[This piece was originally posted on 10 April 2017.]
As the U.S. Army and U.S. Marine Corps work together to develop their joint Multi-Domain Battle concept, wargaming and simulation will play a significant role. Aspects of the construct have already been explored through the Army’s Unified Challenge, Joint Warfighting Assessment, and Austere Challenge exercises, and upcoming Unified Quest and U.S. Army, Pacific war games and exercises. U.S. Pacific Command and U.S. European Command also have simulations and exercises scheduled.
A great deal of importance has been placed on the knowledge derived from these activities. As the U.S. Army Training and Doctrine Command recently stated,
Concept analysis informed by joint and multinational learning events…will yield the capabilities required of multi-domain battle. Resulting doctrine, organization, training, materiel, leadership, personnel and facilities solutions will increase the capacity and capability of the future force while incorporating new formations and organizations.
There is, however, a problem afflicting the Defense Department’s wargames, of which the military operations research and models and simulations communities have long been aware, but have been slow to address: their models are built on a thin foundation of empirical knowledge about the phenomenon of combat. None have proven the ability to replicate real-world battle experience. This is known as the “base of sand” problem.
A Brief History of The Base of Sand
All combat models and simulations are abstracted theories of how combat works. Combat modeling in the United States began in the early 1950s as an extension of military operations research that began during World War II. Early model designers did not have large base of empirical combat data from which to derive their models. Although a start had been made during World War II and the Korean War to collect real-world battlefield data from observation and military unit records, an effort that provided useful initial insights, no systematic effort has ever been made to identify and assemble such information. In the absence of extensive empirical combat data, model designers turned instead to concepts of combat drawn from official military doctrine (usually of uncertain provenance), subject matter expertise, historians and theorists, the physical sciences, or their own best guesses.
As the U.S. government’s interest in scientific management methods blossomed in the late 1950s and 1960s, the Defense Department’s support for operations research and use of combat modeling in planning and analysis grew as well. By the early 1970s, it became evident that basic research on combat had not kept pace. A survey of existing combat models by Gary Shubik and Martin Brewer for RAND in 1972 concluded that
Basic research and knowledge is lacking. The majority of the MSGs [models, simulations and games] sampled are living off a very slender intellectual investment in fundamental knowledge…. [T]he need for basic research is so critical that if no other funding were available we would favor a plan to reduce by a significant proportion all current expenditures for MSGs and to use the saving for basic research.
In 1975, John Stockfish took a direct look at the use of data and combat models for managing decisions regarding conventional military forces for RAND. He emphatically stated that “[T]he need for better and more empirical work, including operational testing, is of such a magnitude that a major reallocating of talent from model building to fundamental empirical work is called for.”
In 1991, Paul K. Davis, an analyst for RAND, and Donald Blumenthal, a consultant to the Livermore National Laboratory, published an assessment of the state of Defense Department combat modeling. It began as a discussion between senior scientists and analysts from RAND, Livermore, and the NASA Jet Propulsion Laboratory, and the Defense Advanced Research Projects Agency (DARPA) sponsored an ensuing report, The Base of Sand Problem: A White Paper on the State of Military Combat Modeling.
