with a retrospect to the civil war and WWI), or to underline the differences between the individual fronts.