Davis and Blumenthal contended
The [Defense Department] is becoming critically dependent on combat models (including simulations and war games)—even more dependent than in the past. There is considerable activity to improve model interoperability and capabilities for distributed war gaming. In contrast to this interest in model-related technology, there has been far too little interest in the substance of the models and the validity of the lessons learned from using them. In our view, the DoD does not appreciate that in many cases the models are built on a base of sand…
[T]he DoD’s approach in developing and using combat models, including simulations and war games, is fatally flawed—so flawed that it cannot be corrected with anything less than structural changes in management and concept. [Original emphasis]
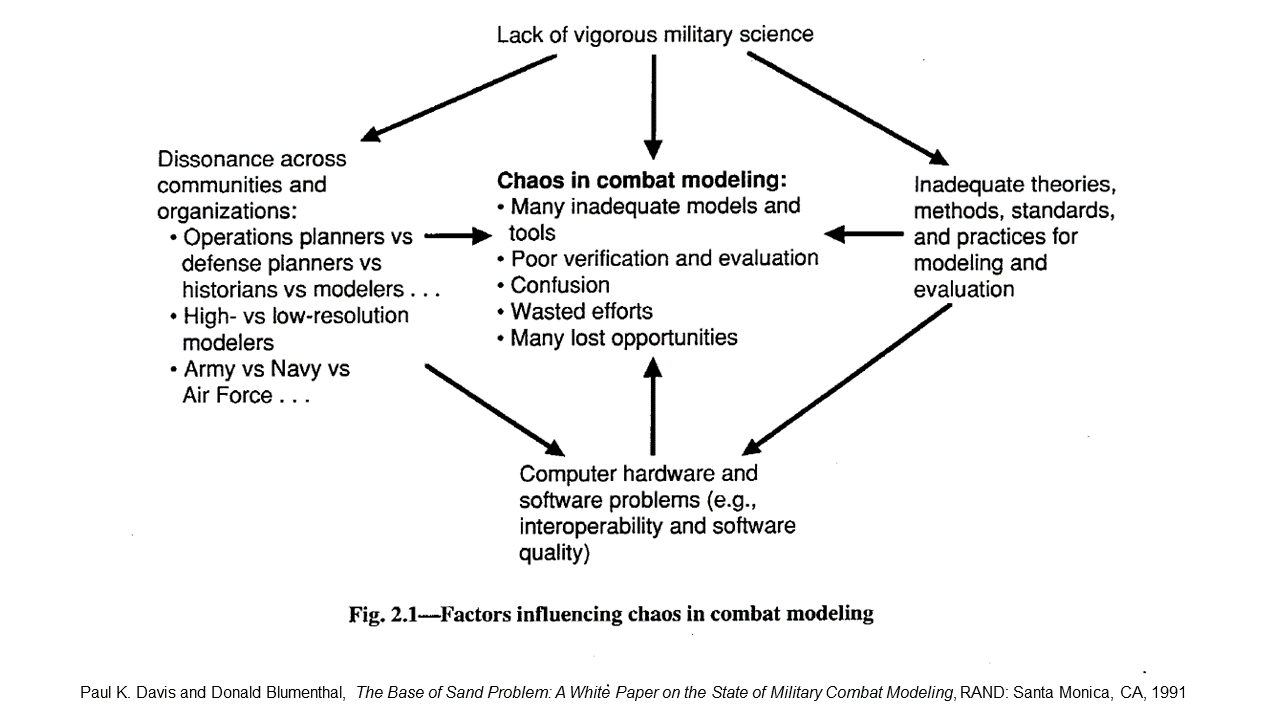 As a remedy, the authors recommended that the Defense Department create an office to stimulate a national military science program. This Office of Military Science would promote and sponsor basic research on war and warfare while still relying on the military services and other agencies for most research and analysis.
As a remedy, the authors recommended that the Defense Department create an office to stimulate a national military science program. This Office of Military Science would promote and sponsor basic research on war and warfare while still relying on the military services and other agencies for most research and analysis.
Davis and Blumenthal initially drafted their white paper before the 1991 Gulf War, but the performance of the Defense Department’s models and simulations in that conflict underscored the very problems they described. Defense Department wargames during initial planning for the conflict reportedly predicted tens of thousands of U.S. combat casualties. These simulations were said to have led to major changes in U.S. Central Command’s operational plan. When the casualty estimates leaked, they caused great public consternation and inevitable Congressional hearings.
While all pre-conflict estimates of U.S. casualties in the Gulf War turned out to be too high, the Defense Department’s predictions were the most inaccurate, by several orders of magnitude. This performance, along with Davis and Blumenthal’s scathing critique, should have called the Defense Department’s entire modeling and simulation effort into question. But it did not.
The Problem Persists
The Defense Department’s current generation of models and simulations harbor the same weaknesses as the ones in use in the 1990s. Some are new iterations of old models with updated graphics and code, but using the same theoretical assumptions about combat. In most cases, no one other than the designers knows exactly what data and concepts the models are based upon. This practice is known in the technology world as black boxing. While black boxing may be an essential business practice in the competitive world of government consulting, it makes independently evaluating the validity of combat models and simulations nearly impossible. This should be of major concern because many models and simulations in use today contain known flaws.
Some, such as Joint Theater Level Simulation (JTLS), use the Lanchester equations for calculating attrition in ground combat. However, multiple studies have shown that these equations are incapable of replicating real-world combat. British engineer Frederick W. Lanchester developed and published them in 1916 as an abstract conceptualization of aerial combat, stating himself that he did not believe they were applicable to ground combat. If Lanchester-based models cannot accurately represent historical combat, how can there be any confidence that they are realistically predicting future combat?
Others, such as the Joint Conflict And Tactical Simulation (JCATS), MAGTF Tactical Warfare System (MTWS), and Warfighters’ Simulation (WARSIM) adjudicate ground combat using probability of hit/probability of kill (pH/pK) algorithms. Corps Battle Simulation (CBS) uses pH/pK for direct fire attrition and a modified version of Lanchester for indirect fire. While these probabilities are developed from real-world weapon system proving ground data, their application in the models is combined with inputs from subjective sources, such as outputs from other combat models, which are likely not based on real-world data. Multiplying an empirically-derived figure by a judgement-based coefficient results in a judgement-based estimate, which might be accurate or it might not. No one really knows.
Potential Remedies
One way of assessing the accuracy of these models and simulations would be to test them against real-world combat data, which does exist. In theory, Defense Department models and simulations are supposed to be subjected to validation, verification, and accreditation, but in reality this is seldom, if ever, rigorously done. Combat modelers could also open the underlying theories and data behind their models and simulations for peer review.
The problem is not confined to government-sponsored research and development. In his award-winning 2004 book examining the bases for victory and defeat in battle, Military Power: Explaining Victory and Defeat in Modern Battle, analyst Stephen Biddle noted that the study of military science had been neglected in the academic world as well. “[F]or at least a generation, the study of war’s conduct has fallen between the stools of the institutional structure of modern academia and government,” he wrote.
This state of affairs seems remarkable given the enormous stakes that are being placed on the output of the Defense Department’s modeling and simulation activities. After decades of neglect, remedying this would require a dedicated commitment to sustained basic research on the military science of combat and warfare, with no promise of a tangible short-term return on investment. Yet, as Biddle pointed out, “With so much at stake, we surely must do better.”
[NOTE: The attrition methodologies used in CBS and WARSIM have been corrected since this post was originally published per comments provided by their developers.]

With regard to this statement “Some, such as Joint Theater Level Simulation (JTLS); Corps Battle Simulation (CBS), based on JTLS; and Warfighters’ Simulation (WARSIM) use the Lanchester equations for calculating attrition in ground combat.”, I find, when considering WARSIM, this is a common mistake.
In developing WARSIM we deliberately stayed away from using Lanchester type equations, rather , we did ” adjudicate ground combat using probability of hit/probability of kill (pH/pK) algorithms.”
We used unclassified data, largely from or based on data from AMSA. I occasionally compared our data to historical results, but due to time and staffing limitations, we did not do it for everything.
We had quite a debate with NASA JPL personnel about our approach, mostly from a performance basis.
Calculations were also modified by various factors such as training ratings, time in combat, time without sleep, time without food, etc.
I am not trying to say that these data and factors as used were sufficient for prediction but they did appear good enough for training when tested, verified, and validated by the National Training Center.
Mike,
Thank you for the clarification. It was my understanding that WARSIM uses the Bonder-Farrell method to calculate combat attrition. The Bonder-Farrell differential equations are not the same as Lanchester’s, although B-F is often classified as a Lanchester-type methodology. I stand corrected if this is not accurate and that WARSIM uses pH/pK instead.
Out of curiosity, can you tell me if WARSIM uses pH/pK for both direct and indirect fire adjudication?
Is anyone interested in doing any validation testing of WARSIM?
Cheers,
–Shawn
Hi Shawn,
Thanks for your response.
We considered Bonder-Farrel and it was discussed with the JPL guys. They advocated it on performance grounds, but we were more in favor of a higher fidelity representation of vehicle on vehicle combat.
The role player ordered companies to accomplish tasks (we called these Command Units), which in turn ordered their platoons (equipment groups) to do actions within a particularly behavior. We kept track of the X, Y, Z, and (T)ime of each platform, its damage state, fuel load, ammo load, etc and its crew status.
For some tactical reasoning, I developed firepower scores (because I never could find a paper that explained how the army got their scores) somewhat based on Dupuy’s work, but simpler, based on our data. This would be used by units to decide whether to fight, stop and seek cover, or retreat, bypass, call for fire, etc.
Indirect Fire is adjudicated somewhat differently than Direct Fire. I’m a little hazy on it (Its been a long time and I worked mostly on ADA and DF). As I recall, the fire mission always strikes its target grid (although there may have been some range error) and we overlaid a damage template over the target grid. Platforms caught in the template suffered damage based on the distance from the strike and there was, as I recall but may be mistaken, that there was a probability of no damage.
Weapons were aggregated into bundles based on caliber or explosive fill weight and platforms were aggregated into bundles based on their vulnerability.
Each weapon – platform pairing had separate hit and damage tables that varied with aspect, exposure (fully exposed, hull down, turret down, and hide) movement, and range.
Equipment Groups (usually platoons) placed targets into a shooter list. Targets were characterized as Most Dangerous, Dangerous, and Least Dangerous. Targets were engaged general in the order most dangerous to least dangerous, near to far, slow to fast, low to high, and left to right.
After a hit, there were several types of kill: catastrophic, mobility, firepower, mobility-fire power, communications, sensors (I think), functional (for things like cargo beds, mine plows), etc. These generated the need for repair parts for Direct Support and General Support Maintenance. Two hits equaled a kill, absent a cato.
Air Defense fires were adjudicated based on a base ph and modified for speed, aspect, altitude, and countermeasures.
I have not really seen any papers using WARSIM. It is a constructive training simulation as compared to a analytical or experimental model and is not in very wide use beyond JLCCTC (unlike OneSAF which has been used for a lot of other things).
Mike
Mike,
Thank you for the peek under the hood. It’s always interesting to see details of how the sims and models work.
Cheers,
–Shawn
FYI – the 2017 edition of your blog covering the base of sand issue got a mention in the latest (December 2018) issue of Phalanx: The Magazine of National Security Analysis Page 28 (published by the Military Operations Research Society). An article jointly authored by Jonathan K Alt, Christopher Morey and Larry Larimer entitled “Perspectives on Combat Modelling” cites this blog as evidence that “questions will arise regarding the validity of the combat models and simulations used to support analysis.” However they do not delve into the issue and make no mention of specific problems or particular systems.
This is interesting. You wouldn’t happen to have a copy of the article you could shoot to us, do you?
Yes. I will send an image of the pages. What email address should I send it to?
Thanks.
woodford@dupuyinstitute.org
and
LawrenceTDI@aol.com
I have seen the first page of the article. Pretty interesting. 😉
Thanks for the info.
Of course, you could address the questions about validity by actually validating the models….but that is very rarely actually done.
The Army at least does fairly extensive VV&A of our campaign analytic models. Wr briefed at an unclassified level how we do (and re-do it) at some MORS events in the past few years–basically, we benchmark against historical replication of OIF and we started the practice in 2007.
MORS has held two workshops (the second one a week ago!) on exactly campaign analysis, with something like 2/3rds of the working group tracks essentially focused on these issues. Perhaps you’d find more fruitful engagement in general with these communities if you engaged with their professional society of choice. MORS has a campaign analysis community of practice that is open to non-member participation.
Michael,
Thank you for reaching out. Cost and security classification tend to be barriers to participation at MORS events for a small organization that works exclusively in the unclassified realm. I am sure there would be considerable interest in unclassified presentations on Army combat model validation efforts. TDI is hosting the First Historical Analysis Conference (HAAC) in September in Tyson’s Corner, VA. The cost is only $150 and presenters get a $60 discount. You and any of your colleagues would be very welcome to attend and/or present.
https://dupuyinstitute.dreamhosters.com/2022/03/29/the-first-historical-analysis-annual-conference-haac-27-29-september-2022-in-tysons-corner-va-update-3/
–Shawn Woodford